Transferts Cloud Storage
Le Service de transfert de données BigQuery pour le connecteur Cloud Storage vous permet de programmer des chargements de données récurrents depuis Cloud Storage vers BigQuery.
Avant de commencer
Avant de créer un transfert de données Cloud Storage, procédez comme suit :
- Vérifiez que vous avez effectué toutes les actions requises sur la page Activer le service de transfert de données BigQuery.
- Récupérez votre URI Cloud Storage.
- Créez un ensemble de données BigQuery pour stocker vos données.
- Créez la table de destination pour votre transfert de données et spécifiez la définition du schéma.
- Si vous envisagez de spécifier une clé de chiffrement gérée par le client (CMEK), assurez-vous que votre compte de service est autorisé à procéder au chiffrement et au déchiffrement, et que vous disposez de l'ID de ressource de la clé Cloud KMS requis pour utiliser des clés CMEK. Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la page Spécifier une clé de chiffrement avec des transferts.
Limites
Les transferts de données récurrents de Cloud Storage vers BigQuery sont soumis aux limitations suivantes :
- Tous les fichiers correspondant aux schémas définis par un caractère générique ou par des paramètres d'exécution liés au transfert de données doivent partager le même schéma que celui défini pour la table de destination. Si ce n'est pas le cas, le transfert échoue. Les modifications de schéma de table entre les exécutions entraînent également l'échec du transfert.
- Les objets Cloud Storage peuvent comporter des versions gérées ; il est donc important de noter que les objets Cloud Storage archivés ne sont pas acceptés pour les transferts de données BigQuery. Les objets doivent être publiés pour être transférés.
- Contrairement aux chargements de données individuels de Cloud Storage vers BigQuery, vous devez créer la table de destination avant de configurer le transfert pour les transferts de données en cours. Pour les fichiers CSV et JSON, vous devez également définir le schéma de la table à l'avance. BigQuery ne peut pas créer la table dans le cadre du processus de transfert de données récurrent.
- Les transferts de données depuis Cloud Storage définissent le paramètre Préférence d'écriture sur
APPENDpar défaut. Dans ce mode, un fichier non modifié ne peut être chargé dans BigQuery qu'une seule fois. Si la propriétélast modification timedu fichier est mise à jour, celui-ci est actualisé. Si des fichiers Cloud Storage sont modifiés lors d'un transfert de données, le service de transfert de données BigQuery ne garantit pas que tous les fichiers seront transférés, ou qu'ils ne seront transférés qu'une seule fois. Vous êtes soumis aux limitations suivantes lorsque vous chargez des données dans BigQuery à partir d'un bucket Cloud Storage :
Si l'emplacement de votre ensemble de données est défini sur une valeur autre que l'emplacement multirégional
US, le bucket Cloud Storage doit se trouver dans la même région que l'ensemble de données, ou figurer dans le même emplacement multirégional que celui-ci.BigQuery ne garantit pas la cohérence des données pour les sources de données externes. Les modifications apportées aux données sous-jacentes lors de l'exécution d'une requête peuvent entraîner un comportement inattendu.
BigQuery n'est pas compatible avec la gestion des versions d'objets Cloud Storage. Si vous incluez un numéro de génération dans l'URI Cloud Storage, la tâche de chargement échoue.
Selon le format de vos données sources Cloud Storage, des limitations supplémentaires peuvent s'appliquer. Pour en savoir plus, consultez :
Votre bucket Cloud Storage doit se trouver dans un emplacement compatible avec la région ou l'emplacement multirégional de l'ensemble de données de destination dans BigQuery. C'est ce qu'on appelle la colocation. Pour en savoir plus, consultez les emplacements de données de transfert de Cloud Storage.
Intervalles minimum
- Les fichiers sources sont immédiatement prélevés pour le transfert de données, aucun âge minimal de fichier n'est requis.
- L'intervalle minimum entre deux transferts de données récurrents est de 15 minutes. L'intervalle par défaut entre transferts de données récurrents est de 24 heures.
Autorisations requises
Lorsque vous chargez des données dans BigQuery, vous avez besoin d'autorisations qui vous permettent de charger des données dans des tables et partitions BigQuery nouvelles ou existantes. Si vous chargez des données depuis Cloud Storage, vous devez également avoir accès au bucket contenant vos données. Assurez-vous que vous disposez des autorisations requises suivantes :
BigQuery : assurez-vous que la personne ou le compte de service qui crée le transfert de données dispose des autorisations suivantes dans BigQuery :
- Autorisations
bigquery.transfers.updatepour créer le transfert de données - Autorisations
bigquery.datasets.getetbigquery.datasets.updatesur l'ensemble de données cible
Le rôle IAM prédéfini
bigquery.admininclut les autorisationsbigquery.transfers.update,bigquery.datasets.updateetbigquery.datasets.get. Pour en savoir plus sur les rôles IAM associés au service de transfert de données BigQuery, consultez la page Contrôle des accès.- Autorisations
Cloud Storage : vous devez disposer des autorisations
storage.objects.getau niveau du bucket individuel ou à un niveau supérieur. Si vous utilisez un caractère générique dans l'URI, vous devez également disposer des autorisationsstorage.objects.list. Si vous souhaitez supprimer les fichiers sources après chaque transfert réussi, vous devez également disposer des autorisationsstorage.objects.delete. Le rôle Cloud IAM prédéfinistorage.objectAdmininclut toutes ces autorisations.
Configurer un transfert Cloud Storage
Pour créer un transfert de données Cloud Storage dans le service de transfert de données BigQuery :
Console
Accédez à la page "Transferts de données" dans la console Google Cloud.
Cliquez sur Créer un transfert.
Dans la section Type de source, choisissez Google Cloud Storage comme Source.

Dans la section Transfer config name (Nom de la configuration de transfert), sous Display name (Nom à afficher), saisissez un nom pour le transfert de données, tel que
My Transfer. Ce nom peut correspondre à toute valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement.
Dans la section Schedule options (Options de programmation) :
Sélectionnez une fréquence de répétition. Si vous sélectionnez Heures, Jours, Semaines ou Mois, vous devez également spécifier une fréquence. Vous pouvez également sélectionner Personnalisé pour spécifier une fréquence de répétition personnalisée. Si vous sélectionnez À la demande, ce transfert de données s'exécute lorsque vous déclenchez manuellement le transfert.
Le cas échéant, sélectionnez Commencer ou Commencer à l'heure définie, puis indiquez une date de début et une heure d'exécution.
Dans la section Destination settings (Paramètres de destination), pour le champ Destination dataset (Ensemble de données de destination), choisissez l'ensemble de données que vous avez créé pour stocker vos données.

Dans la section Data source details (Détails de la source de données) :
- Sous Destination table (Table de destination), saisissez le nom de votre table de destination. Le nom de la table de destination doit respecter les règles de dénomination des tables. Les noms de table de destination acceptent également les paramètres.
- Dans le champ Cloud Storage URI (URI Cloud Storage), saisissez l'URI Cloud Storage. Les caractères génériques et les paramètressont acceptés.
- Pour Préférence d'écriture, sélectionnez :
- APPEND pour ajouter de nouvelles données à votre table de destination existante de manière incrémentielle. APPEND est la valeur par défaut pour Préférence d'écriture.
- MIRROR pour écraser les données de la table de destination lors de chaque exécution de transfert de données.
Pour en savoir plus sur la manière dont le service de transfert de données BigQuery ingère des données à l'aide de APPEND ou de MIRROR, consultez la page Ingestion de données pour les transferts Cloud Storage. Pour en savoir plus sur le champ
writeDisposition, consultez la sectionJobConfigurationLoad.- Cochez la case Supprimer les fichiers sources après le transfert si vous souhaitez supprimer les fichiers sources après chaque transfert de données réussi. Les tâches de suppression représentent l'approche conseillée. Notez que les jobs de suppression ne sont pas relancées si la première tentative de suppression des fichiers sources échoue.
Dans la section Transfer Options (Options de transfert) :
- Sous All formats (Tous les formats) :
- Dans le champ Number of errors allowed (Nombre d'erreurs autorisées), saisissez le nombre maximal d'enregistrements incorrects pouvant être ignorés par BigQuery lors de l'exécution de la tâche. Si cette valeur maximale est dépassée, une erreur de type "non valide" est renvoyée dans le résultat de la tâche, et cette dernière échoue. La valeur par défaut est
0. - (Facultatif) Pour les types de cibles décimaux, saisissez une liste de types de données SQL possibles (séparés par des virgules) vers lesquels les valeurs décimales sources peuvent être converties. Le type de données SQL sélectionné pour la conversion dépend des conditions suivantes :
- Le type de données sélectionné pour la conversion sera le premier type de données de la liste suivante qui accepte la précision et l'échelle des données sources, dans cet ordre : NUMERIC, BIGNUMERIC et STRING.
- Si aucun des types de données répertoriés n'accepte la précision et l'échelle, le type de données acceptant la plus large plage parmi la liste spécifiée est sélectionné. Si une valeur dépasse la plage acceptée lors de la lecture des données sources, une erreur est renvoyée.
- Le type de données STRING accepte toutes les valeurs de précision et d'échelle.
- Si ce champ n'est pas renseigné, le type de données est défini par défaut sur "NUMERIC,STRING" pour ORC et "NUMERIC" pour les autres formats de fichiers.
- Ce champ ne peut pas contenir de types de données en double.
- L'ordre dans lequel vous répertoriez les types de données dans ce champ est ignoré.
- Dans le champ Number of errors allowed (Nombre d'erreurs autorisées), saisissez le nombre maximal d'enregistrements incorrects pouvant être ignorés par BigQuery lors de l'exécution de la tâche. Si cette valeur maximale est dépassée, une erreur de type "non valide" est renvoyée dans le résultat de la tâche, et cette dernière échoue. La valeur par défaut est
- Sous JSON, CSV :
- Cochez la case Ignorer les valeurs inconnues si vous souhaitez que les données de transfert ne correspondant pas au schéma de la table de destination ne soient pas prises en compte lors du transfert.
- Sous AVRO :
- Cochez la case Utiliser des types logiques Avro si vous souhaitez que le transfert de données convertisse les types logiques Avro en types de données BigQuery correspondants. Le comportement par défaut consiste à ignorer l'attribut
logicalTypepour la plupart des types et à utiliser à la place le type Avro sous-jacent.
- Cochez la case Utiliser des types logiques Avro si vous souhaitez que le transfert de données convertisse les types logiques Avro en types de données BigQuery correspondants. Le comportement par défaut consiste à ignorer l'attribut
Sous CSV :
- Dans le champ Field delimiter (Délimiteur de champ), saisissez le caractère qui sépare les champs. La valeur par défaut est une virgule.
- Dans le champ Guillemet, saisissez le caractère utilisé pour citer des sections de données dans un fichier CSV. La valeur par défaut est un guillemet double (
"). - Dans le champ Header rows to skip (Lignes d'en-tête à ignorer), saisissez le nombre de lignes d'en-tête contenues dans le ou les fichiers sources si vous ne souhaitez pas importer ces lignes. La valeur par défaut est
0. - Cochez la case Allow quoted newlines (Autoriser les nouvelles lignes entre guillemets) si vous souhaitez autoriser l'ajout de lignes dans les champs entre guillemets.
- Cochez la case Autoriser les lignes irrégulières si vous souhaitez autoriser le transfert de données de lignes dont certaines colonnes
NULLABLEsont manquantes.
- Sous All formats (Tous les formats) :
Dans le menu Compte de service, sélectionnez un compte de service parmi ceux associés à votre projet Google Cloud. Vous pouvez associer un compte de service à votre transfert de données au lieu d'utiliser vos identifiants utilisateur. Pour en savoir plus sur l'utilisation des comptes de service avec des transferts de données, consultez la page Utiliser des comptes de service.
- Si vous vous êtes connecté avec une identité fédérée, vous devez disposer d'un compte de service pour créer un transfert de données. Si vous vous êtes connecté avec un compte Google, un compte de service pour le transfert de données est facultatif.
- Le compte de service doit disposer des autorisations requises pour BigQuery et Cloud Storage.
Facultatif : dans la section Notification options (Options de notification) :
- Cliquez sur le bouton pour activer les notifications par e-mail. Lorsque vous activez cette option, le propriétaire de la configuration de transfert de données reçoit une notification par e-mail en cas d'échec de l'exécution du transfert.
- Pour le champ Select a Pub/Sub topic (Sélectionner un sujet Pub/Sub), choisissez le nom de votre sujet ou cliquez sur Create a topic (Créer un sujet). Cette option configure les notifications d'exécution Pub/Sub pour votre transfert.
(Facultatif) Dans la section Options avancées :
- Si vous utilisezCMEK, sélectionnezClé gérée par le client. La liste des clés CMEK disponibles s'affiche.
Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la page Spécifier une clé de chiffrement avec des transferts.
Cliquez sur Enregistrer.
bq
Saisissez la commande bq mk, puis spécifiez l'indicateur de création de transfert --transfer_config. Les paramètres suivants sont également requis :
--data_source--display_name--target_dataset--params
Indicateurs facultatifs :
--destination_kms_key: spécifie l'ID de ressource de la clé pour la clé Cloud KMS si vous utilisez une clé de chiffrement gérée par le client (CMEK) pour ce transfert de données. Pour en savoir plus sur le fonctionnement des clés CMEK avec le service de transfert de données BigQuery, consultez la page Spécifier une clé de chiffrement avec des transferts.--service_account_name: indique un compte de service à utiliser pour l'authentification du transfert Cloud Storage, au lieu de votre compte utilisateur.
bq mk \ --transfer_config \ --project_id=PROJECT_ID \ --data_source=DATA_SOURCE \ --display_name=NAME \ --target_dataset=DATASET \ --destination_kms_key="DESTINATION_KEY" \ --params='PARAMETERS' \ --service_account_name=SERVICE_ACCOUNT_NAME
Où :
- PROJECT_ID est l'ID de votre projet. Si vous ne fournissez pas de
--project_idafin de spécifier un projet particulier, le projet par défaut est utilisé. - DATA_SOURCE est la source de données, par exemple
google_cloud_storage. - NAME est le nom à afficher pour la configuration du transfert de données. Ce nom peut correspondre à toute valeur permettant d'identifier le transfert si vous devez le modifier ultérieurement.
- DATASET est l'ensemble de données cible de la configuration de transfert.
- DESTINATION_KEY : ID de ressource de clé Cloud KMS (par exemple,
projects/project_name/locations/us/keyRings/key_ring_name/cryptoKeys/key_name). - PARAMETERS contient les paramètres de la configuration de transfert créée au format JSON. Exemple :
--params='{"param":"param_value"}'.destination_table_name_template: nom de la table BigQuery de destination.data_path_template: URI Cloud Storage contenant les fichiers à transférer (ce paramètre peut comporter un caractère générique).write_disposition: détermine si les fichiers correspondants sont ajoutés à la table de destination ou mis en miroir entièrement. Les valeurs compatibles sontAPPENDouMIRROR. Pour en savoir plus sur la manière dont le service de transfert de données BigQuery ajoute ou met en miroir les données dans les transferts Cloud Storage, consultez la page Ingestion de données pour les transferts Cloud Storage.file_format: format des fichiers que vous souhaitez transférer. Le format peut êtreCSV,JSON,AVRO,PARQUETouORC. La valeur par défaut estCSV.max_bad_records: pour toute valeurfile_format, nombre maximal d'enregistrements incorrects pouvant être ignorés. La valeur par défaut est0.decimal_target_types: pour toute valeurfile_format, liste de types de données SQL possibles, séparés par des virgules, vers lesquels les valeurs décimales des données sources peuvent être converties. Si ce champ n'est pas renseigné, le type de données par défaut est"NUMERIC,STRING"pourORC, et"NUMERIC"pour les autres formats de fichiers.ignore_unknown_values: pour toute valeurfile_format, définissez cette valeur surTRUEpour accepter les lignes contenant des valeurs qui ne correspondent pas au schéma. Pour en savoir plus, consultez les explications concernant le champignoreUnknownvalues, dans le tableau de référence de la commandeJobConfigurationLoad.use_avro_logical_types: pour les valeursAVROfile_format, définissez surTRUEpour interpréter les types logiques dans leurs types correspondants (par exemple,TIMESTAMP), au lieu de n'utiliser que leurs types bruts (par exemple,INTEGER).parquet_enum_as_string: pour les valeursPARQUETfile_format, définissez surTRUEpour déduire le type logiquePARQUETENUMen tant queSTRINGau lieu de la valeur par défautBYTES.parquet_enable_list_inference: pour les valeursPARQUETfile_format, définissez la valeur surTRUEpour utiliser l'inférence de schéma spécifiquement pour le type logiquePARQUETLIST.reference_file_schema_uri: chemin d'URI vers un fichier de référence avec le schéma du lecteur.field_delimiter: pour les valeursCSVfile_format, caractère qui sépare les champs. La valeur par défaut est une virgule.quote: pour les valeursCSVfile_format, caractère utilisé pour citer des sections de données dans un fichier CSV. La valeur par défaut est un guillemet double (").skip_leading_rows: pour les valeursCSVfile_format, indiquez le nombre de lignes d'en-tête principales que vous ne souhaitez pas importer. La valeur par défaut est 0.allow_quoted_newlines: pour les valeursCSVfile_format, définissez la valeur surTRUEpour autoriser les nouvelles lignes dans les champs entre guillemets.allow_jagged_rows: pour les valeursCSVfile_format, définissez surTRUEpour accepter les lignes pour lesquelles il manque des colonnes facultatives finales. Les valeurs manquantes sont renseignées avecNULL.preserve_ascii_control_characters: pour les valeursCSVfile_format, définissez surTRUEpour conserver les caractères de contrôle ASCII intégrés.encoding: spécifiez le type d'encodageCSV. Les valeurs acceptées sontUTF8,ISO_8859_1,UTF16BE,UTF16LE,UTF32BEetUTF32LE.delete_source_files: définissez surTRUEpour supprimer les fichiers sources après chaque transfert réussi Les tâches de suppression ne sont pas réexécutées si la première tentative de suppression du fichier source échoue. La valeur par défaut estFALSE.
- SERVICE_ACCOUNT_NAME est le nom du compte de service utilisé pour authentifier le transfert. Le compte de service doit appartenir au même
project_idque celui utilisé pour créer le transfert et doit disposer de toutes les autorisations requises.
Par exemple, la commande suivante crée un transfert de données Cloud Storage nommé My Transfer. La valeur data_path_template est définie pour gs://mybucket/myfile/*.csv, l'ensemble de données cible est nommé mydataset et le type de fichiers file_format est CSV. Cet exemple utilise des valeurs autres que celles par défaut pour les paramètres facultatifs associés au format de fichiers CSV.
Le transfert de données est créé dans le projet par défaut :
bq mk --transfer_config \
--target_dataset=mydataset \
--project_id=myProject \
--display_name='My Transfer' \
--destination_kms_key=projects/myproject/locations/mylocation/keyRings/myRing/cryptoKeys/myKey \
--params='{"data_path_template":"gs://mybucket/myfile/*.csv",
"destination_table_name_template":"MyTable",
"file_format":"CSV",
"max_bad_records":"1",
"ignore_unknown_values":"true",
"field_delimiter":"|",
"quote":";",
"skip_leading_rows":"1",
"allow_quoted_newlines":"true",
"allow_jagged_rows":"false",
"delete_source_files":"true"}' \
--data_source=google_cloud_storage \
--service_account_name=abcdef-test-sa@abcdef-test.iam.gserviceaccount.com projects/862514376110/locations/us/transferConfigs/ 5dd12f26-0000-262f-bc38-089e0820fe38
Après avoir exécuté la commande, vous recevez un message de ce type :
[URL omitted] Please copy and paste the above URL into your web browser and
follow the instructions to retrieve an authentication code.
Suivez les instructions et collez le code d'authentification sur la ligne de commande.
API
Utilisez la méthode projects.locations.transferConfigs.create et fournissez une instance de la ressource TransferConfig.
Java
Avant d'essayer cet exemple, suivez les instructions de configuration pour Java du guide de démarrage rapide de BigQuery : Utiliser les bibliothèques clientes. Pour en savoir plus, consultez la documentation de référence de l'API BigQuery pour Java.
Pour vous authentifier auprès de BigQuery, configurez le service Identifiants par défaut de l'application. Pour en savoir plus, consultez la page Configurer l'authentification pour les bibliothèques clientes.
Spécifier une clé de chiffrement avec les transferts
Vous pouvez spécifier des clés de chiffrement gérées par le client (CMEK) pour chiffrer les données d'une exécution de transfert. Vous pouvez utiliser une clé CMEK pour accepter les transferts provenant de Cloud Storage.Lorsque vous spécifiez une clé CMEK avec un transfert, le service de transfert de données BigQuery l'applique à tous les caches sur disque intermédiaires des données ingérées afin que l'intégralité du workflow de transfert de données soit compatible avec CMEK.
Vous ne pouvez pas mettre à jour un transfert existant pour ajouter une clé CMEK si le transfert n'a pas été initialement créé avec une clé CMEK. Par exemple, vous ne pouvez pas modifier une table de destination initialement chiffrée par défaut pour être chiffrée avec des clés CMEK. À l'inverse, vous ne pouvez pas modifier une table de destination chiffrée par CMEK pour obtenir un type de chiffrement différent.
Vous pouvez mettre à jour une clé CMEK pour un transfert si la configuration de celui-ci a été initialement créée avec un chiffrement CMEK. Lorsque vous mettez à jour une clé CMEK pour une configuration de transfert, le service de transfert de données BigQuery propage cette clé aux tables de destination à la prochaine exécution du transfert, où le service de transfert de données BigQuery remplace toutes les clés CMEK obsolètes par la nouvelle clé lors de l'exécution du transfert. Pour en savoir plus, consultez Mettre à jour un transfert.
Vous pouvez également utiliser les clés par défaut d'un projet. Lorsque vous spécifiez une clé de projet par défaut avec un transfert, le service de transfert de données BigQuery utilise cette clé pour toutes les nouvelles configurations de transfert.
Déclencher un transfert manuellement
Outre les transferts de données programmés automatiquement depuis Cloud Storage, vous pouvez déclencher manuellement un transfert pour charger des fichiers de données supplémentaires.
Si la configuration du transfert est paramétrée au moment de l'exécution, vous devez spécifier une plage de dates pour laquelle des transferts supplémentaires seront démarrés.
Pour déclencher un transfert de données, procédez comme suit :
Console
Accédez à la page "BigQuery" de la console Google Cloud.
Cliquez sur Transferts de données.
Sélectionnez votre transfert de données dans la liste.
Cliquez sur Exécuter le transfert maintenant ou Programmer le remplissage (pour les configurations de transfert paramétrées au moment de l'exécution).
Si vous avez cliqué sur Exécuter le transfert maintenant, sélectionnez Exécuter un transfert ponctuel ou Exécuter pour une date spécifique, selon le cas. Si vous avez choisi Exécuter pour une date spécifique, sélectionnez une date et une heure spécifiques :
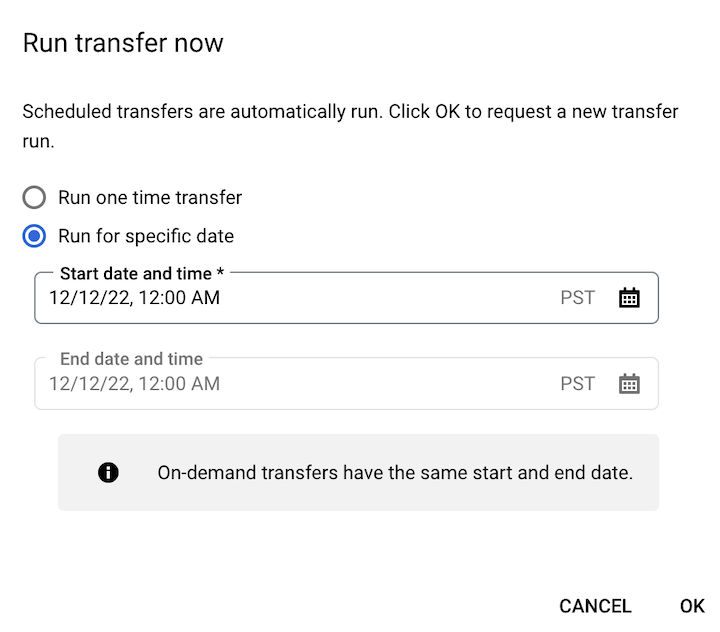
Si vous avez cliqué sur Programmer le remplissage, sélectionnez Exécuter un transfert ponctuel ou Exécuter pour une plage de dates, selon le cas. Si vous avez choisi Exécuter pour une plage de dates, sélectionnez une date de début et une date de fin :
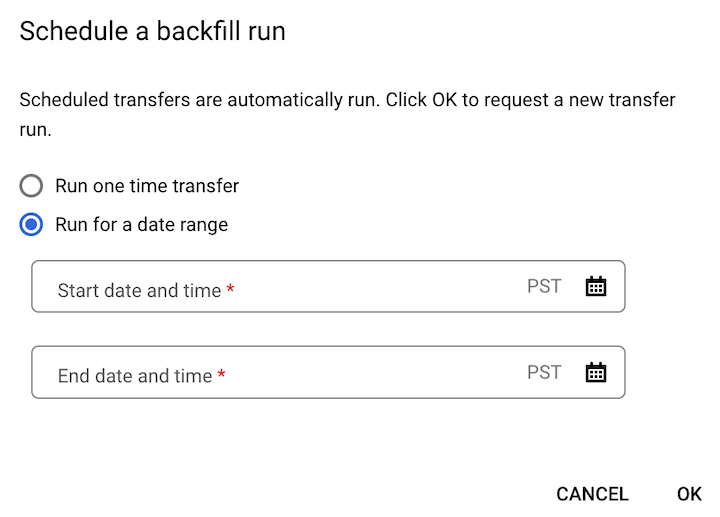
Cliquez sur OK.
bq
Saisissez la commande bq mk, puis spécifiez l'option --transfer_run. Vous pouvez utiliser l'option --run_time ou les options --start_time et --end_time.
bq mk \ --transfer_run \ --start_time='START_TIME' \ --end_time='END_TIME' \ RESOURCE_NAME
bq mk \ --transfer_run \ --run_time='RUN_TIME' \ RESOURCE_NAME
Où :
START_TIME et END_TIME sont des codes temporels qui finissent par
Z, ou ils contiennent un décalage de fuseau horaire valide. Exemple :2017-08-19T12:11:35.00Z2017-05-25T00:00:00+00:00
RUN_TIME est un code temporel qui spécifie l'heure de planification de l'exécution du transfert de données. Si vous souhaitez exécuter un transfert ponctuel pour l'heure actuelle, vous pouvez utiliser l'option
--run_time.RESOURCE_NAME est le nom de ressource du transfert (également appelé "configuration de transfert"), par exemple
projects/myproject/locations/us/transferConfigs/1234a123-1234-1a23-1be9-12ab3c456de7. Si vous ne connaissez pas le nom de ressource du transfert, exécutez la commandebq ls --transfer_config --transfer_location=LOCATIONpour le trouver.
API
Utilisez la méthode projects.locations.transferConfigs.startManualRuns et indiquez la ressource de configuration de transfert à l'aide du paramètre parent.
Étapes suivantes
- Découvrez les paramètres d'exécution dans les transferts Cloud Storage.
- Obtenez plus d'informations sur le Service de transfert de données BigQuery.