Ta strona zawiera glosariusze z lasów decyzyjnych. Dla wszystkich terminów używanych w glosariuszu kliknij tutaj.
A
próbkowanie atrybutów
Taktyka trenowania lasu decyzji, w którym każdy Drzewo decyzji uwzględnia tylko losowy podzbiór możliwych funkcje podczas poznawania stanu. Ogólnie dla każdego z nich próbkowany jest inny podzbiór cech węzeł. Natomiast podczas trenowania drzewa decyzyjnego bez próbkowania atrybutów brane są pod uwagę wszystkie możliwe cechy dla każdego węzła.
warunek wyrównany do osi
W drzewie decyzji warunek który obejmuje tylko jedną funkcję. Na przykład, jeśli pole jest cechą, to taki warunek jest dopasowany do osi:
area > 200
Różnica z warunkem skośnym.
B
bagaż
Sposób trenowania zespołu, w którym każdy składnikowy model trenuje na losowym podzbiorze trenowania spróbkowane z zastąpieniem. Na przykład losowy las to zbiór drzewa decyzyjne wytrenowane w zakresie bagażu.
Termin bagaż to skrót od bootstrap agging.
warunek binarny
W drzewie decyzji warunek który ma tylko 2 możliwe wyniki – zwykle tak lub nie. Na przykład taki warunek binarny:
temperature >= 100
Ustaw kontrast z warunkem niebinarnym.
C
stan
W drzewie decyzyjnych dowolny węzeł, który ocenia wyrażenie. Na przykład ta część drzewo decyzyjne zawiera 2 warunki:

Warunek jest też nazywany podziałem lub testem.
Stan kontrastu: liść.
Zobacz także:
D
las decyzji
Model utworzony na podstawie wielu drzew decyzyjnych. Las decyzyjny tworzy prognozy, agregując prognozy i drzewa decyzyjne. Do popularnych typów lasów decyzyjnych należą: losowe lasy i drzewa z motywem gradientu.
schemat decyzyjny
Nadzorowany model uczenia się składający się ze zbioru warunki i liście uporządkowane hierarchicznie. Oto przykładowe schematy decyzyjne:

E
entropia
W teoria informacji, opis nieprzewidywalności prawdopodobieństwa zgodnie z rozkładem. Entropia jest też zdefiniowana jako informacje zawarte w każdym przykładzie. Dystrybucja zawiera najwyższa możliwa entropia, gdy wszystkie wartości zmiennej losowej są z równym prawdopodobieństwem.
Entropia zbioru z dwiema możliwymi wartościami „0” i „1” (na przykład etykiet w zadaniu klasyfikacji binarnej) ma następującą formułę:
H = -p log p - q log q = -p log p - (1-p) * log (1-p) .
gdzie:
- H oznacza entropię.
- p to ułamek liczby „1”. przykłady.
- q to ułamek liczby „0” przykłady. Pamiętaj, że q = (1 – p).
- log to zwykle log2. W tym przypadku entropia rozmiar jest niższy.
Załóżmy na przykład, że:
- 100 przykładów zawiera wartość „1”
- 300 przykładów zawiera wartość „0”
W związku z tym wartość entropii wynosi:
- P = 0,25
- Q = 0,75
- H = (-0,25)log2(0,25) – (0,75)log2(0,75) = 0,81 bitu na przykład
Idealnie zrównoważony zestaw (np. 200 „0” i 200 „1”). ma na przykład entropię równą 1,0 bitu. W miarę jak zestaw niezrównoważony, jej entropia przesuwa się w kierunku 0,0.
W drzewach decyzyjnych entropia pomaga wyznaczać zdobywania informacji, aby pomóc dzielnik wybierz warunki podczas rozwoju drzewa decyzyjnego dotyczącego klasyfikacji.
Porównaj entropię z:
- nieczyszczenie gini
- funkcja straty entropii krzyżowej
Entropia jest często nazywana entropią Shannona.
F
znaczenie cech
Synonim zmiennej ważności.
G
nieczystość ginie
Dane podobne do entropii. Rozdzielacze użyj do utworzenia wartości pochodzących z zanieczyszczenia gini lub entropii warunki klasyfikacji drzewa decyzyjne. Zysk informacji pochodzi z entropii. Nie istnieje powszechnie akceptowany termin równoważny dla danych wywodzących się z zanieczyszczenia giniego; te dane bez nazwy są jednak równie ważne, uzyskać cenne informacje.
Nieczystość giniego jest również nazywana wskaźnikiem ginie lub po prostu gini.
drzewa decyzyjne z wzmocnieniem gradientu (GBT),
Rodzaj lasu decyzji, w którym:
- Szkolenie wymaga wzmocnienie gradientu.
- Słaby model to drzewo decyzyjne.
wzmocnienie gradientu
Algorytm trenowania, w którym słabe modele są trenowane iteracyjnie Poprawa jakości (zmniejszenie utraty) solidnego modelu. Przykład: Słabym modelem może być liniowy lub mały model drzewa decyzyjnego. Silny model staje się sumą wszystkich wytrenowanych wcześniej słabych modeli.
W najprostszej formie wzmocnienia gradientem przy każdej iteracji słaby model jest trenowany tak, aby prognozował gradient straty silnego modelu. Następnie funkcja silny model jest aktualizowany przez odjęcie przewidywanego gradientu, podobnie jak w przypadku opadania gradientowego.
gdzie:
- $F_{0}$ to początkowy solidny model.
- Kolejnym solidnym modelem jest $F_{i+1}$.
- $F_{i}$ to obecny solidny model.
- $\xi$ to wartość z zakresu od 0,0 do 1,0 nazywana skurczem, co jest analogiczne do tempo uczenia się w opadanie gradientowe.
- $f_{i}$ to słaby model wytrenowany do przewidywania gradientu straty $F_{i}$.
Współczesne odmiany wzmocnienia gradientowego obejmują również drugą pochodną (Hessja) straty w obliczeniach.
Drzewa decyzyjne są powszechnie używane jako słabe modele wzmocnienia gradientu. Zobacz drzewa decyzyjne z ulepszoną jakością gradientu.
I
ścieżka wnioskowania
W drzewie decyzji podczas wnioskowania trasa konkretnego przykładu z root do innych warunków, które kończą się ciągiem liść. W poniższym drzewie decyzyjnym grubsze strzałki wskazują ścieżkę wnioskowania dla przykładu z następującym wartości cech:
- x = 7
- y = 12
- Z = -3
Ścieżka wnioskowania na ilustracji poniżej przebiega przez trzy
przed dotarciem do liścia (Zeta).

Trzy grube strzałki wskazują ścieżkę wnioskowania.
zdobycie informacji
W kategorii Decyzje lasy różnica między entropii węzła i ważonej (według liczby przykładów) sumę entropii jego węzłów podrzędnych. Entropia węzła jest entropią w tym węźle.
Weźmy na przykład te wartości entropii:
- entropia węzła nadrzędnego = 0,6
- entropia jednego węzła podrzędnego z 16 odpowiednimi przykładami = 0,2
- entropia innego węzła podrzędnego z 24 odpowiednimi przykładami = 0,1
40% przykładów znajduje się w jednym węźle podrzędnym, a 60% w węźle. innego węzła podrzędnego. Dlatego:
- ważona suma entropii węzłów podrzędnych = (0,4 * 0,2) + (0,6 * 0,1) = 0,14
Uzyskanie informacji jest więc takie:
- wzrost informacji = entropia węzła nadrzędnego - ważona suma entropii węzłów podrzędnych
- wzmocnienie informacji = 0,6 - 0,14 = 0,46
Większość rozdzielaczy ma na celu tworzenie warunków które zapewniają maksymalne korzyści.
stan w zestawie
W drzewie decyzji warunek który sprawdza obecność jednego elementu w zestawie. Oto przykładowy warunek w zestawie:
house-style in [tudor, colonial, cape]
Podczas wnioskowania, jeśli wartość cech w stylu domu
wynosi tudor, colonial lub cape, ten warunek przyjmuje wartość Tak. Jeśli
wartość obiektu w stylu domu jest inna (np. ranch),
ten warunek przyjmuje wartość Nie.
Określone warunki pozwalają zwykle na tworzenie bardziej skutecznych drzew decyzyjnych niż w których testują funkcje kodowane jednym gorąco.
L
liść
Dowolny punkt końcowy w drzewie decyzji. Usuń polubienie condition, liść nie przeprowadza testu. Możliwy jest raczej liść. Liść to także terminal węzeł ścieżki wnioskowania.
Na przykład następujące drzewo decyzyjne zawiera 3 liści:

N
węzeł (drzewo decyzji)
W drzewie decyzji dowolny stan lub liść.
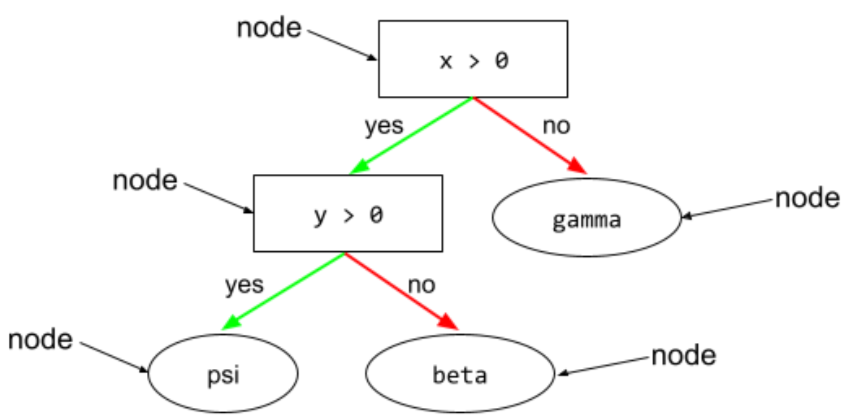
niebinarny warunek
Warunek obejmujący więcej niż 2 możliwe wyniki. Na przykład poniższy warunek niebinarny zawiera 3 możliwe wyniki:

O
warunek skośny
W drzewie decyzji condition, który obejmuje więcej niż jeden funkcja. Jeśli na przykład wysokość i szerokość są obiektami, to warunek skośny:
height > width
Porównaj warunek wyrównany do osi.
ocena bezpośrednia
Mechanizm oceny jakości Decyzja, testując każdy drzewo decyzji wobec modelu przykłady nieużywane szkolenia tego drzewa decyzyjnego. Na przykład w tagu zauważ, że system trenuje każde drzewo decyzyjne na około 2/3 przykładów, a następnie dokonuje oceny pod kątem argumentu pozostałej jednej trzeciej przykładów.

Takie podejście jest wydajną i zachowawczą metodą obliczeniową, w przybliżeniu mechanizmu weryfikacji krzyżowej. W weryfikacji krzyżowej trenowany jest 1 model na każdą rundę weryfikacji krzyżowej Na przykład 10 modeli zostało wytrenowanych na 10-krotnej weryfikacji krzyżowej. W przypadku oceny OOB trenowany jest 1 model. Ponieważ bagaż pomija część danych z każdego drzewa podczas trenowania, ocena OOB może wykorzystać aby uzyskać przybliżoną weryfikację krzyżową.
P
znaczenie zmiennej permutacji
Rodzaj zmiennej ważności, która ocenia wzrost błędu prognozy modelu po przekształceniu argumentu wartości funkcji. Znaczenie zmiennej permutacji jest niezależne od modelu danych.
R
Losowy las
Zbiór drzew decyzyjnych w w którym każde drzewo decyzyjne jest trenowane z wykorzystaniem konkretnego losowego szumu, na przykład bagaż.
Lasy losowe to rodzaj lasu decyzji.
poziom główny
węzeł początkowy (pierwszy condition) w drzewie decyzyjnym. Zgodnie z konwencją diagramy umieszczają korzenie na górze drzewa decyzyjnego. Na przykład:

S
próbkowanie z zastąpieniem
Metoda wybierania elementów ze zbioru elementów kandydujących, w którym ten element można wybrać wiele razy. Wyrażenie „z zamiennikiem” oznacza że po każdym wybraniu element jest zwracany do puli elementów kandydujących. Metoda odwrotna, próbkowanie bez zastępowania, oznacza, że element kandydujący można wybrać tylko raz.
Weźmy na przykład taki zestaw owocowy:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Załóżmy, że system losowo wybiera fig jako pierwszy element.
Jeśli korzystasz z próbkowania z zastąpieniem, system wybiera
drugi element z następującego zestawu:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango}
Tak. Ten zestaw jest taki sam jak wcześniej, więc system może potencjalnie
jeszcze raz wybierz fig.
Jeśli używasz próbkowania bez zastąpienia, po wybraniu próbki nie można
wybrano jeszcze raz. Jeśli na przykład system losowo wybierze fig jako
za pierwszą próbkę, potem fig nie będzie można wybrać ponownie. Dlatego system
wybiera drugą próbkę z następującego (zmniejszonego) zbioru:
fruit = {kiwi, apple, pear, cherry, lime, mango}
zmniejszanie
hiperparametr w wzmocnienie gradientu, nadmiernego dopasowania. Zmniejszenie w wzmocnieniu gradientowym jest analogiczny do tempa uczenia się w gradient gradientowy. Zmniejszanie jest liczbą dziesiętną z zakresu od 0,0 do 1,0. Niższa wartość kurczenia ogranicza dopasowanie niż większa wartość kurczenia.
podział : fragment
W drzewie decyzji jest to inna nazwa condition [stan].
rozdzielacz
Podczas trenowania drzewa decyzji, rutyna (i algorytm) odpowiedzialnej za wyszukiwanie condition w każdym węźle.
T
test
W drzewie decyzji jest to inna nazwa condition [stan].
próg (dla drzew decyzyjnych)
W warunku wyrównanym do osi jest to wartość cecha jest porównywana. Na przykład 75 to wartość progową w następującym warunku:
grade >= 75
V
znaczenie zmiennej
Zbiór wyników wskazujący względne znaczenie poszczególnych elementów feature do modelu.
Rozważ takie drzewo decyzyjne, które: podaje szacunkowe ceny domów. Załóżmy, że w tym drzewie decyzyjnym są wykorzystywane trzy rozmiar, wiek i styl. Jeśli zestaw zmiennych ma znaczenie dla 3 cech oblicza się jako {size=5.8, age=2.5, style=4.7}, rozmiar jest ważniejszy dla drzewo decyzyjne niż wiek i styl.
Istnieją różne wskaźniki ważności zmiennych, które mogą informować Eksperci ds. systemów uczących się o różnych aspektach modeli.
W
mądrość tłumu
Koncepcja uśredniania opinii lub oszacowań dużej grupy często przynoszą zaskakująco dobre wyniki. Rozważmy na przykład grę, w której użytkownicy zgadują liczbę żelki zapakowane do dużego słoika. Chociaż większość odgadnięcia będą niedokładne, średnia z wszystkich odgadań została wykazano empirycznie, że są zaskakująco zbliżone do rzeczywistej liczby z galaretką w słoiku.
Ensembles to programowy analog mądrości tłumu. Nawet jeśli poszczególne modele podają bardzo niedokładne prognozy, uśrednianie prognoz wielu modeli często generuje zaskakujące wyniki, i przydatne podpowiedzi. Na przykład, chociaż dana osoba drzewo decyzji może generować złe prognozy, Decyzja lasu często generuje bardzo dobre prognozy.