Esta página contiene términos del glosario de bosques de decisión. Para todos los términos del glosario, haz clic aquí.
A
muestreo de atributos
Una táctica para entrenar un bosque de decisiones en el que cada El árbol de decisión considera solo un subconjunto aleatorio de posibles features cuando aprendes la condición. En general, se muestrea un subconjunto diferente de atributos para cada nodo. En cambio, cuando se entrena un árbol de decisiones sin el muestreo de atributos, se consideran todos los atributos posibles para cada nodo.
condición de alineación al eje
En un árbol de decisión, una condición que incluye un solo atributo. Por ejemplo, si el área es un atributo, la siguiente es una condición alineada con los ejes:
area > 200
Compara esto con la condición oblicua.
B
embolsado
Un método para entrenar un ensamble, en el que cada el modelo constituyente se entrena en un subconjunto aleatorio de entrenamiento ejemplos muestreados con reemplazo. Por ejemplo, un bosque aleatorio es una colección árboles de decisión entrenados con el empaquetado.
El término bagging es la forma abreviada en inglés de sootstrap aggreinging.
condición binaria
En un árbol de decisión, una condición que solo tiene dos resultados posibles, que suele ser sí o no. Por ejemplo, la siguiente es una condición binaria:
temperature >= 100
Compara esto con la condición no binaria.
C
de transición
En un árbol de decisión, cualquier nodo que evalúa una expresión. Por ejemplo, la siguiente parte de una el árbol de decisión contiene dos condiciones:

Una condición también se denomina división o prueba.
Contrasta la condición con la hoja.
Consulta lo siguiente:
D
bosque de decisión
Un modelo creado a partir de varios árboles de decisión. Un bosque de decisiones hace una predicción mediante la agregación de las predicciones de sus árboles de decisiones. Los tipos populares de bosques de decisión incluyen bosques aleatorios y árboles con boosting del gradiente.
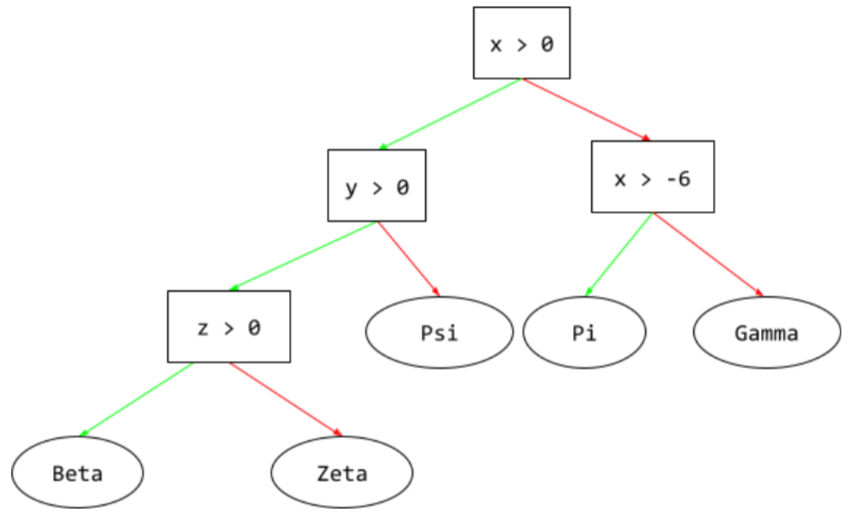
árbol de decisión
Es un modelo de aprendizaje supervisado compuesto por un conjunto de conditions y leafs organizados de forma jerárquica. Por ejemplo, a continuación, se muestra un árbol de decisiones:
E
entropía
En teoría de la información, es una descripción de qué tan impredecible que puede ser una probabilidad distribución. Por otro lado, la entropía también se define como información que contiene cada ejemplo. Una distribución tiene la entropía más alta posible cuando todos los valores de una variable aleatoria igualmente probable.
Entropía de un conjunto con dos valores posibles: “0” y "1" (por ejemplo, las etiquetas en un problema de clasificación binaria) tiene la siguiente fórmula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
Donde:
- H es la entropía.
- p es la fracción de "1" ejemplos.
- q es la fracción de "0" ejemplos. Observa que q = (1 - p)
- log generalmente es log2. En este caso, la entropía unidad es un poco.
Por ejemplo, supongamos lo siguiente:
- 100 ejemplos contienen el valor “1”
- 300 ejemplos contienen el valor “0”
Por lo tanto, el valor de la entropía es el siguiente:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 bits por ejemplo
Un conjunto perfectamente equilibrado (por ejemplo, 200 “0” y 200 “1”) tendría una entropía de 1.0 bits por ejemplo. A medida que un conjunto se vuelve más desequilibrado, su entropía se acerca a 0.0.
En los árboles de decisión, la entropía ayuda a formular la obtención de información para ayudar al splitter selecciona las condiciones. durante el crecimiento de un árbol de decisiones de clasificación.
Compara la entropía con lo siguiente:
- impureza de gini
- Función de pérdida de entropía cruzada
La entropía suele llamarse entropía de Shannon.
F
importancias de atributos
Sinónimo de importancias de variable.
G
impureza de gini
Una métrica similar a la entropía. Divisores usan valores derivados de impureza de gini o entropía para componer conditions para la clasificación árboles de decisión. El aumento de la información se deriva de la entropía. No existe un término equivalente universalmente aceptado para la métrica derivada de la impureza del gini; Sin embargo, esta métrica sin nombre es tan importante como de información.
La impureza de Gini también se denomina índice de gini o simplemente gini.
Árboles de gradiente (decisión) potenciados (GBT)
Un tipo de bosque de decisión en el que:
- El entrenamiento se basa en potenciación de gradiente.
- El modelo débil es un árbol de decisión.
potenciación de gradiente
Algoritmo de entrenamiento en el que los modelos débiles se entrenan de forma iterativa mejorar la calidad (reducir la pérdida) de un modelo sólido. Por ejemplo: un modelo débil podría ser uno lineal o un modelo de árbol de decisión pequeño. El modelo sólido se convierte en la suma de todos los modelos débiles previamente entrenados.
En la forma más simple de boosting de gradiente, en cada iteración, un modelo débil se entrena para predecir la pérdida del modelo sólido. Luego, la de un modelo sólido se actualiza restando el gradiente predicho, de manera similar al descenso de gradientes.
Donde:
- $F_{0}$ es el modelo fuerte inicial.
- $F_{i+1}$ es el próximo modelo fuerte.
- $F_{i}$ es el modelo fuerte actual.
- $\xi$ es un valor entre 0.0 y 1.0 llamado reducción. que es similar al tasa de aprendizaje en el descenso de gradientes.
- $f_{i}$ es el modelo débil entrenado para predecir el gradiente de pérdida de $F_{i}$
Las variaciones modernas del boosting de gradiente también incluyen la segunda derivada (hessiano) de la pérdida en su cálculo.
Los árboles de decisión suelen usarse como modelos débiles en potenciador de gradiente. Consulta árboles con boosting del gradiente (decisión).
I
ruta de inferencia
En un árbol de decisión, durante la inferencia, la ruta que toma un ejemplo en particular desde la root para otras condiciones, que termina con una hoja. Por ejemplo, en el siguiente árbol de decisiones, el las flechas gruesas muestran la ruta de inferencia de un ejemplo con el siguiente atributos con los valores de atributos:
- x = 7
- y = 12
- z = -3
La ruta de inferencia en la siguiente ilustración recorre tres
condiciones antes de llegar a la hoja (Zeta).

Las tres flechas gruesas muestran la ruta de inferencia.
aumento de información
En los bosques de decisión, la diferencia entre la entropía de un nodo y la ponderada (por número de ejemplos) de la entropía de sus nodos secundarios. La entropía de un nodo es la entropía de los ejemplos en ese nodo.
Por ejemplo, considera los siguientes valores de entropía:
- entropía del nodo superior = 0.6
- entropía de un nodo secundario con 16 ejemplos relevantes = 0.2
- entropía de otro nodo secundario con 24 ejemplos relevantes = 0.1
Así que el 40% de los ejemplos están en un nodo secundario y el 60% otro nodo secundario. Por lo tanto:
- Suma de entropía ponderada de nodos secundarios = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
Entonces, la ganancia de información es la siguiente:
- ganancia de información = entropía del nodo superior - suma de entropía ponderada de nodos secundarios
- ganancia de información = 0.6 - 0.14 = 0.46
La mayoría de los divisores buscan crear condiciones. que maximizan el aumento de la información.
condición en la configuración
En un árbol de decisión, una condición que comprueba la presencia de un elemento en un conjunto de elementos. Por ejemplo, la siguiente es una condición establecida:
house-style in [tudor, colonial, cape]
Durante la inferencia, si el valor del atributo de estilo de casa
es tudor, colonial o cape, entonces, esta condición se evalúa como Sí. Si
el valor del atributo de estilo de la casa es otra cosa (por ejemplo, ranch).
esta condición se evalúa como No.
Las condiciones establecidas suelen generar árboles de decisión más eficientes que condiciones que prueban funciones de codificación one-hot.
L
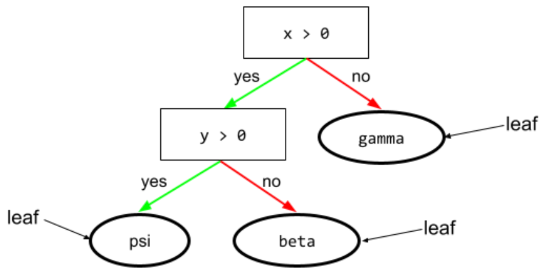
hoja
Cualquier extremo en un árbol de decisión. No te gusta un condition, una hoja no realiza ninguna prueba. Más bien, una hoja es una predicción posible. Una hoja también es la terminal. nodo de una ruta de inferencia.
Por ejemplo, el siguiente árbol de decisión contiene tres hojas:
N
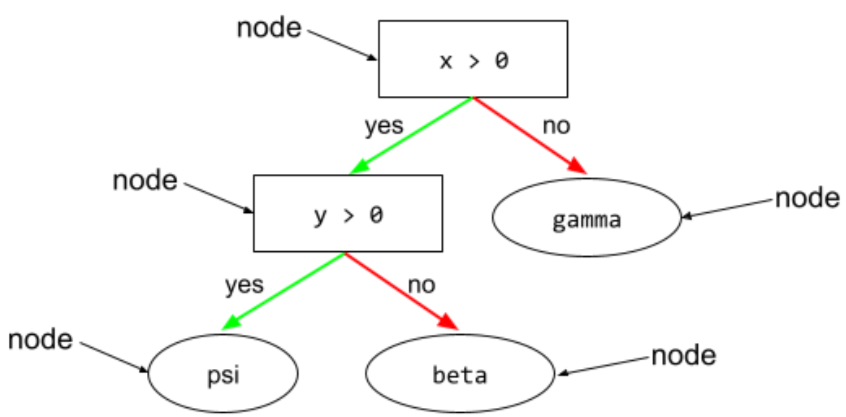
nodo (árbol de decisión)
En un árbol de decisión, cualquier condition o la hoja.
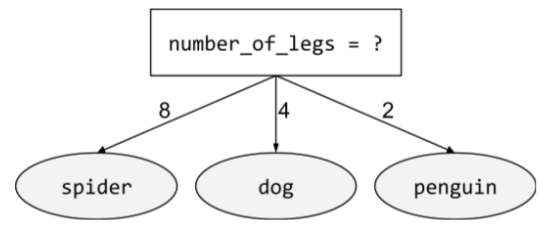
condición no binaria
Es una condición que contiene más de dos resultados posibles. Por ejemplo, la siguiente condición no binaria contiene tres resultados:
O
condición oblicua
En un árbol de decisión, se condición que involucra a más de un feature. Por ejemplo, si la altura y el ancho son ambos atributos, entonces la siguiente es una condición oblicua:
height > width
Compara esto con la condición alineada al eje.
evaluación fuera de bolsa (evaluación OOB)
Un mecanismo para evaluar la calidad de un bosque de decisión probando cada árbol de decisión con respecto al ejemplos que no se usaron durante el entrenamiento de ese árbol de decisión. Por ejemplo, en la del siguiente diagrama, observa que el sistema entrena cada árbol de decisión en aproximadamente dos tercios de los ejemplos y luego compara restante en un tercio de los ejemplos.
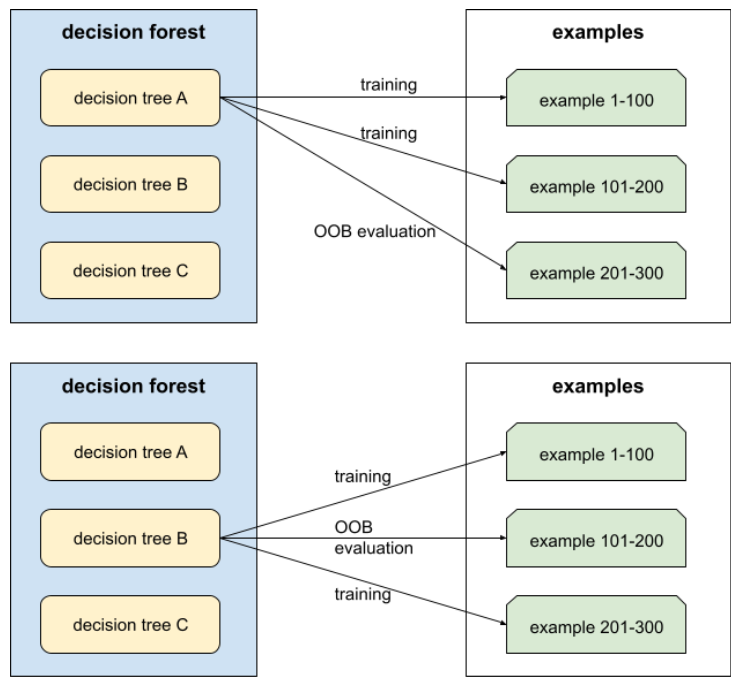
La evaluación fuera de lo común es una solución eficiente y conservadora desde el punto de vista informático una aproximación del mecanismo de validación cruzada. En la validación cruzada, se entrena un modelo para cada ronda de validación cruzada. (por ejemplo, se entrenan 10 modelos en una validación cruzada de 10 veces). Con la evaluación OOB, se entrena un solo modelo. Porque los bolsos retiene algunos datos de cada árbol durante el entrenamiento, la evaluación OOB puede usar esos datos para aproximar la validación cruzada.
P
importancias de las variables de permutación
Un tipo de importancia variable que evalúa el aumento en el error de predicción de un modelo después de permutar los valores del atributo. La importancia de las variables de permutación es un modelo métrica
R
bosque aleatorio
Un ensamble de árboles de decisión en que se entrena con un ruido aleatorio específico, como bolso.
Los bosques aleatorios son un tipo de bosque de decisión.
raíz
El nodo inicial (el primer condition) en un árbol de decisión. Por convención, los diagramas colocan la raíz en la parte superior del árbol de decisiones. Por ejemplo:

S
muestreo con reemplazo
un método de selección de elementos de un conjunto de elementos candidatos en el que se el artículo se puede elegir varias veces. La frase "con reemplazo" significa que, después de cada selección, el elemento seleccionado se devuelve al grupo de elementos candidatos. El método inverso, muestreo sin reemplazo, significa que un elemento candidato solo se puede elegir una vez.
Por ejemplo, considera el siguiente conjunto de frutas:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Supongamos que el sistema elige al azar fig como el primer elemento.
Si usas el muestreo con reemplazo, el sistema elige la
segundo elemento del siguiente conjunto:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Sí, es el mismo conjunto que antes, por lo que el sistema podría
elige fig de nuevo.
Si usas el muestreo sin reemplazo, una vez que se selecciona, no se puede
se eligió de nuevo. Por ejemplo, si el sistema elige al azar fig como
primera muestra, no se podrá volver a elegir fig. Por lo tanto, el sistema
selecciona la segunda muestra del siguiente conjunto (reducido):
fruit = {kiwi, apple, pear, cherry, lime, mango}
reducción
Un hiperparámetro en potenciación de gradiente que controla sobreajuste. Contracción en el boosting del gradiente es análogo a la tasa de aprendizaje en descenso de gradientes. La reducción es un decimal entre 0.0 y 1.0. Un valor de reducción más bajo reduce el sobreajuste superior a un valor de reducción mayor.
split
En un árbol de decisión, otro nombre para una condition [estado].
separador
Mientras se entrena un árbol de decisión, la rutina (y algoritmo) responsables de encontrar la mejor condition en cada nodo.
T
prueba
En un árbol de decisión, otro nombre para una condition [estado].
umbral (para árboles de decisión)
En una condición alineada al eje, el valor al que función con la que se compara. Por ejemplo, 75 es el umbral en la siguiente condición:
grade >= 75
V
importancias variables
Un conjunto de puntuaciones que indica la importancia relativa de cada una atributo al modelo.
Por ejemplo, considera un árbol de decisión que estima el precio de las casas. Supongamos que este árbol de decisión usa tres características: tamaño, edad y estilo. Si un conjunto de importancias variables de las tres funciones están calculadas para {size=5.8, age=2.5, style=4.7}, entonces el tamaño es más importante para árbol de decisión que la edad o el estilo.
Existen diferentes métricas de importancia variable expertos en AA sobre diferentes aspectos de los modelos.
W
la sabiduría de la multitud
La idea de que promediar las opiniones o estimaciones de un grupo grande de personas ("la multitud") a menudo produce resultados sorprendentemente buenos. Por ejemplo, considera un juego en el que las personas adivinan el número de gomitas en un gran frasco. Aunque la mayoría de suposiciones serán inexactas, el promedio de todas ellas ha sido se muestra empíricamente como algo cercano al número real gomitas en el frasco.
Los conjuntos son un software análogo de la sabiduría de la multitud. Incluso si los modelos individuales realizan predicciones extremadamente inexactas, promediar las predicciones de muchos modelos suele generar predicciones correctas. Por ejemplo, aunque un individuo árbol de decisión puede hacer predicciones deficientes, un El bosque de decisiones a menudo realiza muy buenas predicciones.