AWS Machine Learning Blog
Category: Compute

Accelerate your generative AI distributed training workloads with the NVIDIA NeMo Framework on Amazon EKS
In today’s rapidly evolving landscape of artificial intelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Without a structured framework, the process can become prohibitively time-consuming, costly, and complex. Enterprises struggle with managing […]

Accelerated PyTorch inference with torch.compile on AWS Graviton processors
Originally PyTorch used an eager mode where each PyTorch operation that forms the model is run independently as soon as it’s reached. PyTorch 2.0 introduced torch.compile to speed up PyTorch code over the default eager mode. In contrast to eager mode, the torch.compile pre-compiles the entire model into a single graph in a manner that’s optimal for […]

Create an end-to-end serverless digital assistant for semantic search with Amazon Bedrock
With the rise of generative artificial intelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources. As organizations transition from proofs of concept to production workloads, they establish objectives to run and scale their workloads with minimal operational […]

Scale and simplify ML workload monitoring on Amazon EKS with AWS Neuron Monitor container
Amazon Web Services is excited to announce the launch of the AWS Neuron Monitor container, an innovative tool designed to enhance the monitoring capabilities of AWS Inferentia and AWS Trainium chips on Amazon Elastic Kubernetes Service (Amazon EKS). This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to […]

Connect to Amazon services using AWS PrivateLink in Amazon SageMaker
In this post, we present a solution for configuring SageMaker notebook instances to connect to Amazon Bedrock and other AWS services with the use of AWS PrivateLink and Amazon Elastic Compute Cloud (Amazon EC2) security groups.

Deploy a Slack gateway for Amazon Bedrock
In today’s fast-paced digital world, streamlining workflows and boosting productivity are paramount. That’s why we’re thrilled to share an exciting integration that will take your team’s collaboration to new heights. Get ready to unlock the power of generative artificial intelligence (AI) and bring it directly into your Slack workspace. Imagine the possibilities: Quick and efficient […]

Accelerate deep learning training and simplify orchestration with AWS Trainium and AWS Batch
In large language model (LLM) training, effective orchestration and compute resource management poses a significant challenge. Automation of resource provisioning, scaling, and workflow management is vital for optimizing resource usage and streamlining complex workflows, thereby achieving efficient deep learning training processes. Simplified orchestration enables researchers and practitioners to focus more on model experimentation, hyperparameter tuning, […]

Scalable intelligent document processing using Amazon Bedrock
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. However, traditional document processing workflows often involve complex and time-consuming manual tasks, hindering productivity and scalability. In this post, we discuss an approach that uses the […]

Get started quickly with AWS Trainium and AWS Inferentia using AWS Neuron DLAMI and AWS Neuron DLC
Starting with the AWS Neuron 2.18 release, you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. When a Neuron SDK is released, you’ll now be notified of the support for Neuron DLAMIs […]
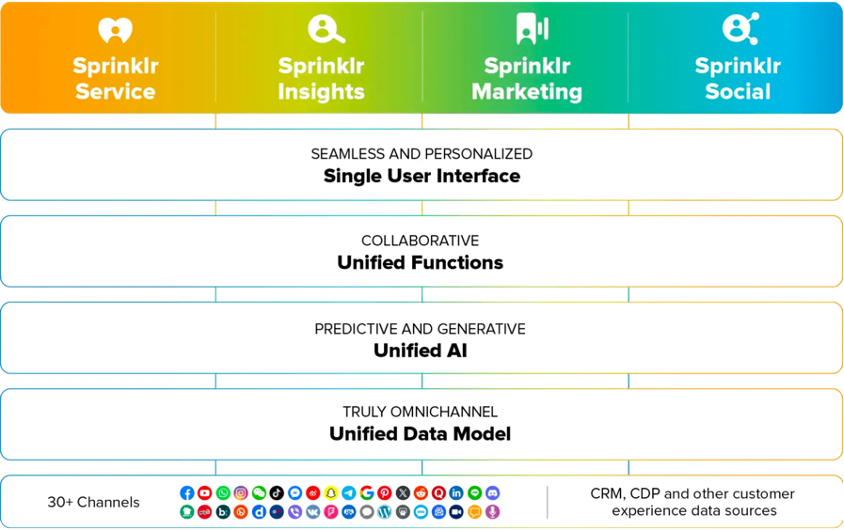
Sprinklr improves performance by 20% and reduces cost by 25% for machine learning inference on AWS Graviton3
This is a guest post co-written with Ratnesh Jamidar and Vinayak Trivedi from Sprinklr. Sprinklr’s mission is to unify silos, technology, and teams across large, complex companies. To achieve this, we provide four product suites, Sprinklr Service, Sprinklr Insights, Sprinklr Marketing, and Sprinklr Social, as well as several self-serve offerings. Each of these products are […]