AWS Big Data Blog
Category: Experience-Based Acceleration

How EchoStar ingests terabytes of data daily across its 5G Open RAN network in near real-time using Amazon Redshift Serverless Streaming Ingestion
EchoStar, a connectivity company providing television entertainment, wireless communications, and award-winning technology to residential and business customers throughout the US, deployed the first standalone, cloud-native Open RAN 5G network on AWS public cloud. This post provides an overview of real-time data analysis with Amazon Redshift and how EchoStar uses it to ingest hundreds of megabytes per second. As data sources and volumes grew across its network, EchoStar migrated from a single Redshift Serverless workgroup to a multi-warehouse architecture with live data sharing.

Implement a full stack serverless search application using AWS Amplify, Amazon Cognito, Amazon API Gateway, AWS Lambda, and Amazon OpenSearch Serverless
Designing a full stack search application requires addressing numerous challenges to provide a smooth and effective user experience. This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability. Amazon OpenSearch Serverless […]
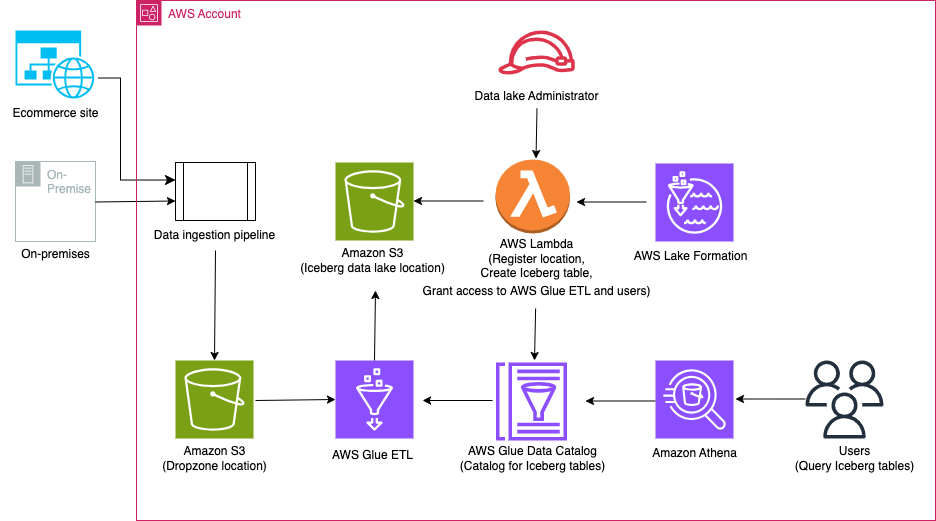
Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. However, altering schema and table partitions in traditional data lakes can be a disruptive and time-consuming task, requiring renaming or recreating entire tables and reprocessing large datasets. […]