このページには、デシジョン フォレストの用語集が含まれています。すべての用語集で こちらをクリックしてください。
A
属性サンプリング
ディシジョン フォレストをトレーニングする戦術では、 ディシジョン ツリーでは、候補のうち、 特徴(条件を学習する場合) 通常、特徴のサブセットは、モデルごとに node。一方、ディシジョン ツリーをトレーニングする場合は、 属性サンプリングを使用しない場合、ノードごとに考えられるすべての特徴が考慮されます。
軸に揃えられた条件
ディシジョン ツリーの条件 単一の特徴のみを含むもの。たとえば、 が特徴の場合、以下は軸に揃えられた条件です。
area > 200
「傾斜条件」も参照してください。
B
バギング
アンサンブルをトレーニングするためのメソッドで、 構成要素のモデルが、トレーニングのランダムなサブセットでトレーニングされる 置換でサンプリングされた例。 たとえば、ランダム フォレストは、 バギングでトレーニングされたディシジョン ツリー。
バギングという用語は、ブートストラップ アグリゲーションの短縮形です。
バイナリ条件
ディシジョン ツリーの条件 通常は「はい」か「いいえ」の 2 つしかありません。 たとえば、バイナリ条件は次のとおりです。
temperature >= 100
「ノンバイナリー条件」は、
C
商品の状態(condition)
ディシジョン ツリーで、対象となるノード 式を評価します。たとえば、インフラストラクチャの ディシジョン ツリーには次の 2 つの条件があります。

条件はスプリットまたはテストとも呼ばれます。
関連項目:
D
デシジョン フォレスト
複数のディシジョン ツリーから作成されたモデル。 デシジョン フォレストは、さまざまな予測を集約して 決定します一般的なタイプのデシジョン フォレストには、 ランダム フォレストと勾配ブースティング ツリー。
ディシジョン ツリー
教師あり学習モデルは、1 対 1 または 2 の 条件と残を階層的に整理できます。 たとえば、次の図はディシジョン ツリーです。

E
エントロピー
イン <ph type="x-smartling-placeholder"></ph> 情報理論 ある確率がどれだけ予測不能か、 説明しますまた、エントロピーは、生成する出力が 各例に含まれる情報。ディストリビューションには 確率変数のすべての値が 可能性があります。
取り得る 2 つの値「0」を持つ集合のエントロピーと「1」(例: バイナリ分類問題のラベル) 次の式になります。
<ph type="x-smartling-placeholder"></ph> H = -p log p - q log q = -p log p - (1-p) * log (1-p)
ここで
- H はエントロピーです。
- p は「1」の分数説明します。
- q は「0」の分数説明します。q = (1 - p) であることに注意してください。
- log は通常 log2 です。この場合 エントロピーは 単位です。
たとえば、次のように仮定します。
- 100 個の例に値「1」が含まれています
- 300 個の例に値「0」が含まれています
したがって、エントロピー値は次のようになります。
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 ビット/例
完全にバランスの取れた集合(例: 「0」が 200 個と「1」が 200 個) エントロピーは例あたり 1.0 ビットですセットが 不均衡の場合、エントロピーは 0.0 に向かって動きます。
ディシジョン ツリーでは、エントロピーによって 情報利得に協力して [スプリッター] で条件を選択します 重要な役割を果たします
エントロピーを次と比較:
エントロピーはよくシャノンのエントロピーと呼ばれます。
F
特徴の重要度
変数の重要度と同義。
G
ジニ不純物
エントロピーに似た指標。スプリッター ギニ不純度またはエントロピーから導出された値を使用して 分類用の条件 ディシジョン ツリー。 情報利得はエントロピーから導出されます。 算出される指標と同等の意味で普遍的に認められている用語はない 不純物から抽出されます。この名前のない指標は 情報利得
ジニ不純度は、ギニ指数(または単にギニ)とも呼ばれます。
勾配ブースト(決定)ツリー(GBT)
ディシジョン フォレストの一種で、次のような特徴があります。
- トレーニングは 勾配ブースティング。
- 弱いモデルがディシジョン ツリーです。
グラデーション ブースト
弱いモデルが繰り返しトレーニングされるトレーニング アルゴリズム 強力なモデルの品質を改善(損失を低減)します。たとえば 線形モデルまたは小さなディシジョン ツリー モデルが弱いモデルになります。 強力なモデルは、以前にトレーニングされた弱いモデルをすべて合計した値になります。
最も単純な形式の勾配ブースティングでは、反復処理のたびに弱いモデルが 強モデルの損失勾配を予測するようにトレーニングされます。次に、 強いモデルの出力は、予測された勾配を引いて更新され、 勾配降下法と似ています。
ここで
- $F_{0}$ が開始のストロング モデルです。
- $F_{i+1}$ が次に強力なモデルです。
- $F_{i}$ は現在、強力なモデルです。
- $\xi$ は 0.0 ~ 1.0 の値で、収縮と呼ばれます。 これは UDM イベントに 学習率: 勾配降下法の一種です。
- $f_{i}$ は、モデルの損失勾配を予測するようにトレーニングされた弱いモデルです。 $F_{i}$。
勾配ブースティングの最新のバリエーションには、二次微分係数も (Hessian)です。
ディシジョン ツリーは、 調整することもできます詳しくは、 勾配ブースト(決定)ツリー。
I
推論パス
ディシジョン ツリーで推論を行う際、 特定の例が root を他の条件に追加し、 リーフ。たとえば、次のディシジョン ツリーでは、 太い矢印は、次のサンプルの推論パスを示しています。 特徴値:
- x = 7
- y = 12
- z = -3
次の図の推論パスは、3 つの
条件が満たされていることを表します(Zeta)。

3 つの太い矢印は、推論パスを示しています。
情報利得
デシジョン フォレストでは、 ノードのエントロピーと重み付け(サンプル数による) その子ノードのエントロピーの和です。ノードのエントロピーとは、ノードの 表示されます。
たとえば、次のエントロピー値について考えてみましょう。
- 親ノードのエントロピー = 0.6
- 関連する 16 個のサンプルを持つ 1 つの子ノードのエントロピー = 0.2
- 関連する 24 個のサンプルを持つ別の子ノードのエントロピー = 0.1
つまり、サンプルの 40% が 1 つの子ノードに、60% が 子ノードを指定します。そのため、次のようになります。
- 子ノードの加重エントロピー合計 = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
したがって、情報取得は次のように行われます。
- 情報ゲイン = 親ノードのエントロピー - 子ノードの加重エントロピー合計
- 情報ゲイン = 0.6 - 0.14 = 0.46
ほとんどのスプリッターは条件の作成を試みます。 情報を最大限に得るためのシステムです。
セット内の条件
ディシジョン ツリーの条件 一連のアイテム内に 1 つのアイテムが存在するかどうかをテストします。 たとえば、インセット条件の例を次に示します。
house-style in [tudor, colonial, cape]
推論中に、家スタイルの特徴の値が
tudor、colonial、cape のいずれかである場合、この条件は Yes と評価されます。条件
家スタイルの対象物の値が上記以外の値(例: ranch)である。
この条件は No と評価されます
セット内の条件は通常よりも効果的なディシジョン ツリーを ワンホット エンコード機能をテストする条件。
L
葉
ディシジョン ツリー内のエンドポイント。YouTube の condition の場合、リーフはテストを行いません。 むしろ、リーフは可能性のある予測です。リーフは終端でもある 推論パスのノード。
たとえば、次のディシジョン ツリーには 3 つのリーフが含まれています。

N
ノード(ディシジョン ツリー)
ディシジョン ツリーでは、 condition または leaf。
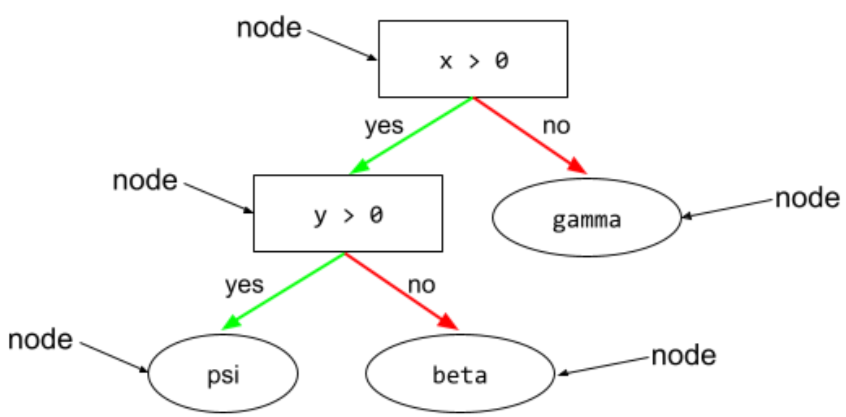
ノンバイナリー状態
3 つ以上の結果を含む条件。 たとえば、次のノンバイナリー条件には、可能性のある 3 つの条件が含まれます。 成果:

O
傾斜条件
ディシジョン ツリーでは、 複数の関係を含む条件 feature:たとえば高さと幅が両方とも特徴量の場合 傾斜条件は次のとおりです。
height > width
「軸揃えの条件」も参照してください。
out-of-bag 評価(OOB 評価)
サービスの品質を評価するメカニズムは、 ディシジョン フォレスト ディシジョン ツリー 使用されない例 そのディシジョン ツリーのトレーニングを行います。たとえば、 図では、システムが各ディシジョン ツリーをトレーニング サンプルの約 3 分の 2 をモデルに 3 分の 1 で済みます。

袋外評価は計算効率が高く、保守的 交差検証メカニズムの近似値。 交差検証では、交差検証ラウンドごとに 1 つのモデルがトレーニングされる (たとえば、10 回の交差検証で 10 個のモデルがトレーニングされます)。 OOB 評価では、単一のモデルがトレーニングされます。バギングのため トレーニング中に各ツリーから一部のデータを保留します。OOB 評価では、 そのデータを近似クロス検証します。
P
並べ替え変数の重要度
評価される変数の重要度の一種 並べ替えた後のモデルの予測誤差の増加 必要があります。並べ替え変数の重要度は、モデルに依存しない 表示されます。
R
ランダム フォレスト
複数のディシジョン ツリーのアンサンブル 特定のランダムノイズで各ディシジョン ツリーをトレーニングする (Baging など)。
ランダム フォレストは、ディシジョン フォレストの一種です。
根
開始ノード(最初のノードは 条件)をディシジョン ツリーに含めます。 慣例として、図ではルートをディシジョン ツリーの最上部に配置します。 例:

S
置換によるサンプリング
同じ名前が使われている一連の候補項目から 複数回選択できます。「置換あり」というフレーズ意味 選択するたびに、選択されたアイテムがプールに返されます 検証します。その逆の置換なしのサンプリングでは、 は、候補アイテムを 1 回だけ選択できることを意味します。
たとえば、次のフルーツセットについて考えてみましょう。
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
システムが最初のアイテムとして fig をランダムに選択するとします。
置換によるサンプリングを使用する場合、
次のセットから 2 番目のアイテムです。
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
はい、これは前のセットと同じです。したがって、
もう一度figを選択します。
置換なしのサンプリングを使用する場合、一度選択したサンプルは
選択します。たとえば、システムが fig をラベルとしてランダムに選択し、
最初のサンプルでは、fig を再度選択することはできません。そのためシステムは
次の(縮小された)セットから 2 番目のサンプルを選択します。
fruit = {kiwi, apple, pear, cherry, lime, mango}
縮み
ハイパーパラメータ: 勾配ブースティング 過学習。勾配ブースティングの縮小 これは Google の学習率に相当します。 勾配降下法。縮小率は小数である 0.0 ~ 1.0 の範囲で指定してください。収縮値が小さいほど過学習が減少する 収縮率よりも大きくなります
スプリット
ディシジョン ツリーでは、 condition。
スプリッター
ディシジョン ツリーをトレーニングする際、 (とアルゴリズム)に責任を持って 各 ノードの条件。
T
test
ディシジョン ツリーでは、 condition。
しきい値(ディシジョン ツリーの場合)
軸に揃えられた条件で、 特徴の比較対象です。たとえば、75 は、 次の条件でしきい値を指定します。
grade >= 75<ph type="x-smartling-placeholder">
V
重要度の変化
各スコアの相対的な重要度を示す一連のスコア feature をモデルに追加します。
たとえば、ディシジョン ツリーを考えてみます。 住宅価格の見積もり。このディシジョン ツリーには 3 つの 特徴(size、age、style)の 3 つです。ある一連の変数の重要度が 3 つの特徴量は {size=5.8, age=2.5, style=4.7} の場合、 年齢やスタイルより決定権があります
重要度が変動するさまざまな指標から情報を得る モデルのさまざまな側面に関する ML エキスパート。
W
観客の知恵
大きなグループの意見や推定を平均化するという考え方は 驚くほど良い結果が得られることが多いです。 たとえば、ユーザーが数字を当てるゲームについて考えてみましょう。 大きな瓶に入ったジェリー豆。個々の要素は 予測が不正確になる場合、すべての推測の平均が 驚くほどに実際の数に近いことが 実証されています 瓶の中にジェリービーンズ。
アンサンブルは、観客の知恵をソフトウェアで表現したものです。 たとえ個々のモデルの予測が非常に不正確な場合でも 多くのモデルの予測を平均すると 学習します。たとえば、ある個人が ディシジョン ツリーを使用すると、予測が不正確になる可能性があります。 多くの場合、ディシジョン フォレストは非常に優れた予測を行います。