Spanner Data Boost 是一项全代管式无服务器服务,可为受支持的 Spanner 工作负载提供独立的计算资源。Data Boost 使您可以执行分析查询和数据导出,且对预配的 Spanner 实例上的现有工作负载几乎没有影响。该服务由 Google 在区域级别管理的 Spanner 集群组成。对于请求 Data Boost 的符合条件的查询,Spanner 会以透明的方式将工作负载路由到这些服务器。符合条件的查询是指查询执行计划中的第一个运算符为分布式联合的查询。无需更改这些查询即可使用 Data Boost。
在以下情况下,您需要避免因资源争用对现有事务系统造成负面影响,Data Boost 最有效:
- 涉及处理大量数据的临时或不频繁查询。 从 BigQuery 到 Spanner 的联合查询是一个典型的示例。
- 报告或数据导出作业。例如,用于将 Spanner 数据导出到 Cloud Storage 的 Dataflow 作业。
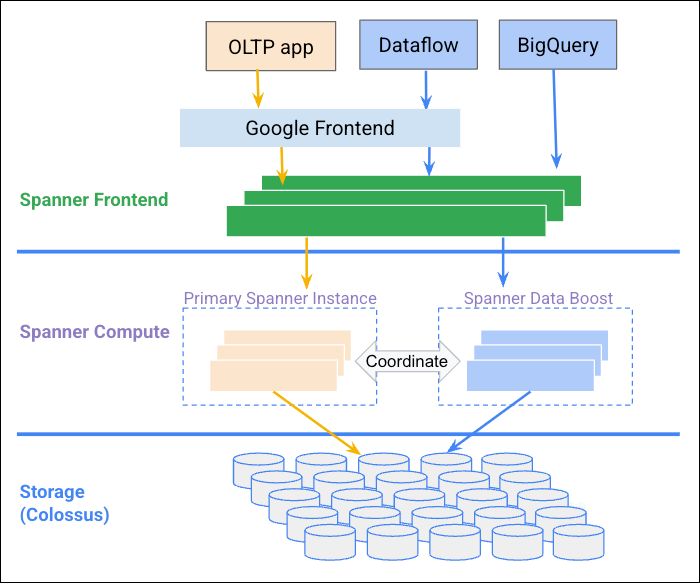
下图说明了 Data Boost 如何与 Spanner 实例协调以提供独立的计算资源。
优势
Data Boost 具有以下优势:
- 提供工作负载隔离。无论查询复杂程度或处理的数据量如何,您都可以针对最新数据运行受支持的查询,而对现有事务工作负载的影响几乎为零。
- 提供相同或更短的延迟时间。
- 防止为支持偶尔的分析查询而过度预配 Spanner 实例。
- 提供高度的可伸缩性,更高的查询并行性,能够随突发负载而弹性扩缩。
- 提供全面的指标,便于管理员确定费用最高的查询并确定要优化的费用组成部分。然后,管理员可以在下次执行查询时监控该查询的无服务器处理单元使用情况,以验证优化措施的影响。
- 无需额外的运营开销。您无需管理额外的服务,无需进行容量规划或预配,无需等待伸缩,也无需进行维护。
权限
运行请求 Data Boost 的查询或导出的任何主帐号都必须具有 spanner.databases.useDataBoost Identity and Access Management (IAM) 权限。我们建议您根据 Cloud Spanner Database Reader (roles/spanner.databaseReader) 创建自定义 IAM 角色,并将 spanner.databases.useDataBoost 添加到该角色中。
结算和配额
您只需为在 Data Boost 上运行的查询实际使用的处理单元付费。管理员可以设置用量限额,以避免费用超支。