এই পৃষ্ঠায় ML ফান্ডামেন্টাল শব্দকোষের পদ রয়েছে। সকল শব্দকোষের জন্য এখানে ক্লিক করুন ।
ক
নির্ভুলতা
সঠিক শ্রেণীবিভাগের ভবিষ্যদ্বাণীর সংখ্যাকে ভবিষ্যদ্বাণীর মোট সংখ্যা দিয়ে ভাগ করলে। অর্থাৎ:
উদাহরণস্বরূপ, একটি মডেল যা 40টি সঠিক ভবিষ্যদ্বাণী করেছে এবং 10টি ভুল ভবিষ্যদ্বাণী করেছে তার সঠিকতা থাকবে:
বাইনারি শ্রেণীবিভাগ সঠিক ভবিষ্যদ্বাণী এবং ভুল ভবিষ্যদ্বাণীর বিভিন্ন বিভাগের জন্য নির্দিষ্ট নাম প্রদান করে। সুতরাং, বাইনারি শ্রেণীবিভাগের নির্ভুলতা সূত্রটি নিম্নরূপ:
কোথায়:
- TP হল সত্য ইতিবাচক সংখ্যা (সঠিক ভবিষ্যদ্বাণী)।
- TN হল সত্য নেতিবাচক সংখ্যা (সঠিক ভবিষ্যদ্বাণী)।
- FP হল মিথ্যা ইতিবাচক সংখ্যা (ভুল ভবিষ্যদ্বাণী)।
- FN হল মিথ্যা নেতিবাচক সংখ্যা (ভুল পূর্বাভাস)।
নির্ভুলতা এবং প্রত্যাহার সঙ্গে তুলনা এবং বিপরীতে নির্ভুলতা.
সক্রিয়করণ ফাংশন
একটি ফাংশন যা নিউরাল নেটওয়ার্কগুলিকে বৈশিষ্ট্য এবং লেবেলের মধ্যে অরৈখিক (জটিল) সম্পর্ক শিখতে সক্ষম করে।
জনপ্রিয় সক্রিয়করণ ফাংশন অন্তর্ভুক্ত:
অ্যাক্টিভেশন ফাংশনগুলির প্লটগুলি কখনই একক সরলরেখা নয়। উদাহরণস্বরূপ, ReLU অ্যাক্টিভেশন ফাংশনের প্লট দুটি সরল রেখা নিয়ে গঠিত:

সিগমায়েড অ্যাক্টিভেশন ফাংশনের একটি প্লট নিম্নরূপ দেখায়:

একটি উদাহরণ দেখতে আইকনে ক্লিক করুন.
একটি নিউরাল নেটওয়ার্কে, অ্যাক্টিভেশন ফাংশনগুলি একটি নিউরনে সমস্ত ইনপুটের ওজনযুক্ত যোগফলকে ম্যানিপুলেট করে। একটি ওজনযুক্ত যোগফল গণনা করতে, নিউরন প্রাসঙ্গিক মান এবং ওজনের পণ্যগুলি যোগ করে। উদাহরণস্বরূপ, ধরুন একটি নিউরনে প্রাসঙ্গিক ইনপুট নিম্নলিখিতগুলি নিয়ে গঠিত:
| ইনপুট মান | ইনপুট ওজন |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
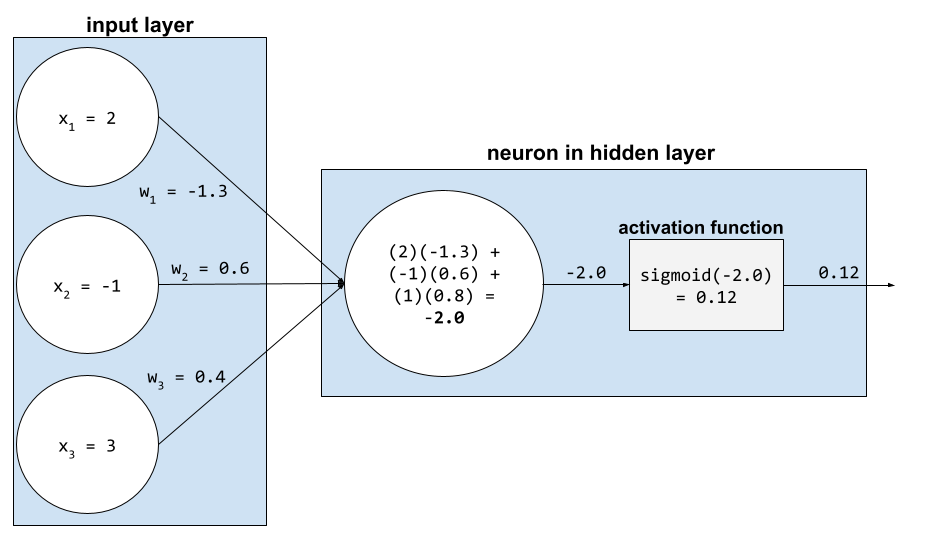
কৃত্রিম বুদ্ধিমত্তা
একটি অ-মানব প্রোগ্রাম বা মডেল যা পরিশীলিত কাজগুলি সমাধান করতে পারে। উদাহরণস্বরূপ, একটি প্রোগ্রাম বা মডেল যা পাঠ্য অনুবাদ করে বা একটি প্রোগ্রাম বা মডেল যা রেডিওলজিক চিত্র থেকে রোগ সনাক্ত করে উভয়ই কৃত্রিম বুদ্ধিমত্তা প্রদর্শন করে।
আনুষ্ঠানিকভাবে, মেশিন লার্নিং হল কৃত্রিম বুদ্ধিমত্তার একটি উপ-ক্ষেত্র। যাইহোক, সাম্প্রতিক বছরগুলিতে, কিছু সংস্থা কৃত্রিম বুদ্ধিমত্তা এবং মেশিন লার্নিং শব্দগুলিকে বিনিময়যোগ্যভাবে ব্যবহার করা শুরু করেছে।
AUC (ROC বক্ররেখার অধীনে এলাকা)
0.0 এবং 1.0 এর মধ্যে একটি সংখ্যা যা একটি বাইনারি শ্রেণীবিন্যাস মডেলের নেতিবাচক শ্রেণী থেকে ইতিবাচক শ্রেণীগুলিকে পৃথক করার ক্ষমতা উপস্থাপন করে। AUC 1.0 এর যত কাছাকাছি হবে, মডেলের একে অপরের থেকে ক্লাস আলাদা করার ক্ষমতা তত ভাল।
উদাহরণস্বরূপ, নিম্নলিখিত চিত্রটি একটি শ্রেণীবদ্ধ মডেল দেখায় যা ইতিবাচক শ্রেণীগুলি (সবুজ ডিম্বাকৃতি) নেতিবাচক শ্রেণীগুলি (বেগুনি আয়তক্ষেত্রগুলি) থেকে পুরোপুরি আলাদা করে। এই অবাস্তবভাবে নিখুঁত মডেলটির একটি AUC 1.0 রয়েছে:

বিপরীতভাবে, নিম্নলিখিত চিত্রটি একটি শ্রেণিবদ্ধ মডেলের ফলাফল দেখায় যা এলোমেলো ফলাফল তৈরি করেছে। এই মডেলটির একটি AUC 0.5 রয়েছে:

হ্যাঁ, পূর্ববর্তী মডেলটির একটি AUC 0.5 আছে, 0.0 নয়৷
বেশিরভাগ মডেল দুটি চরমের মধ্যে কোথাও আছে। উদাহরণস্বরূপ, নিম্নলিখিত মডেলটি নেতিবাচক থেকে ইতিবাচককে কিছুটা আলাদা করে, এবং তাই 0.5 এবং 1.0 এর মধ্যে একটি AUC রয়েছে:

AUC আপনার শ্রেণীবিন্যাস থ্রেশহোল্ডের জন্য সেট করা যেকোনো মান উপেক্ষা করে। পরিবর্তে, AUC সমস্ত সম্ভাব্য শ্রেণীবিভাগ থ্রেশহোল্ড বিবেচনা করে।
AUC এবং ROC বক্ররেখার মধ্যে সম্পর্ক সম্পর্কে জানতে আইকনে ক্লিক করুন।
AUC একটি ROC বক্ররেখার অধীনে এলাকা প্রতিনিধিত্ব করে। উদাহরণস্বরূপ, একটি মডেলের জন্য ROC বক্ররেখা যা সম্পূর্ণরূপে নেতিবাচক থেকে ইতিবাচককে পৃথক করে তা নিম্নরূপ দেখায়:
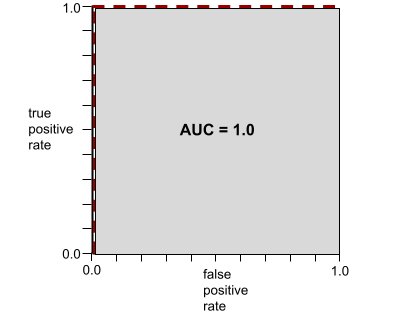
AUC হল পূর্বের চিত্রে ধূসর অঞ্চলের এলাকা। এই অস্বাভাবিক ক্ষেত্রে, এলাকাটি কেবল ধূসর অঞ্চলের দৈর্ঘ্য (1.0) ধূসর অঞ্চলের প্রস্থ (1.0) দ্বারা গুণিত। সুতরাং, 1.0 এবং 1.0 এর গুণফল ঠিক 1.0 এর একটি AUC প্রদান করে, যা সর্বোচ্চ সম্ভাব্য AUC স্কোর।
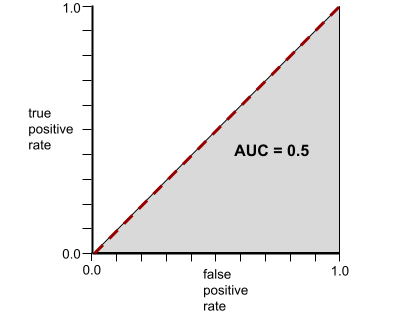
বিপরীতভাবে, একটি ক্লাসিফায়ারের জন্য ROC বক্ররেখা যা মোটেও ক্লাস আলাদা করতে পারে না নিম্নরূপ। এই ধূসর অঞ্চলের ক্ষেত্রফল 0.5।
একটি আরো সাধারণ ROC বক্ররেখা প্রায় নিম্নলিখিত মত দেখায়:
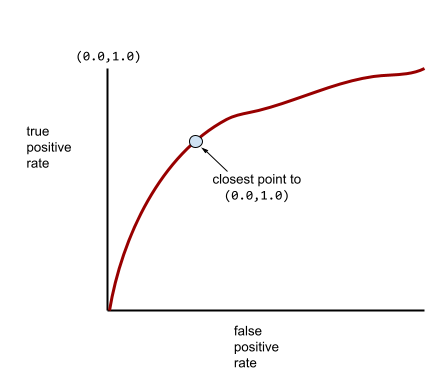
ম্যানুয়ালি এই বক্ররেখার অধীনে এলাকা গণনা করা কষ্টকর হবে, এই কারণেই একটি প্রোগ্রাম সাধারণত বেশিরভাগ AUC মান গণনা করে।
খ
backpropagation
অ্যালগরিদম যা নিউরাল নেটওয়ার্কগুলিতে গ্রেডিয়েন্ট ডিসেন্ট প্রয়োগ করে৷
একটি নিউরাল নেটওয়ার্ক প্রশিক্ষণ নিম্নলিখিত দুই-পাস চক্রের অনেক পুনরাবৃত্তি জড়িত:
- ফরওয়ার্ড পাসের সময়, সিস্টেম ভবিষ্যদ্বাণী(গুলি) প্রদানের জন্য উদাহরণগুলির একটি ব্যাচ প্রক্রিয়া করে। সিস্টেম প্রতিটি লেবেল মানের সাথে প্রতিটি ভবিষ্যদ্বাণী তুলনা করে। ভবিষ্যদ্বাণী এবং লেবেল মানের মধ্যে পার্থক্য হল সেই উদাহরণের ক্ষতি । বর্তমান ব্যাচের মোট ক্ষতি গণনা করার জন্য সিস্টেমটি সমস্ত উদাহরণের জন্য ক্ষতিগুলিকে একত্রিত করে।
- ব্যাকওয়ার্ড পাসের সময় (ব্যাকপ্রপাগেশন), সিস্টেমটি সমস্ত লুকানো স্তর(গুলি) এর সমস্ত নিউরনের ওজন সামঞ্জস্য করে ক্ষতি হ্রাস করে।
নিউরাল নেটওয়ার্কে প্রায়ই অনেক লুকানো স্তর জুড়ে অনেক নিউরন থাকে। এই নিউরনগুলির প্রতিটি বিভিন্ন উপায়ে সামগ্রিক ক্ষতিতে অবদান রাখে। ব্যাকপ্রোপ্যাগেশন নির্দিষ্ট নিউরনগুলিতে প্রয়োগ করা ওজন বাড়ানো বা হ্রাস করা নির্ধারণ করে।
শেখার হার হল একটি গুণক যা প্রতিটি পশ্চাদগামী পাস প্রতিটি ওজন বৃদ্ধি বা হ্রাস করার মাত্রা নিয়ন্ত্রণ করে। একটি বড় শেখার হার প্রতিটি ওজন একটি ছোট শেখার হারের চেয়ে বেশি বৃদ্ধি বা হ্রাস করবে।
ক্যালকুলাস পদে, ব্যাকপ্রোপগেশন চেইন নিয়ম প্রয়োগ করে। ক্যালকুলাস থেকে অর্থাৎ, ব্যাকপ্রোপগেশন প্রতিটি প্যারামিটারের ক্ষেত্রে ত্রুটির আংশিক ডেরিভেটিভ গণনা করে।
কয়েক বছর আগে, এমএল অনুশীলনকারীদের ব্যাকপ্রোপগেশন বাস্তবায়নের জন্য কোড লিখতে হয়েছিল। TensorFlow-এর মতো আধুনিক ML APIগুলি এখন আপনার জন্য ব্যাকপ্রোপগেশন প্রয়োগ করে৷ ফাউ!
ব্যাচ
একটি প্রশিক্ষণের পুনরাবৃত্তিতে ব্যবহৃত উদাহরণের সেট। ব্যাচের আকার একটি ব্যাচে উদাহরণের সংখ্যা নির্ধারণ করে।
একটি ব্যাচ কিভাবে একটি যুগের সাথে সম্পর্কিত তার ব্যাখ্যার জন্য epoch দেখুন।
ব্যাচ আকার
একটি ব্যাচে উদাহরণের সংখ্যা। উদাহরণস্বরূপ, যদি ব্যাচের আকার 100 হয়, তাহলে মডেলটি প্রতি পুনরাবৃত্তি 100টি উদাহরণ প্রক্রিয়া করে।
নিম্নলিখিত জনপ্রিয় ব্যাচ আকার কৌশল:
- স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD) , যার ব্যাচের আকার 1।
- সম্পূর্ণ ব্যাচ, যেখানে ব্যাচের আকার পুরো প্রশিক্ষণ সেটের উদাহরণের সংখ্যা। উদাহরণস্বরূপ, যদি প্রশিক্ষণ সেটে এক মিলিয়ন উদাহরণ থাকে, তাহলে ব্যাচের আকার এক মিলিয়ন উদাহরণ হবে। সম্পূর্ণ ব্যাচ সাধারণত একটি অদক্ষ কৌশল।
- মিনি-ব্যাচ যেখানে ব্যাচের আকার সাধারণত 10 থেকে 1000 এর মধ্যে হয়। মিনি-ব্যাচ সাধারণত সবচেয়ে কার্যকরী কৌশল।
পক্ষপাত (নৈতিকতা/ন্যায়)
1. কিছু জিনিস, মানুষ বা গোষ্ঠীর প্রতি স্টিরিওটাইপিং, কুসংস্কার বা পক্ষপাতিত্ব। এই পক্ষপাতগুলি ডেটা সংগ্রহ এবং ব্যাখ্যা, একটি সিস্টেমের নকশা এবং ব্যবহারকারীরা কীভাবে একটি সিস্টেমের সাথে যোগাযোগ করে তা প্রভাবিত করতে পারে। এই ধরনের পক্ষপাতের ফর্মগুলির মধ্যে রয়েছে:
- অটোমেশন পক্ষপাত
- নিশ্চিতকরণ পক্ষপাত
- পরীক্ষকের পক্ষপাত
- গ্রুপ অ্যাট্রিবিউশন পক্ষপাত
- অন্তর্নিহিত পক্ষপাত
- ইন-গ্রুপ পক্ষপাত
- আউট-গ্রুপ একজাতীয়তা পক্ষপাত
2. একটি নমুনা বা রিপোর্টিং পদ্ধতি দ্বারা প্রবর্তিত পদ্ধতিগত ত্রুটি। এই ধরনের পক্ষপাতের ফর্মগুলির মধ্যে রয়েছে:
- কভারেজ পক্ষপাত
- অ-প্রতিক্রিয়া পক্ষপাত
- অংশগ্রহণের পক্ষপাতিত্ব
- রিপোর্টিং পক্ষপাত
- স্যাম্পলিং পক্ষপাত
- নির্বাচনের পক্ষপাতিত্ব
মেশিন লার্নিং মডেল বা ভবিষ্যদ্বাণী পক্ষপাতিত্ব শব্দের সাথে বিভ্রান্ত হবেন না।
পক্ষপাত (গণিত) বা পক্ষপাত শব্দ
একটি উত্স থেকে একটি বাধা বা অফসেট. বায়াস হল মেশিন লার্নিং মডেলের একটি প্যারামিটার, যা নিম্নলিখিতগুলির যে কোনো একটি দ্বারা চিহ্নিত করা হয়:
- খ
- w 0
উদাহরণস্বরূপ, নিম্নোক্ত সূত্রে পক্ষপাত হল b :
একটি সাধারণ দ্বি-মাত্রিক লাইনে, পক্ষপাত মানে শুধু "y-ইন্টারসেপ্ট।" উদাহরণস্বরূপ, নিম্নলিখিত চিত্রে লাইনের পক্ষপাত হল 2।
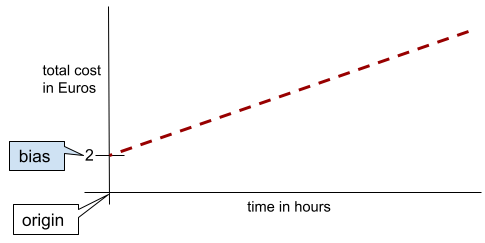
পক্ষপাত বিদ্যমান কারণ সমস্ত মডেল মূল (0,0) থেকে শুরু হয় না। উদাহরণস্বরূপ, ধরুন একটি বিনোদন পার্কে প্রবেশ করতে 2 ইউরো এবং একজন গ্রাহক থাকার প্রতি ঘন্টার জন্য অতিরিক্ত 0.5 ইউরো। অতএব, মোট খরচ ম্যাপিং একটি মডেল 2 এর পক্ষপাতী কারণ সর্বনিম্ন খরচ হল 2 ইউরো।
নৈতিকতা এবং ন্যায্যতা বা ভবিষ্যদ্বাণী পক্ষপাতের সাথে পক্ষপাতিত্বের সাথে বিভ্রান্ত হওয়া উচিত নয়।
বাইনারি শ্রেণীবিভাগ
এক ধরনের শ্রেণীবিন্যাস টাস্ক যা দুটি পারস্পরিক একচেটিয়া শ্রেণীর একটির পূর্বাভাস দেয়:
উদাহরণস্বরূপ, নিম্নলিখিত দুটি মেশিন লার্নিং মডেল প্রতিটি বাইনারি শ্রেণীবিভাগ সম্পাদন করে:
- একটি মডেল যা নির্ধারণ করে যে ইমেল বার্তাগুলি স্প্যাম (পজিটিভ ক্লাস) না স্প্যাম (নেতিবাচক ক্লাস)।
- একটি মডেল যা একজন ব্যক্তির একটি নির্দিষ্ট রোগ (পজিটিভ ক্লাস) আছে কিনা বা সেই রোগ (নেতিবাচক শ্রেণী) নেই কিনা তা নির্ধারণ করতে চিকিৎসা লক্ষণগুলি মূল্যায়ন করে।
বহু-শ্রেণীর শ্রেণীবিভাগের সাথে বৈসাদৃশ্য।
লজিস্টিক রিগ্রেশন এবং শ্রেণীবিভাগ থ্রেশহোল্ড দেখুন।
বালতি
একটি একক বৈশিষ্ট্যকে একাধিক বাইনারি বৈশিষ্ট্যে রূপান্তর করা যাকে বলা হয় বালতি বা বিন , সাধারণত একটি মান পরিসরের উপর ভিত্তি করে। কাটা বৈশিষ্ট্যটি সাধারণত একটি অবিচ্ছিন্ন বৈশিষ্ট্য ।
উদাহরণস্বরূপ, তাপমাত্রাকে একটি অবিচ্ছিন্ন ফ্লোটিং-পয়েন্ট বৈশিষ্ট্য হিসাবে উপস্থাপন করার পরিবর্তে, আপনি তাপমাত্রার রেঞ্জগুলিকে আলাদা বালতিতে কাটতে পারেন, যেমন:
- <= 10 ডিগ্রি সেলসিয়াস হবে "ঠান্ডা" বালতি।
- 11 - 24 ডিগ্রি সেলসিয়াস "নাতিশীতোষ্ণ" বালতি হবে।
- >= 25 ডিগ্রি সেলসিয়াস হবে "উষ্ণ" বালতি।
মডেলটি একই বালতিতে প্রতিটি মানকে অভিন্নভাবে বিবেচনা করবে। উদাহরণস্বরূপ, মান 13 এবং 22 উভয়ই নাতিশীতোষ্ণ বালতিতে রয়েছে, তাই মডেল দুটি মানকে অভিন্নভাবে বিবেচনা করে।
গ
শ্রেণীবদ্ধ তথ্য
সম্ভাব্য মানগুলির একটি নির্দিষ্ট সেট থাকা বৈশিষ্ট্যগুলি ৷ উদাহরণ স্বরূপ, traffic-light-state নামে একটি শ্রেণীবদ্ধ বৈশিষ্ট্য বিবেচনা করুন, যেটিতে শুধুমাত্র নিম্নলিখিত তিনটি সম্ভাব্য মানগুলির মধ্যে একটি থাকতে পারে:
-
red -
yellow -
green
traffic-light-state একটি শ্রেণীবদ্ধ বৈশিষ্ট্য হিসাবে উপস্থাপন করে, একটি মডেল চালকের আচরণের উপর red , green এবং yellow বিভিন্ন প্রভাব শিখতে পারে।
শ্রেণীগত বৈশিষ্ট্যগুলিকে কখনও কখনও পৃথক বৈশিষ্ট্য বলা হয়।
সংখ্যাসূচক তথ্যের সাথে বৈসাদৃশ্য।
ক্লাস
একটি বিভাগ যা একটি লেবেল অন্তর্গত হতে পারে৷ যেমন:
- একটি বাইনারি শ্রেণীবিভাগ মডেল যা স্প্যাম সনাক্ত করে, দুটি শ্রেণী স্প্যাম হতে পারে এবং স্প্যাম নয় ৷
- কুকুরের জাত শনাক্ত করে এমন একটি মাল্টি-ক্লাস ক্লাসিফিকেশন মডেলে, ক্লাসগুলি পুডল , বিগল , পগ ইত্যাদি হতে পারে।
একটি শ্রেণিবিন্যাস মডেল একটি শ্রেণির পূর্বাভাস দেয়। বিপরীতে, একটি রিগ্রেশন মডেল একটি শ্রেণির পরিবর্তে একটি সংখ্যার পূর্বাভাস দেয়।
শ্রেণিবিন্যাস মডেল
একটি মডেল যার ভবিষ্যদ্বাণী একটি ক্লাস । উদাহরণস্বরূপ, নিম্নলিখিত সমস্ত শ্রেণীবিভাগ মডেল:
- একটি মডেল যা একটি ইনপুট বাক্যের ভাষার ভবিষ্যদ্বাণী করে (ফরাসি? স্প্যানিশ? ইতালীয়?)।
- একটি মডেল যা গাছের প্রজাতির ভবিষ্যদ্বাণী করে (ম্যাপেল? ওক? বাওবাব?)।
- একটি মডেল যা একটি নির্দিষ্ট চিকিৎসা অবস্থার জন্য ইতিবাচক বা নেতিবাচক শ্রেণীর পূর্বাভাস দেয়।
বিপরীতে, রিগ্রেশন মডেলগুলি ক্লাসের পরিবর্তে সংখ্যার পূর্বাভাস দেয়।
দুটি সাধারণ ধরনের শ্রেণিবিন্যাস মডেল হল:
শ্রেণীবিভাগ থ্রেশহোল্ড
একটি বাইনারি শ্রেণীবিভাগে , 0 এবং 1 এর মধ্যে একটি সংখ্যা যা একটি লজিস্টিক রিগ্রেশন মডেলের কাঁচা আউটপুটকে ধনাত্মক শ্রেণি বা নেতিবাচক শ্রেণির একটি ভবিষ্যদ্বাণীতে রূপান্তর করে। মনে রাখবেন যে শ্রেণীবিন্যাস থ্রেশহোল্ড এমন একটি মান যা একজন মানুষ বেছে নেয়, মডেল প্রশিক্ষণ দ্বারা নির্বাচিত একটি মান নয়।
একটি লজিস্টিক রিগ্রেশন মডেল 0 এবং 1 এর মধ্যে একটি কাঁচা মান আউটপুট করে। তারপর:
- যদি এই কাঁচা মানটি শ্রেণিবিন্যাসের থ্রেশহোল্ডের চেয়ে বেশি হয়, তাহলে ধনাত্মক শ্রেণির পূর্বাভাস দেওয়া হয়।
- যদি এই কাঁচা মানটি শ্রেণিবিন্যাসের থ্রেশহোল্ডের চেয়ে কম হয়, তাহলে নেতিবাচক শ্রেণির পূর্বাভাস দেওয়া হয়।
উদাহরণস্বরূপ, ধরুন শ্রেণীবিন্যাস থ্রেশহোল্ড হল 0.8। যদি কাঁচা মান 0.9 হয়, তাহলে মডেলটি ইতিবাচক শ্রেণীর পূর্বাভাস দেয়। যদি কাঁচা মান 0.7 হয়, তাহলে মডেলটি নেতিবাচক শ্রেণীর পূর্বাভাস দেয়।
শ্রেণীবিন্যাস থ্রেশহোল্ডের পছন্দ দৃঢ়ভাবে মিথ্যা ইতিবাচক এবং মিথ্যা নেতিবাচক সংখ্যাকে প্রভাবিত করে।
শ্রেণী-ভারসাম্যহীন ডেটাসেট
একটি শ্রেণীবিন্যাস সমস্যার জন্য একটি ডেটাসেট যেখানে প্রতিটি শ্রেণীর লেবেলের মোট সংখ্যা উল্লেখযোগ্যভাবে আলাদা। উদাহরণস্বরূপ, একটি বাইনারি শ্রেণিবিন্যাস ডেটাসেট বিবেচনা করুন যার দুটি লেবেল নিম্নরূপ বিভক্ত:
- 1,000,000 নেতিবাচক লেবেল
- 10টি ইতিবাচক লেবেল
নেতিবাচক থেকে ইতিবাচক লেবেলের অনুপাত হল 100,000 থেকে 1, তাই এটি একটি শ্রেণী-ভারসাম্যহীন ডেটাসেট।
বিপরীতে, নিম্নলিখিত ডেটাসেটটি শ্রেণী-ভারসাম্যহীন নয় কারণ নেতিবাচক লেবেলের সাথে ইতিবাচক লেবেলের অনুপাত তুলনামূলকভাবে 1-এর কাছাকাছি:
- 517 নেতিবাচক লেবেল
- 483 ইতিবাচক লেবেল
মাল্টি-ক্লাস ডেটাসেটগুলিও শ্রেণী-ভারসাম্যহীন হতে পারে। উদাহরণস্বরূপ, নিম্নলিখিত মাল্টি-ক্লাস ক্লাসিফিকেশন ডেটাসেটটিও শ্রেণী-ভারসাম্যহীন কারণ একটি লেবেলে অন্য দুটির চেয়ে অনেক বেশি উদাহরণ রয়েছে:
- "সবুজ" শ্রেণী সহ 1,000,000 লেবেল
- "বেগুনি" ক্লাস সহ 200টি লেবেল
- "কমলা" ক্লাস সহ 350টি লেবেল
এছাড়াও এনট্রপি , সংখ্যাগরিষ্ঠ শ্রেণী এবং সংখ্যালঘু শ্রেণী দেখুন।
ক্লিপিং
নিম্নলিখিত যে কোনো একটি বা উভয়টি করে বহিরাগতদের পরিচালনা করার একটি কৌশল:
- সর্বাধিক থ্রেশহোল্ডের চেয়ে বেশি বৈশিষ্ট্যের মানগুলিকে সেই সর্বাধিক থ্রেশহোল্ডে হ্রাস করা৷
- সেই ন্যূনতম থ্রেশহোল্ড পর্যন্ত ন্যূনতম থ্রেশহোল্ডের চেয়ে কম বৈশিষ্ট্যের মানগুলি বৃদ্ধি করা৷
উদাহরণস্বরূপ, ধরুন যে একটি নির্দিষ্ট বৈশিষ্ট্যের <0.5% মান 40-60 রেঞ্জের বাইরে পড়ে। এই ক্ষেত্রে, আপনি নিম্নলিখিত করতে পারেন:
- 60-এর বেশি (সর্বোচ্চ থ্রেশহোল্ড) সমস্ত মান ঠিক 60 হতে ক্লিপ করুন।
- 40 এর নিচে সব মান ক্লিপ করুন (সর্বনিম্ন থ্রেশহোল্ড) ঠিক 40 হতে হবে।
বহিরাগতরা মডেলের ক্ষতি করতে পারে, কখনও কখনও প্রশিক্ষণের সময় ওজন উপচে পড়ে। কিছু আউটলিয়ারও নাটকীয়ভাবে নির্ভুলতার মতো মেট্রিক্স নষ্ট করতে পারে। ক্লিপিং ক্ষতি সীমাবদ্ধ করার একটি সাধারণ কৌশল।
গ্রেডিয়েন্ট ক্লিপিং প্রশিক্ষণের সময় একটি নির্দিষ্ট সীমার মধ্যে গ্রেডিয়েন্ট মানগুলিকে জোর করে।
বিভ্রান্তি ম্যাট্রিক্স
একটি NxN টেবিল যা একটি শ্রেণীবিভাগ মডেল তৈরি করা সঠিক এবং ভুল ভবিষ্যদ্বাণীগুলির সংখ্যা সংক্ষিপ্ত করে। উদাহরণস্বরূপ, একটি বাইনারি শ্রেণীবিভাগ মডেলের জন্য নিম্নলিখিত বিভ্রান্তি ম্যাট্রিক্স বিবেচনা করুন:
| টিউমার (ভবিষ্যদ্বাণী করা) | অ-টিউমার (ভবিষ্যদ্বাণী করা) | |
|---|---|---|
| টিউমার (স্থল সত্য) | 18 (TP) | 1 (FN) |
| অ-টিউমার (স্থল সত্য) | 6 (FP) | 452 (TN) |
পূর্ববর্তী বিভ্রান্তি ম্যাট্রিক্স নিম্নলিখিত দেখায়:
- 19টি ভবিষ্যদ্বাণীর মধ্যে যেখানে গ্রাউন্ড ট্রুথ টিউমার ছিল, মডেলটি সঠিকভাবে 18টি এবং ভুলভাবে 1 শ্রেণীবদ্ধ করেছে।
- 458টি ভবিষ্যদ্বাণীর মধ্যে যেখানে গ্রাউন্ড ট্রুথ ছিল নন-টিউমার, মডেলটি সঠিকভাবে 452টি এবং ভুলভাবে 6টি শ্রেণীবদ্ধ করেছে।
বহু-শ্রেণীর শ্রেণীবিভাগ সমস্যার জন্য বিভ্রান্তি ম্যাট্রিক্স আপনাকে ভুলের ধরণ সনাক্ত করতে সাহায্য করতে পারে। উদাহরণস্বরূপ, একটি 3-শ্রেণীর মাল্টি-ক্লাস ক্লাসিফিকেশন মডেলের জন্য নিম্নলিখিত বিভ্রান্তি ম্যাট্রিক্স বিবেচনা করুন যা তিনটি ভিন্ন আইরিস প্রকার (ভার্জিনিকা, ভার্সিকলার এবং সেটোসা) শ্রেণীবদ্ধ করে। যখন গ্রাউন্ড ট্রুথ ভার্জিনিকা ছিল, তখন কনফিউশন ম্যাট্রিক্স দেখায় যে সেটোসার তুলনায় মডেলটির ভুলভাবে ভার্সিকলার ভবিষ্যদ্বাণী করার সম্ভাবনা অনেক বেশি ছিল:
| সেতোসা (ভবিষ্যদ্বাণী করা) | ভার্সিকলার (ভবিষ্যদ্বাণী করা) | ভার্জিনিকা (ভবিষ্যদ্বাণী করা) | |
|---|---|---|---|
| সেতোসা (ভূমি সত্য) | ৮৮ | 12 | 0 |
| ভার্সিকলার (ভূমি সত্য) | 6 | 141 | 7 |
| ভার্জিনিকা (ভূমি সত্য) | 2 | 27 | 109 |
আরেকটি উদাহরণ হিসাবে, একটি বিভ্রান্তি ম্যাট্রিক্স প্রকাশ করতে পারে যে হাতে লেখা অঙ্কগুলি চিনতে প্রশিক্ষিত একটি মডেল ভুলভাবে 4 এর পরিবর্তে 9 বা ভুলভাবে 7 এর পরিবর্তে 1 ভবিষ্যদ্বাণী করে।
বিভ্রান্তি ম্যাট্রিক্সে যথার্থতা এবং প্রত্যাহার সহ বিভিন্ন কর্মক্ষমতা মেট্রিক্স গণনা করার জন্য পর্যাপ্ত তথ্য রয়েছে।
ক্রমাগত বৈশিষ্ট্য
সম্ভাব্য মানের অসীম পরিসর সহ একটি ভাসমান-বিন্দু বৈশিষ্ট্য , যেমন তাপমাত্রা বা ওজন।
পৃথক বৈশিষ্ট্য সঙ্গে বৈসাদৃশ্য.
অভিন্নতা
প্রতিটি পুনরাবৃত্তির সাথে ক্ষতির মানগুলি খুব কম বা একেবারেই না পরিবর্তিত হলে এমন একটি অবস্থায় পৌঁছে যায়। উদাহরণস্বরূপ, নিম্নলিখিত ক্ষতির বক্ররেখাটি প্রায় 700 পুনরাবৃত্তিতে একত্রিত হওয়ার পরামর্শ দেয়:
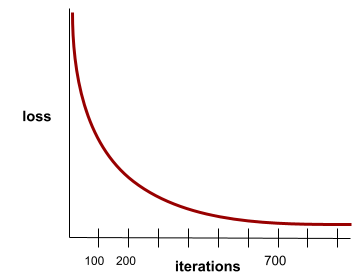
একটি মডেল একত্রিত হয় যখন অতিরিক্ত প্রশিক্ষণ মডেল উন্নত করবে না।
গভীর শিক্ষায় , ক্ষতির মান কখনও কখনও স্থির থাকে বা শেষ পর্যন্ত নামার আগে অনেক পুনরাবৃত্তির জন্য প্রায় তাই থাকে। ধ্রুবক ক্ষতির মানগুলির দীর্ঘ সময়ের মধ্যে, আপনি সাময়িকভাবে অভিসারের একটি মিথ্যা ধারণা পেতে পারেন।
তাড়াতাড়ি থামানোও দেখুন।
ডি
ডেটাফ্রেম
মেমরিতে ডেটাসেট উপস্থাপনের জন্য একটি জনপ্রিয় পান্ডা ডেটা টাইপ।
একটি ডেটাফ্রেম একটি টেবিল বা স্প্রেডশীটের সাথে সাদৃশ্যপূর্ণ। একটি ডেটাফ্রেমের প্রতিটি কলামের একটি নাম (একটি শিরোনাম) থাকে এবং প্রতিটি সারি একটি অনন্য সংখ্যা দ্বারা চিহ্নিত করা হয়।
একটি ডেটাফ্রেমের প্রতিটি কলাম একটি 2D অ্যারের মতো গঠন করা হয়, প্রতিটি কলামের নিজস্ব ডেটা টাইপ বরাদ্দ করা যেতে পারে।
অফিসিয়াল pandas.DataFrame রেফারেন্স পৃষ্ঠাও দেখুন।
ডেটা সেট বা ডেটাসেট
নিম্নোক্ত বিন্যাসগুলির মধ্যে একটিতে সাধারণত (কিন্তু একচেটিয়াভাবে নয়) সংগঠিত কাঁচা ডেটার একটি সংগ্রহ:
- একটি স্প্রেডশীট
- CSV (কমা-বিভক্ত মান) বিন্যাসে একটি ফাইল
গভীর মডেল
একটি নিউরাল নেটওয়ার্ক যাতে একাধিক লুকানো স্তর থাকে।
একটি গভীর মডেলকে গভীর নিউরাল নেটওয়ার্কও বলা হয়।
প্রশস্ত মডেলের সাথে বৈসাদৃশ্য।
ঘন বৈশিষ্ট্য
একটি বৈশিষ্ট্য যেখানে বেশিরভাগ বা সমস্ত মান অশূন্য, সাধারণত ফ্লোটিং-পয়েন্ট মানগুলির একটি টেনসর ৷ উদাহরণস্বরূপ, নিম্নলিখিত 10-উপাদান টেনসরটি ঘন কারণ এর 9টি মান অশূন্য:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
স্পার্স বৈশিষ্ট্যের সাথে বৈসাদৃশ্য।
গভীরতা
একটি নিউরাল নেটওয়ার্কে নিম্নলিখিতগুলির সমষ্টি:
- লুকানো স্তরের সংখ্যা
- আউটপুট স্তরের সংখ্যা, যা সাধারণত 1 হয়
- যেকোনো এম্বেডিং স্তরের সংখ্যা
উদাহরণস্বরূপ, পাঁচটি লুকানো স্তর এবং একটি আউটপুট স্তর সহ একটি নিউরাল নেটওয়ার্কের গভীরতা 6।
লক্ষ্য করুন যে ইনপুট স্তর গভীরতা প্রভাবিত করে না।
পৃথক বৈশিষ্ট্য
সম্ভাব্য মানগুলির একটি সীমিত সেট সহ একটি বৈশিষ্ট্য । উদাহরণস্বরূপ, একটি বৈশিষ্ট্য যার মান শুধুমাত্র প্রাণী , উদ্ভিজ্জ বা খনিজ হতে পারে একটি পৃথক (বা শ্রেণীবদ্ধ) বৈশিষ্ট্য।
ক্রমাগত বৈশিষ্ট্য সঙ্গে বৈসাদৃশ্য.
গতিশীল
ঘন ঘন বা ক্রমাগত কিছু করা। গতিশীল এবং অনলাইন শব্দগুলি মেশিন লার্নিং এর সমার্থক শব্দ। নিম্নলিখিতগুলি মেশিন লার্নিংয়ে গতিশীল এবং অনলাইনের সাধারণ ব্যবহার:
- একটি গতিশীল মডেল (বা অনলাইন মডেল ) হল একটি মডেল যা ঘন ঘন বা ক্রমাগত পুনরায় প্রশিক্ষণ দেওয়া হয়।
- ডায়নামিক ট্রেনিং (বা অনলাইন ট্রেনিং ) হল ঘন ঘন বা একটানা প্রশিক্ষণের প্রক্রিয়া।
- গতিশীল অনুমান (বা অনলাইন অনুমান ) হল চাহিদার উপর পূর্বাভাস তৈরি করার প্রক্রিয়া।
গতিশীল মডেল
একটি মডেল যা ঘন ঘন (সম্ভবত এমনকি ক্রমাগত) পুনরায় প্রশিক্ষিত হয়। একটি গতিশীল মডেল হল একটি "আজীবন শিক্ষার্থী" যা ক্রমাগত বিকশিত ডেটার সাথে খাপ খায়। একটি গতিশীল মডেল একটি অনলাইন মডেল হিসাবেও পরিচিত।
স্ট্যাটিক মডেলের সাথে বৈসাদৃশ্য।
ই
তাড়াতাড়ি থামানো
নিয়মিতকরণের একটি পদ্ধতি যা প্রশিক্ষণের ক্ষতি কমানোর আগে প্রশিক্ষণ শেষ করে। প্রারম্ভিক বন্ধে, আপনি ইচ্ছাকৃতভাবে মডেলের প্রশিক্ষণ বন্ধ করে দেন যখন একটি বৈধতা ডেটাসেটের ক্ষতি বাড়তে থাকে; যে, যখন সাধারণীকরণ কর্মক্ষমতা খারাপ হয়.
এম্বেডিং স্তর
একটি বিশেষ লুকানো স্তর যা একটি উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণ দেয় যা ধীরে ধীরে একটি নিম্ন মাত্রার এম্বেডিং ভেক্টর শিখতে পারে। একটি এম্বেডিং স্তর একটি নিউরাল নেটওয়ার্ককে শুধুমাত্র উচ্চ-মাত্রিক শ্রেণীগত বৈশিষ্ট্যের উপর প্রশিক্ষণের চেয়ে অনেক বেশি দক্ষতার সাথে প্রশিক্ষণ দিতে সক্ষম করে।
উদাহরণস্বরূপ, পৃথিবী বর্তমানে প্রায় 73,000 গাছের প্রজাতিকে সমর্থন করে। ধরুন গাছের প্রজাতি আপনার মডেলের একটি বৈশিষ্ট্য , তাই আপনার মডেলের ইনপুট স্তরে একটি এক-হট ভেক্টর 73,000 উপাদান রয়েছে। উদাহরণস্বরূপ, সম্ভবত baobab এই মত কিছু প্রতিনিধিত্ব করা হবে:

একটি 73,000-এলিমেন্ট অ্যারে খুব দীর্ঘ। আপনি যদি মডেলটিতে একটি এম্বেডিং স্তর যোগ না করেন, তাহলে 72,999 শূন্য গুণ করার কারণে প্রশিক্ষণটি খুব সময়সাপেক্ষ হতে চলেছে। সম্ভবত আপনি 12টি মাত্রা সমন্বিত করার জন্য এম্বেডিং স্তরটি বেছে নিন। ফলস্বরূপ, এম্বেডিং স্তরটি ধীরে ধীরে প্রতিটি গাছের প্রজাতির জন্য একটি নতুন এমবেডিং ভেক্টর শিখবে।
কিছু পরিস্থিতিতে, হ্যাশিং একটি এম্বেডিং স্তরের একটি যুক্তিসঙ্গত বিকল্প।
যুগ
পুরো প্রশিক্ষণ সেটের উপর একটি সম্পূর্ণ প্রশিক্ষণ পাস যাতে প্রতিটি উদাহরণ একবার প্রক্রিয়া করা হয়েছে।
একটি যুগ N / ব্যাচ আকারের প্রশিক্ষণের পুনরাবৃত্তির প্রতিনিধিত্ব করে, যেখানে N হল মোট উদাহরণের সংখ্যা।
উদাহরণস্বরূপ, নিম্নলিখিতটি ধরুন:
- ডেটাসেটটিতে 1,000টি উদাহরণ রয়েছে।
- ব্যাচ আকার 50 উদাহরণ.
অতএব, একটি একক যুগের জন্য 20টি পুনরাবৃত্তি প্রয়োজন:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
উদাহরণ
বৈশিষ্ট্যের একটি সারির মান এবং সম্ভবত একটি লেবেল । তত্ত্বাবধানে শিক্ষার উদাহরণ দুটি সাধারণ বিভাগে পড়ে:
- একটি লেবেলযুক্ত উদাহরণে এক বা একাধিক বৈশিষ্ট্য এবং একটি লেবেল থাকে। লেবেলযুক্ত উদাহরণ প্রশিক্ষণের সময় ব্যবহার করা হয়।
- লেবেলবিহীন উদাহরণে এক বা একাধিক বৈশিষ্ট্য থাকে কিন্তু কোনো লেবেল থাকে না। লেবেলবিহীন উদাহরণ অনুমানের সময় ব্যবহার করা হয়।
উদাহরণস্বরূপ, ধরুন আপনি শিক্ষার্থীদের পরীক্ষার স্কোরের উপর আবহাওয়ার অবস্থার প্রভাব নির্ধারণের জন্য একটি মডেলকে প্রশিক্ষণ দিচ্ছেন। এখানে তিনটি লেবেলযুক্ত উদাহরণ রয়েছে:
| বৈশিষ্ট্য | লেবেল | ||
|---|---|---|---|
| তাপমাত্রা | আর্দ্রতা | চাপ | টেস্ট স্কোর |
| 15 | 47 | 998 | ভাল |
| 19 | 34 | 1020 | চমৎকার |
| 18 | 92 | 1012 | দরিদ্র |
এখানে তিনটি লেবেলবিহীন উদাহরণ রয়েছে:
| তাপমাত্রা | আর্দ্রতা | চাপ | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
একটি ডেটাসেটের সারিটি সাধারণত একটি উদাহরণের জন্য কাঁচা উত্স। অর্থাৎ, একটি উদাহরণে সাধারণত ডেটাসেটের কলামগুলির একটি উপসেট থাকে। উপরন্তু, একটি উদাহরণের বৈশিষ্ট্যগুলিতে সিন্থেটিক বৈশিষ্ট্যগুলিও অন্তর্ভুক্ত থাকতে পারে, যেমন বৈশিষ্ট্য ক্রস ।
চ
মিথ্যা নেতিবাচক (এফএন)
একটি উদাহরণ যেখানে মডেলটি ভুলভাবে নেতিবাচক শ্রেণীর ভবিষ্যদ্বাণী করে। উদাহরণস্বরূপ, মডেলটি ভবিষ্যদ্বাণী করে যে একটি নির্দিষ্ট ইমেল বার্তা স্প্যাম নয় (নেতিবাচক শ্রেণি), কিন্তু সেই ইমেল বার্তাটি আসলে স্প্যাম ।
মিথ্যা পজিটিভ (FP)
একটি উদাহরণ যেখানে মডেল ভুলভাবে ইতিবাচক শ্রেণীর ভবিষ্যদ্বাণী করে। উদাহরণস্বরূপ, মডেলটি ভবিষ্যদ্বাণী করে যে একটি নির্দিষ্ট ইমেল বার্তাটি স্প্যাম (পজিটিভ ক্লাস), কিন্তু সেই ইমেল বার্তাটি আসলে স্প্যাম নয় ৷
মিথ্যা ইতিবাচক হার (FPR)
প্রকৃত নেতিবাচক উদাহরণের অনুপাত যার জন্য মডেলটি ভুলভাবে ইতিবাচক শ্রেণীর ভবিষ্যদ্বাণী করেছে। নিম্নলিখিত সূত্রটি মিথ্যা ইতিবাচক হার গণনা করে:
মিথ্যা ধনাত্মক হার হল একটি ROC বক্ররেখার x-অক্ষ।
বৈশিষ্ট্য
একটি মেশিন লার্নিং মডেলের একটি ইনপুট পরিবর্তনশীল। একটি উদাহরণ এক বা একাধিক বৈশিষ্ট্য নিয়ে গঠিত। উদাহরণস্বরূপ, ধরুন আপনি শিক্ষার্থীদের পরীক্ষার স্কোরের উপর আবহাওয়ার অবস্থার প্রভাব নির্ধারণের জন্য একটি মডেলকে প্রশিক্ষণ দিচ্ছেন। নিম্নলিখিত সারণী তিনটি উদাহরণ দেখায়, যার প্রতিটিতে তিনটি বৈশিষ্ট্য এবং একটি লেবেল রয়েছে:
| বৈশিষ্ট্য | লেবেল | ||
|---|---|---|---|
| তাপমাত্রা | আর্দ্রতা | চাপ | টেস্ট স্কোর |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
লেবেলের সাথে বৈসাদৃশ্য।
বৈশিষ্ট্য ক্রস
একটি সিন্থেটিক বৈশিষ্ট্য "ক্রসিং" শ্রেণীবদ্ধ বা বালতি বৈশিষ্ট্য দ্বারা গঠিত।
উদাহরণস্বরূপ, একটি "মেজাজ পূর্বাভাস" মডেল বিবেচনা করুন যা নিম্নলিখিত চারটি বালতিগুলির মধ্যে একটিতে তাপমাত্রা উপস্থাপন করে:
-
freezing -
chilly -
temperate -
warm
এবং নিম্নলিখিত তিনটি বালতিগুলির মধ্যে একটিতে বাতাসের গতি উপস্থাপন করে:
-
still -
light -
windy
বৈশিষ্ট্য ক্রস ছাড়াই, রৈখিক মডেল পূর্ববর্তী সাতটি বিভিন্ন বালতিগুলির প্রতিটিতে স্বাধীনভাবে ট্রেন করে। সুতরাং, মডেলটি ট্রেনিং করে, উদাহরণস্বরূপ, প্রশিক্ষণের থেকে স্বাধীনভাবে freezing , উদাহরণস্বরূপ, windy ।
বিকল্পভাবে, আপনি তাপমাত্রা এবং বাতাসের গতির একটি বৈশিষ্ট্য ক্রস তৈরি করতে পারেন। এই সিন্থেটিক বৈশিষ্ট্যের নিম্নলিখিত 12টি সম্ভাব্য মান থাকবে:
-
freezing-still -
freezing-light -
freezing-windy -
chilly-still -
chilly-light -
chilly-windy -
temperate-still -
temperate-light -
temperate-windy -
warm-still -
warm-light -
warm-windy
ফিচার ক্রসের জন্য ধন্যবাদ, মডেলটি freezing-windy দিন এবং freezing-still দিনের মধ্যে মেজাজের পার্থক্য শিখতে পারে।
আপনি যদি দুটি বৈশিষ্ট্য থেকে একটি সিন্থেটিক বৈশিষ্ট্য তৈরি করেন যার প্রতিটিতে অনেকগুলি আলাদা বালতি থাকে, ফলে বৈশিষ্ট্য ক্রসটিতে বিপুল সংখ্যক সম্ভাব্য সংমিশ্রণ থাকবে। উদাহরণস্বরূপ, যদি একটি বৈশিষ্ট্যে 1,000 বালতি থাকে এবং অন্য বৈশিষ্ট্যটিতে 2,000 বালতি থাকে, ফলে বৈশিষ্ট্য ক্রসটিতে 2,000,000 বালতি থাকে৷
আনুষ্ঠানিকভাবে, একটি ক্রস একটি কার্টেসিয়ান পণ্য ।
ফিচার ক্রসগুলি বেশিরভাগ লিনিয়ার মডেলের সাথে ব্যবহৃত হয় এবং খুব কমই নিউরাল নেটওয়ার্কের সাথে ব্যবহার করা হয়।
বৈশিষ্ট্য প্রকৌশল
একটি প্রক্রিয়া যা নিম্নলিখিত পদক্ষেপগুলিকে অন্তর্ভুক্ত করে:
- মডেল প্রশিক্ষণের জন্য কোন বৈশিষ্ট্যগুলি কার্যকর হতে পারে তা নির্ধারণ করা।
- ডেটাসেট থেকে কাঁচা ডেটাকে সেই বৈশিষ্ট্যগুলির দক্ষ সংস্করণে রূপান্তর করা।
উদাহরণস্বরূপ, আপনি নির্ধারণ করতে পারেন যে temperature একটি দরকারী বৈশিষ্ট্য হতে পারে। তারপর, মডেলটি বিভিন্ন temperature রেঞ্জ থেকে কী শিখতে পারে তা অপ্টিমাইজ করতে আপনি বাকেটিংয়ের সাথে পরীক্ষা করতে পারেন।
ফিচার ইঞ্জিনিয়ারিংকে কখনও কখনও ফিচার এক্সট্রাকশন বা ফিচারাইজেশন বলা হয়।
বৈশিষ্ট্য সেট
আপনার মেশিন লার্নিং মডেল ট্রেনের বৈশিষ্ট্যগুলির গ্রুপ। উদাহরণস্বরূপ, পোস্টাল কোড, সম্পত্তির আকার এবং সম্পত্তির অবস্থার মধ্যে একটি মডেলের জন্য একটি সাধারণ বৈশিষ্ট্য সেট থাকতে পারে যা আবাসন মূল্যের পূর্বাভাস দেয়।
বৈশিষ্ট্য ভেক্টর
একটি উদাহরণ সমন্বিত বৈশিষ্ট্য মানের অ্যারে। প্রশিক্ষণের সময় এবং অনুমানের সময় বৈশিষ্ট্য ভেক্টর ইনপুট হয়। উদাহরণস্বরূপ, দুটি পৃথক বৈশিষ্ট্য সহ একটি মডেলের বৈশিষ্ট্য ভেক্টর হতে পারে:
[0.92, 0.56]
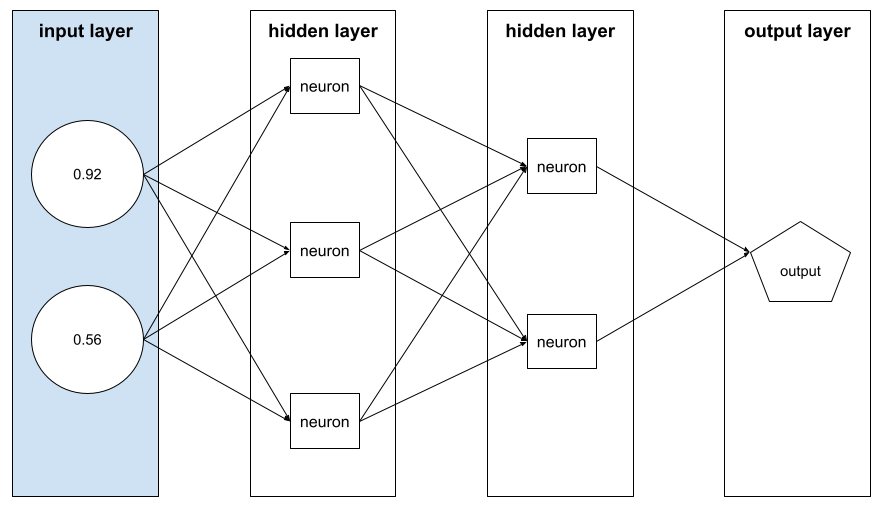
প্রতিটি উদাহরণ বৈশিষ্ট্য ভেক্টরের জন্য বিভিন্ন মান সরবরাহ করে, তাই পরবর্তী উদাহরণের জন্য বৈশিষ্ট্য ভেক্টর এমন কিছু হতে পারে:
[0.73, 0.49]
ফিচার ইঞ্জিনিয়ারিং ফিচার ভেক্টরে বৈশিষ্ট্যগুলিকে কীভাবে উপস্থাপন করতে হয় তা নির্ধারণ করে। উদাহরণস্বরূপ, পাঁচটি সম্ভাব্য মান সহ একটি বাইনারি শ্রেণীবদ্ধ বৈশিষ্ট্য এক-হট এনকোডিং দিয়ে উপস্থাপন করা যেতে পারে। এই ক্ষেত্রে, একটি নির্দিষ্ট উদাহরণের জন্য বৈশিষ্ট্য ভেক্টরের অংশে চারটি শূন্য এবং তৃতীয় অবস্থানে একটি একক 1.0 থাকবে, নিম্নরূপ:
[0.0, 0.0, 1.0, 0.0, 0.0]
অন্য উদাহরণ হিসাবে, ধরুন আপনার মডেল তিনটি বৈশিষ্ট্য নিয়ে গঠিত:
- এক-হট এনকোডিং দ্বারা উপস্থাপিত পাঁচটি সম্ভাব্য মান সহ একটি বাইনারি শ্রেণীবদ্ধ বৈশিষ্ট্য; উদাহরণস্বরূপ:
[0.0, 1.0, 0.0, 0.0, 0.0] - তিনটি সম্ভাব্য মান সহ আরেকটি বাইনারি শ্রেণীবদ্ধ বৈশিষ্ট্য যা এক-হট এনকোডিং দ্বারা উপস্থাপিত হয়; উদাহরণস্বরূপ:
[0.0, 0.0, 1.0] - একটি ভাসমান-বিন্দু বৈশিষ্ট্য; উদাহরণস্বরূপ:
8.3।
এই ক্ষেত্রে, প্রতিটি উদাহরণের জন্য বৈশিষ্ট্য ভেক্টর নয়টি মান দ্বারা প্রতিনিধিত্ব করা হবে। পূর্ববর্তী তালিকায় উদাহরণ মান দেওয়া, বৈশিষ্ট্য ভেক্টর হবে:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
প্রতিক্রিয়া লুপ
মেশিন লার্নিং-এ, এমন একটি পরিস্থিতি যেখানে একটি মডেলের ভবিষ্যদ্বাণী একই মডেল বা অন্য মডেলের প্রশিক্ষণ ডেটাকে প্রভাবিত করে। উদাহরণ স্বরূপ, একটি মডেল যেটি চলচ্চিত্রের সুপারিশ করে সেগুলিকে প্রভাবিত করবে যা লোকেরা দেখে, যা পরবর্তী মুভি সুপারিশ মডেলগুলিকে প্রভাবিত করবে।
জি
সাধারণীকরণ
একটি মডেলের নতুন, পূর্বে অদেখা তথ্যে সঠিক ভবিষ্যদ্বাণী করার ক্ষমতা। একটি মডেল যা সাধারণীকরণ করতে পারে তা হল একটি মডেলের বিপরীত যা ওভারফিটিং ।
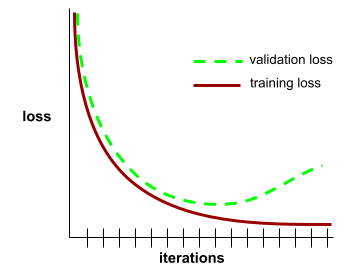
সাধারণীকরণ বক্ররেখা
পুনরাবৃত্তির সংখ্যার একটি ফাংশন হিসাবে প্রশিক্ষণ ক্ষতি এবং বৈধতা ক্ষতি উভয়ের একটি প্লট।
একটি সাধারণীকরণ বক্ররেখা আপনাকে সম্ভাব্য ওভারফিটিং সনাক্ত করতে সাহায্য করতে পারে। উদাহরণস্বরূপ, নিম্নোক্ত সাধারণীকরণ বক্ররেখাটি ওভারফিটিং প্রস্তাব করে কারণ বৈধতা ক্ষতি শেষ পর্যন্ত প্রশিক্ষণের ক্ষতির চেয়ে উল্লেখযোগ্যভাবে বেশি হয়।
গ্রেডিয়েন্ট ডিসেন্ট
ক্ষতি হ্রাস করার জন্য একটি গাণিতিক কৌশল। গ্রেডিয়েন্ট বংশোদ্ভূত পুনরাবৃত্তভাবে ওজন এবং পক্ষপাতিত্বগুলি সামঞ্জস্য করে, ধীরে ধীরে ক্ষতি হ্রাস করার জন্য সেরা সংমিশ্রণটি সন্ধান করে।
গ্রেডিয়েন্ট বংশোদ্ভূত মেশিন লার্নিংয়ের চেয়ে অনেক বেশি, অনেক বেশি বয়স্ক।
স্থল সত্য
বাস্তবতা।
জিনিসটি আসলে ঘটেছে।
উদাহরণস্বরূপ, একটি বাইনারি শ্রেণিবদ্ধকরণ মডেল বিবেচনা করুন যা ভবিষ্যদ্বাণী করে যে তাদের বিশ্ববিদ্যালয়ের প্রথম বর্ষের কোনও শিক্ষার্থী ছয় বছরের মধ্যে স্নাতক হবে কিনা। এই মডেলটির স্থল সত্যটি হ'ল সেই শিক্ষার্থী আসলে ছয় বছরের মধ্যে স্নাতক হয়েছে কিনা।
এইচ
লুকানো স্তর
ইনপুট স্তর (বৈশিষ্ট্যগুলি) এবং আউটপুট স্তর (পূর্বাভাস) এর মধ্যে একটি নিউরাল নেটওয়ার্কের একটি স্তর। প্রতিটি লুকানো স্তরটিতে এক বা একাধিক নিউরন থাকে। উদাহরণস্বরূপ, নিম্নলিখিত নিউরাল নেটওয়ার্কে দুটি লুকানো স্তর রয়েছে, প্রথমটি তিনটি নিউরন সহ এবং দ্বিতীয়টি দুটি নিউরন সহ:
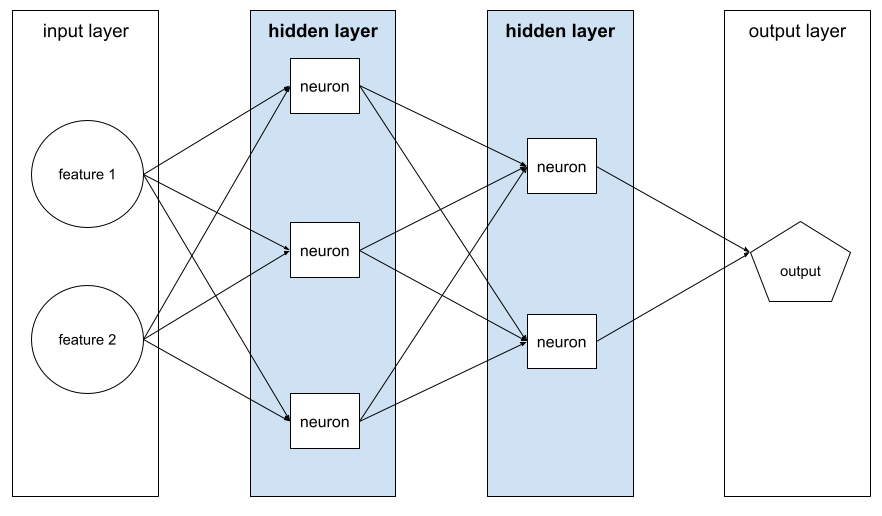
একটি গভীর নিউরাল নেটওয়ার্কে একাধিক লুকানো স্তর রয়েছে। উদাহরণস্বরূপ, পূর্ববর্তী চিত্রটি একটি গভীর নিউরাল নেটওয়ার্ক কারণ মডেলটিতে দুটি লুকানো স্তর রয়েছে।
হাইপারপ্যারামিটার
আপনি বা একটি হাইপারপ্যারামিটার টিউনিং পরিষেবা যে ভেরিয়েবলগুলিএকটি মডেল প্রশিক্ষণের পরপর রান করার সময় সামঞ্জস্য করুন। উদাহরণস্বরূপ, শেখার হার একটি হাইপারপ্যারামিটার। আপনি একটি প্রশিক্ষণ সেশনের আগে শেখার হার 0.01 এ সেট করতে পারেন। যদি আপনি নির্ধারণ করেন যে 0.01 খুব বেশি, আপনি সম্ভবত পরবর্তী প্রশিক্ষণ সেশনের জন্য শেখার হারটি 0.003 এ সেট করতে পারেন।
বিপরীতে, প্যারামিটারগুলি হ'ল বিভিন্ন ওজন এবং পক্ষপাত যা মডেল প্রশিক্ষণের সময় শিখেন ।
আমি
স্বাধীনভাবে এবং অভিন্নভাবে বিতরণ (আইআইডি)
এমন একটি বিতরণ থেকে আঁকা ডেটা যা পরিবর্তন হয় না এবং যেখানে প্রতিটি মান আঁকা সেই মানগুলির উপর নির্ভর করে না যা আগে আঁকা হয়েছে। একটি আইআইডি হ'ল মেশিন লার্নিংয়ের আদর্শ গ্যাস - এটি একটি দরকারী গাণিতিক নির্মাণ তবে প্রায় আসল বিশ্বে ঠিক কখনও পাওয়া যায় না। উদাহরণস্বরূপ, একটি ওয়েব পৃষ্ঠায় দর্শনার্থীদের বিতরণ সময়ের একটি সংক্ষিপ্ত উইন্ডোতে আইআইডি হতে পারে; অর্থাৎ, সেই সংক্ষিপ্ত উইন্ডো চলাকালীন বিতরণটি পরিবর্তন হয় না এবং একজন ব্যক্তির দর্শন সাধারণত অন্যের দর্শন থেকে স্বতন্ত্র। তবে, আপনি যদি সময়ের সেই উইন্ডোটি প্রসারিত করেন তবে ওয়েব পৃষ্ঠার দর্শনার্থীদের মধ্যে মৌসুমী পার্থক্য উপস্থিত হতে পারে।
অবিচ্ছিন্নতাও দেখুন।
অনুমান
মেশিন লার্নিংয়ে, লেবেলযুক্ত উদাহরণগুলিতে প্রশিক্ষিত মডেল প্রয়োগ করে ভবিষ্যদ্বাণী করার প্রক্রিয়া।
অনুমানের পরিসংখ্যানের কিছুটা আলাদা অর্থ রয়েছে। বিশদের জন্য পরিসংখ্যানগত অনুমানের উপর উইকিপিডিয়া নিবন্ধটি দেখুন।
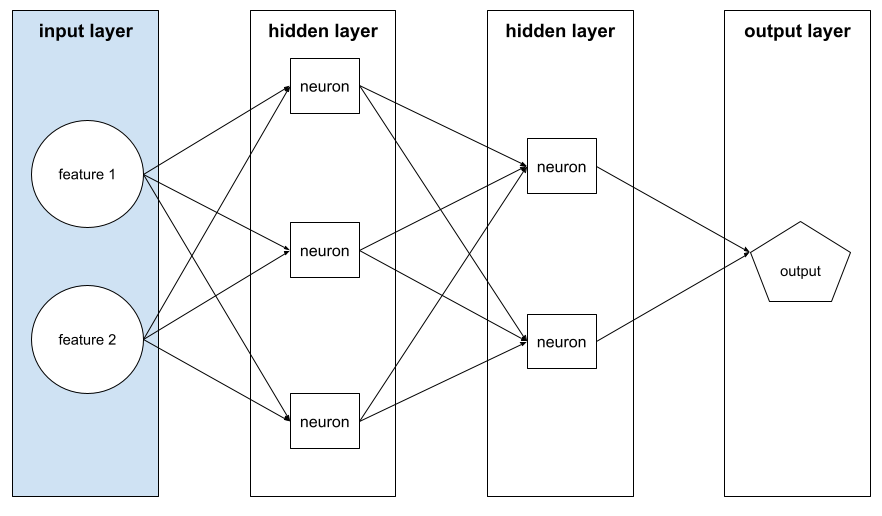
ইনপুট স্তর
একটি নিউরাল নেটওয়ার্কের স্তর যা বৈশিষ্ট্য ভেক্টর ধারণ করে। অর্থাৎ, ইনপুট স্তরটি প্রশিক্ষণ বা অনুমানের জন্য উদাহরণ সরবরাহ করে। উদাহরণস্বরূপ, নিম্নলিখিত নিউরাল নেটওয়ার্কে ইনপুট স্তরটিতে দুটি বৈশিষ্ট্য রয়েছে:
ব্যাখ্যাযোগ্যতা
কোনও এমএল মডেলের যুক্তি কোনও মানুষের কাছে বোধগম্য শর্তে ব্যাখ্যা করার বা উপস্থাপন করার ক্ষমতা।
উদাহরণস্বরূপ, বেশিরভাগ লিনিয়ার রিগ্রেশন মডেলগুলি অত্যন্ত ব্যাখ্যাযোগ্য। (আপনাকে কেবল প্রতিটি বৈশিষ্ট্যের জন্য প্রশিক্ষিত ওজনের দিকে নজর দেওয়া দরকার)) সিদ্ধান্ত বনগুলিও অত্যন্ত ব্যাখ্যাযোগ্য। কিছু মডেলের অবশ্য ব্যাখ্যাযোগ্য হওয়ার জন্য পরিশীলিত ভিজ্যুয়ালাইজেশন প্রয়োজন।
আপনি এমএল মডেলগুলি ব্যাখ্যা করতে লার্নিং ব্যাখ্যার সরঞ্জাম (এলআইটি) ব্যবহার করতে পারেন।
পুনরাবৃত্তি
কোনও মডেলের প্যারামিটারগুলির একক আপডেট - মডেলের ওজন এবং পক্ষপাতিত্ব - প্রশিক্ষণ । ব্যাচের আকার নির্ধারণ করে যে একক পুনরাবৃত্তিতে মডেল প্রক্রিয়াগুলি কতগুলি উদাহরণ। উদাহরণস্বরূপ, যদি ব্যাচের আকার 20 হয়, তবে মডেলটি পরামিতিগুলি সামঞ্জস্য করার আগে 20 টি উদাহরণ প্রক্রিয়া করে।
নিউরাল নেটওয়ার্ক প্রশিক্ষণ দেওয়ার সময়, একটি একক পুনরাবৃত্তির মধ্যে নিম্নলিখিত দুটি পাস জড়িত:
- একটি একক ব্যাচের ক্ষতির মূল্যায়ন করার জন্য একটি ফরোয়ার্ড পাস।
- ক্ষতি এবং শেখার হারের উপর ভিত্তি করে মডেলের পরামিতিগুলি সামঞ্জস্য করতে একটি পশ্চাদপদ পাস ( ব্যাকপ্রোপেজেশন )।
এল
L 0 নিয়মিতকরণ
এক ধরণের নিয়মিতকরণ যা কোনও মডেলের মোট ননজারো ওজনের সংখ্যাকে শাস্তি দেয়। উদাহরণস্বরূপ, ১১ টি ননজারো ওজনযুক্ত একটি মডেলকে 10 টি ননজারো ওজনযুক্ত অনুরূপ মডেলের চেয়ে বেশি শাস্তি দেওয়া হবে।
L 0 নিয়মিতকরণকে কখনও কখনও L0-নরমাল নিয়মিতকরণ বলা হয়।
L 1 ক্ষতি
একটি ক্ষতির ফাংশন যা প্রকৃত লেবেল মান এবং কোনও মডেল পূর্বাভাস দেয় এমন মানগুলির মধ্যে পার্থক্যের নিখুঁত মান গণনা করে। উদাহরণস্বরূপ, পাঁচটি উদাহরণের ব্যাচের জন্য এল 1 ক্ষতির গণনা এখানে:
| উদাহরণের প্রকৃত মান | মডেলের পূর্বাভাস মান | ডেল্টার পরম মান |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = এল 1 ক্ষতি | ||
এল 1 ক্ষতি এল 2 ক্ষতির চেয়ে বহিরাগতদের কাছে কম সংবেদনশীল।
গড় পরম ত্রুটি হ'ল উদাহরণ প্রতি গড় এল 1 ক্ষতি।
এল 1 নিয়মিতকরণ
এক ধরণের নিয়মিতকরণ যা ওজনের পরম মানের যোগফলের অনুপাতে ওজনকে শাস্তি দেয়। L 1 নিয়মিতকরণ অপ্রাসঙ্গিক বা সবেমাত্র প্রাসঙ্গিক বৈশিষ্ট্যগুলির ওজনকে ঠিক 0 তে চালিত করতে সহায়তা করে। 0 এর ওজন সহ একটি বৈশিষ্ট্য কার্যকরভাবে মডেল থেকে সরানো হয়।
এল 2 নিয়মিতকরণের সাথে বিপরীতে।
L 2 ক্ষতি
একটি ক্ষতির ফাংশন যা প্রকৃত লেবেল মান এবং কোনও মডেল পূর্বাভাস দেয় এমন মানগুলির মধ্যে পার্থক্যের বর্গকে গণনা করে। উদাহরণস্বরূপ, পাঁচটি উদাহরণের ব্যাচের জন্য এল 2 ক্ষতির গণনা এখানে:
| উদাহরণের প্রকৃত মান | মডেলের পূর্বাভাস মান | ডেল্টার বর্গক্ষেত্র |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = l 2 ক্ষতি | ||
স্কোয়ারিংয়ের কারণে, এল 2 ক্ষতি বহিরাগতদের প্রভাবকে প্রশস্ত করে। এটি হ'ল এল 2 ক্ষতি এল 1 ক্ষতির চেয়ে খারাপ ভবিষ্যদ্বাণীগুলিতে আরও দৃ strongly ় প্রতিক্রিয়া জানায়। উদাহরণস্বরূপ, পূর্ববর্তী ব্যাচের জন্য এল 1 ক্ষতি 16 এর পরিবর্তে 8 হবে Notice লক্ষ্য করুন যে একটি একক আউটলেট 16 এর 9 টির জন্য অ্যাকাউন্ট করে।
রিগ্রেশন মডেলগুলি সাধারণত এল 2 ক্ষতি ক্ষতি ফাংশন হিসাবে ব্যবহার করে।
গড় স্কোয়ার ত্রুটি হ'ল উদাহরণ প্রতি গড় এল 2 ক্ষতি। স্কোয়ার ক্ষতি এল 2 ক্ষতির জন্য অন্য নাম।
এল 2 নিয়মিতকরণ
এক ধরণের নিয়মিতকরণ যা ওজনের স্কোয়ারের যোগফলের অনুপাতে ওজনকে দণ্ড দেয়। L 2 নিয়মিতকরণ আউটলায়ার ওজন (উচ্চ ধনাত্মক বা কম নেতিবাচক মান সহ) 0 এর কাছাকাছি তবে 0 এর কাছাকাছি নয় । 0 এর খুব কাছাকাছি মানগুলির বৈশিষ্ট্যগুলি মডেলটিতে থেকে যায় তবে মডেলের ভবিষ্যদ্বাণীকে খুব বেশি প্রভাবিত করে না।
L 2 নিয়মিতকরণ সর্বদা লিনিয়ার মডেলগুলিতে সাধারণীকরণকে উন্নত করে।
এল 1 নিয়মিতকরণের সাথে বিপরীতে।
লেবেল
তদারকি করা মেশিন লার্নিংয়ে , "উত্তর" বা "ফলাফল" একটি উদাহরণের অংশ।
প্রতিটি লেবেলযুক্ত উদাহরণে এক বা একাধিক বৈশিষ্ট্য এবং একটি লেবেল থাকে। উদাহরণস্বরূপ, একটি স্প্যাম সনাক্তকরণ ডেটাসেটে লেবেলটি সম্ভবত "স্প্যাম" বা "স্প্যাম নয়" হবে। একটি বৃষ্টিপাতের ডেটাসেটে, লেবেলটি নির্দিষ্ট সময়ের মধ্যে যে পরিমাণ বৃষ্টিপাত হয়েছিল তা হতে পারে।
লেবেল উদাহরণ
একটি উদাহরণ যা এক বা একাধিক বৈশিষ্ট্য এবং একটি লেবেল ধারণ করে। উদাহরণস্বরূপ, নিম্নলিখিত টেবিলটি বাড়ির মূল্যায়ন মডেল থেকে তিনটি লেবেলযুক্ত উদাহরণ দেখায়, যার প্রতিটি তিনটি বৈশিষ্ট্য এবং একটি লেবেল:
| বেডরুমের সংখ্যা | বাথরুমের সংখ্যা | বাড়ির বয়স | বাড়ির দাম (লেবেল) |
|---|---|---|---|
| 3 | 2 | 15 | $345,000 |
| 2 | 1 | 72 | $179,000 |
| 4 | 2 | 34 | $392,000 |
তদারকি করা মেশিন লার্নিংয়ে , মডেলগুলি লেবেলযুক্ত উদাহরণগুলিতে প্রশিক্ষণ দেয় এবং লেবেলযুক্ত উদাহরণগুলিতে ভবিষ্যদ্বাণী করে।
লেবেলযুক্ত উদাহরণ সহ কনট্রাস্ট লেবেলযুক্ত উদাহরণ।
ল্যাম্বডা
নিয়মিতকরণের হারের প্রতিশব্দ।
ল্যাম্বদা একটি ওভারলোডেড শব্দ। এখানে আমরা নিয়মিতকরণের মধ্যে শব্দটির সংজ্ঞাটিতে মনোনিবেশ করছি।
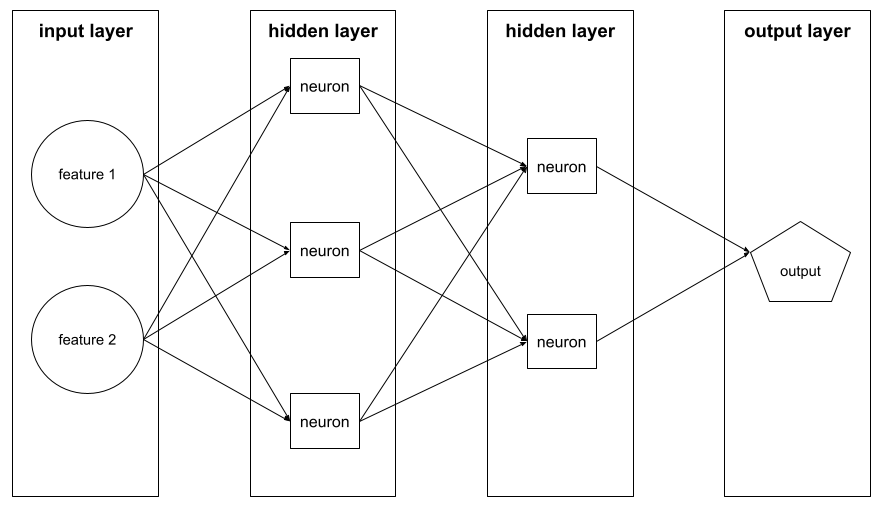
স্তর
নিউরাল নেটওয়ার্কে নিউরনের একটি সেট। তিনটি সাধারণ ধরণের স্তর নিম্নরূপ:
- ইনপুট স্তর , যা সমস্ত বৈশিষ্ট্যের জন্য মান সরবরাহ করে।
- এক বা একাধিক লুকানো স্তরগুলি , যা বৈশিষ্ট্য এবং লেবেলের মধ্যে অরৈখিক সম্পর্ক খুঁজে পায়।
- আউটপুট স্তর , যা ভবিষ্যদ্বাণী সরবরাহ করে।
উদাহরণস্বরূপ, নিম্নলিখিত চিত্রটি একটি ইনপুট স্তর, দুটি লুকানো স্তর এবং একটি আউটপুট স্তর সহ একটি নিউরাল নেটওয়ার্ক দেখায়:
টেনসরফ্লোতে , স্তরগুলি পাইথন ফাংশনও যা টেনসর এবং কনফিগারেশন বিকল্পগুলি ইনপুট হিসাবে গ্রহণ করে এবং আউটপুট হিসাবে অন্যান্য টেনারগুলি উত্পাদন করে।
শেখার হার
একটি ভাসমান-পয়েন্ট নম্বর যা গ্রেডিয়েন্ট বংশোদ্ভূত অ্যালগরিদমকে বলে যে প্রতিটি পুনরাবৃত্তিতে ওজন এবং পক্ষপাতিত্বগুলি সামঞ্জস্য করা কতটা দৃ strongly ়ভাবে। উদাহরণস্বরূপ, 0.3 এর একটি শিক্ষার হার 0.1 এর শিক্ষার হারের চেয়ে তিনগুণ বেশি ওজন এবং পক্ষপাতগুলি সামঞ্জস্য করবে।
শেখার হার একটি মূল হাইপারপ্যারামিটার । আপনি যদি শিক্ষার হারকে খুব কম সেট করেন তবে প্রশিক্ষণটি খুব বেশি সময় লাগবে। আপনি যদি শিক্ষার হারকে খুব বেশি সেট করেন তবে গ্রেডিয়েন্ট বংশোদ্ভূত প্রায়শই রূপান্তর করতে সমস্যা হয়।
রৈখিক
দুটি বা ততোধিক ভেরিয়েবলের মধ্যে একটি সম্পর্ক যা কেবলমাত্র সংযোজন এবং গুণের মাধ্যমে প্রতিনিধিত্ব করা যায়।
লিনিয়ার সম্পর্কের প্লটটি একটি লাইন।
ননলাইনারের সাথে বিপরীতে।
রৈখিক মডেল
এমন একটি মডেল যা ভবিষ্যদ্বাণীগুলি তৈরি করতে বৈশিষ্ট্য অনুসারে একটি ওজন নির্ধারণ করে। (লিনিয়ার মডেলগুলিও একটি পক্ষপাতিত্ব অন্তর্ভুক্ত করে)) বিপরীতে, গভীর মডেলগুলির পূর্বাভাসের সাথে বৈশিষ্ট্যগুলির সম্পর্ক সাধারণত অরৈখিক ।
লিনিয়ার মডেলগুলি সাধারণত প্রশিক্ষণ দেওয়া সহজ এবং গভীর মডেলের চেয়ে আরও ব্যাখ্যাযোগ্য । তবে গভীর মডেলগুলি বৈশিষ্ট্যগুলির মধ্যে জটিল সম্পর্ক শিখতে পারে।
লিনিয়ার রিগ্রেশন এবং লজিস্টিক রিগ্রেশন দুটি ধরণের লিনিয়ার মডেল।
লিনিয়ার রিগ্রেশন
এক ধরণের মেশিন লার্নিং মডেল যেখানে নিম্নলিখিত উভয়ই সত্য:
- মডেলটি একটি লিনিয়ার মডেল ।
- ভবিষ্যদ্বাণীটি একটি ভাসমান-পয়েন্ট মান। (এটি লিনিয়ার রিগ্রেশনের রিগ্রেশন অংশ))
লজিস্টিক রিগ্রেশন সহ লিনিয়ার রিগ্রেশন বিপরীতে। এছাড়াও, শ্রেণিবিন্যাসের সাথে বিপরীতে রিগ্রেশন।
লজিস্টিক রিগ্রেশন
এক ধরণের রিগ্রেশন মডেল যা সম্ভাবনার পূর্বাভাস দেয়। লজিস্টিক রিগ্রেশন মডেলগুলির নিম্নলিখিত বৈশিষ্ট্য রয়েছে:
- লেবেলটি শ্রেণিবদ্ধ । লজিস্টিক রিগ্রেশন শব্দটি সাধারণত বাইনারি লজিস্টিক রিগ্রেশনকে বোঝায়, অর্থাৎ এমন একটি মডেল যা দুটি সম্ভাব্য মান সহ লেবেলের সম্ভাব্যতা গণনা করে। একটি কম সাধারণ বৈকল্পিক, বহুজাতিক লজিস্টিক রিগ্রেশন , দুটি সম্ভাব্য মান সহ লেবেলের জন্য সম্ভাব্যতা গণনা করে।
- প্রশিক্ষণের সময় ক্ষতির ফাংশন হ'ল লগ ক্ষতি । (একাধিক লগ লোকসান ইউনিট দুটি সম্ভাব্য মান সহ লেবেলের জন্য সমান্তরালে স্থাপন করা যেতে পারে))
- মডেলটির একটি লিনিয়ার আর্কিটেকচার রয়েছে, গভীর নিউরাল নেটওয়ার্ক নয়। যাইহোক, এই সংজ্ঞাটির বাকী অংশগুলি গভীর মডেলগুলিতেও প্রযোজ্য যা শ্রেণিবদ্ধ লেবেলের জন্য সম্ভাবনার পূর্বাভাস দেয়।
উদাহরণস্বরূপ, একটি লজিস্টিক রিগ্রেশন মডেল বিবেচনা করুন যা স্প্যাম বা স্প্যাম না হয় এমন কোনও ইনপুট ইমেলের সম্ভাবনা গণনা করে। অনুমানের সময়, ধরুন মডেলটি 0.72 পূর্বাভাস দেয়। অতএব, মডেলটি অনুমান করছে:
- ইমেলের 72% সুযোগ স্প্যাম হওয়ার সম্ভাবনা।
- ইমেলের একটি 28% সুযোগ স্প্যাম না হওয়ার সম্ভাবনা।
একটি লজিস্টিক রিগ্রেশন মডেল নিম্নলিখিত দ্বি-পদক্ষেপের আর্কিটেকচার ব্যবহার করে:
- মডেল ইনপুট বৈশিষ্ট্যগুলির লিনিয়ার ফাংশন প্রয়োগ করে একটি কাঁচা ভবিষ্যদ্বাণী (y ') উত্পন্ন করে।
- মডেলটি সেই কাঁচা ভবিষ্যদ্বাণীটিকে সিগময়েড ফাংশনে ইনপুট হিসাবে ব্যবহার করে, যা কাঁচা ভবিষ্যদ্বাণীকে 0 এবং 1 এর মধ্যে একটি মান হিসাবে রূপান্তর করে।
যে কোনও রিগ্রেশন মডেলের মতো, একটি লজিস্টিক রিগ্রেশন মডেল একটি সংখ্যার পূর্বাভাস দেয়। তবে এই সংখ্যাটি সাধারণত বাইনারি শ্রেণিবিন্যাস মডেলের অংশ হয়ে যায়:
- যদি পূর্বাভাসিত সংখ্যাটি শ্রেণিবিন্যাসের প্রান্তিকের চেয়ে বেশি হয় তবে বাইনারি শ্রেণিবিন্যাসের মডেলটি ইতিবাচক শ্রেণীর পূর্বাভাস দেয়।
- যদি পূর্বাভাসিত সংখ্যাটি শ্রেণিবিন্যাসের প্রান্তিকের চেয়ে কম হয় তবে বাইনারি শ্রেণিবিন্যাস মডেল নেতিবাচক শ্রেণীর পূর্বাভাস দেয়।
লগ ক্ষতি
বাইনারি লজিস্টিক রিগ্রেশনে ব্যবহৃত ক্ষতি ফাংশন ।
log-odds
কিছু ইভেন্টের প্রতিকূলতার লোগারিদম।
ক্ষতি
তদারকি করা মডেলের প্রশিক্ষণের সময়, কোনও মডেলের ভবিষ্যদ্বাণীটি তার লেবেল থেকে কতটা দূরে রয়েছে তার একটি পরিমাপ।
একটি ক্ষতি ফাংশন ক্ষতি গণনা করে।
ক্ষতি বক্ররেখা
প্রশিক্ষণের পুনরাবৃত্তির সংখ্যার ফাংশন হিসাবে ক্ষতির একটি প্লট। নিম্নলিখিত প্লটটি একটি সাধারণ ক্ষতির বক্ররেখা দেখায়:
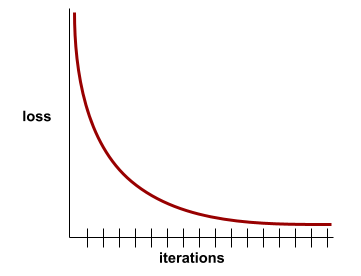
ক্ষতির বক্ররেখা আপনাকে কখন আপনার মডেল রূপান্তর করছে বা ওভারফিটিং করছে তা নির্ধারণ করতে সহায়তা করতে পারে।
ক্ষতির বক্ররেখা নিম্নলিখিত ধরণের ক্ষতির সমস্ত প্লট করতে পারে:
সাধারণীকরণ বক্ররেখাও দেখুন।
ক্ষতি ফাংশন
প্রশিক্ষণ বা পরীক্ষার সময়, একটি গাণিতিক ফাংশন যা উদাহরণগুলির একটি ব্যাচে ক্ষতির গণনা করে। ক্ষতি ফাংশন এমন মডেলগুলির জন্য কম ক্ষতি দেয় যা খারাপ ভবিষ্যদ্বাণী করে এমন মডেলগুলির চেয়ে ভাল ভবিষ্যদ্বাণী করে।
প্রশিক্ষণের লক্ষ্যটি সাধারণত ক্ষতির ফাংশনটি যে ক্ষতিটি ফিরিয়ে দেয় তা হ্রাস করা।
বিভিন্ন ধরণের ক্ষতির ফাংশন বিদ্যমান। আপনি যে ধরণের মডেলটি তৈরি করছেন তার জন্য উপযুক্ত ক্ষতির ফাংশনটি চয়ন করুন। যেমন:
- L 2 ক্ষতি (বা গড় স্কোয়ার ত্রুটি ) লিনিয়ার রিগ্রেশন এর জন্য ক্ষতির ফাংশন।
- লগ ক্ষতি হ'ল লজিস্টিক রিগ্রেশনের জন্য ক্ষতির ফাংশন।
এম
মেশিন লার্নিং
একটি প্রোগ্রাম বা সিস্টেম যা ইনপুট ডেটা থেকে কোনও মডেলকে প্রশিক্ষণ দেয় । প্রশিক্ষিত মডেল মডেলটিকে প্রশিক্ষণের জন্য ব্যবহৃত একই বিতরণ থেকে আঁকা নতুন (আগে কখনও দেখা যায় না) ডেটা থেকে দরকারী ভবিষ্যদ্বাণী করতে পারে।
মেশিন লার্নিং এই প্রোগ্রামগুলি বা সিস্টেমগুলির সাথে সম্পর্কিত অধ্যয়নের ক্ষেত্রকেও বোঝায়।
সংখ্যাগরিষ্ঠ শ্রেণি
একটি শ্রেণি-অবিচ্ছিন্ন ডেটাসেটে আরও সাধারণ লেবেল। উদাহরণস্বরূপ, 99% নেতিবাচক লেবেল এবং 1% ধনাত্মক লেবেলযুক্ত একটি ডেটাসেট দেওয়া, নেতিবাচক লেবেলগুলি সংখ্যাগরিষ্ঠ শ্রেণি।
সংখ্যালঘু শ্রেণীর সাথে বৈপরীত্য।
মিনি ব্যাচ
একটি পুনরাবৃত্তিতে প্রক্রিয়াজাত একটি ব্যাচের একটি ছোট, এলোমেলোভাবে নির্বাচিত সাবসেট। একটি মিনি ব্যাচের ব্যাচের আকার সাধারণত 10 এবং 1000 টি উদাহরণের মধ্যে থাকে।
উদাহরণস্বরূপ, ধরুন পুরো প্রশিক্ষণ সেট (পুরো ব্যাচ) 1000 টি উদাহরণ নিয়ে গঠিত। আরও ধরুন যে আপনি প্রতিটি মিনি-ব্যাচের ব্যাচের আকার 20 এ সেট করেছেন So সুতরাং, প্রতিটি পুনরাবৃত্তি 1000 টি উদাহরণের মধ্যে 20 টি এলোমেলো 20 এর ক্ষতি নির্ধারণ করে এবং তারপরে ওজন এবং পক্ষপাতগুলি সামঞ্জস্য করে।
পূর্ণ ব্যাচের সমস্ত উদাহরণগুলির ক্ষতির চেয়ে মিনি ব্যাচে ক্ষতি গণনা করা অনেক বেশি দক্ষ।
সংখ্যালঘু শ্রেণি
একটি শ্রেণি-অসম্পূর্ণ ডেটাসেটে কম সাধারণ লেবেল। উদাহরণস্বরূপ, 99% নেতিবাচক লেবেল এবং 1% ধনাত্মক লেবেলযুক্ত একটি ডেটাসেট দেওয়া, পজিটিভ লেবেলগুলি সংখ্যালঘু শ্রেণি।
সংখ্যাগরিষ্ঠ শ্রেণীর সাথে বৈপরীত্য।
মডেল
সাধারণভাবে, কোনও গাণিতিক নির্মাণ যা ইনপুট ডেটা প্রক্রিয়া করে এবং আউটপুট দেয়। আলাদাভাবে বাক্যযুক্ত, একটি মডেল হ'ল পূর্বাভাস দেওয়ার জন্য কোনও সিস্টেমের জন্য প্রয়োজনীয় পরামিতি এবং কাঠামোর সেট। তদারকি করা মেশিন লার্নিংয়ে , একটি মডেল ইনপুট হিসাবে একটি উদাহরণ নেয় এবং আউটপুট হিসাবে পূর্বাভাস দেয়। তদারকি করা মেশিন লার্নিংয়ের মধ্যে, মডেলগুলি কিছুটা পৃথক। যেমন:
- একটি লিনিয়ার রিগ্রেশন মডেল ওজনের একটি সেট এবং একটি পক্ষপাত নিয়ে গঠিত।
- একটি নিউরাল নেটওয়ার্ক মডেল রয়েছে:
- লুকানো স্তরগুলির একটি সেট, প্রতিটিতে এক বা একাধিক নিউরন রয়েছে।
- প্রতিটি নিউরনের সাথে যুক্ত ওজন এবং পক্ষপাত।
- একটি সিদ্ধান্ত গাছের মডেল রয়েছে:
- গাছের আকৃতি; অর্থাৎ, শর্ত এবং পাতাগুলি সংযুক্ত থাকে এমন প্যাটার্নটি।
- শর্ত এবং পাতা।
আপনি কোনও মডেলের অনুলিপি সংরক্ষণ, পুনরুদ্ধার করতে বা তৈরি করতে পারেন।
অপ্রচলিত মেশিন লার্নিং মডেলগুলিও তৈরি করে, সাধারণত এমন একটি ফাংশন যা সর্বাধিক উপযুক্ত ক্লাস্টারে একটি ইনপুট উদাহরণকে মানচিত্র করতে পারে।
বহু-শ্রেণীর শ্রেণীবিভাগ
তত্ত্বাবধানে শেখার ক্ষেত্রে, একটি শ্রেণিবিন্যাসের সমস্যা যেখানে ডেটাসেটে দুটি শ্রেণির বেশি লেবেল রয়েছে। উদাহরণস্বরূপ, আইরিস ডেটাসেটের লেবেলগুলি নিম্নলিখিত তিনটি শ্রেণীর মধ্যে একটি হতে হবে:
- আইরিস সেটোসা
- আইরিস ভার্জিনিকা
- আইরিস ভার্সিকলার
আইআরআইএস ডেটাসেটে প্রশিক্ষিত একটি মডেল যা নতুন উদাহরণগুলিতে আইরিস প্রকারের পূর্বাভাস দেয় তা বহু-শ্রেণীর শ্রেণিবিন্যাস সম্পাদন করছে।
বিপরীতে, শ্রেণিবদ্ধকরণ সমস্যাগুলি যা ঠিক দুটি শ্রেণীর মধ্যে পার্থক্য করে তা হ'ল বাইনারি শ্রেণিবিন্যাসের মডেল । উদাহরণস্বরূপ, একটি ইমেল মডেল যা স্প্যাম বা না স্প্যামের পূর্বাভাস দেয় একটি বাইনারি শ্রেণিবিন্যাস মডেল।
ক্লাস্টারিং সমস্যাগুলিতে, মাল্টি-ক্লাসের শ্রেণিবিন্যাস দুটি বেশি ক্লাস্টারকে বোঝায়।
এন
নেতিবাচক শ্রেণি
বাইনারি শ্রেণিবিন্যাসে , একটি শ্রেণিকে ইতিবাচক বলে অভিহিত করা হয় এবং অন্যটিকে নেতিবাচক বলে অভিহিত করা হয়। ইতিবাচক শ্রেণিটি এমন জিনিস বা ইভেন্ট যা মডেলটি পরীক্ষা করছে এবং নেতিবাচক শ্রেণিটি অন্য সম্ভাবনা। যেমন:
- চিকিত্সা পরীক্ষায় নেতিবাচক শ্রেণি "টিউমার নয়" হতে পারে।
- একটি ইমেল শ্রেণিবদ্ধের নেতিবাচক শ্রেণি হতে পারে "স্প্যাম নয়"।
ইতিবাচক শ্রেণীর সাথে বৈপরীত্য।
নিউরাল নেটওয়ার্ক
কমপক্ষে একটি লুকানো স্তরযুক্ত একটি মডেল । একটি গভীর নিউরাল নেটওয়ার্ক হ'ল এক ধরণের নিউরাল নেটওয়ার্ক যা একাধিক লুকানো স্তরযুক্ত। উদাহরণস্বরূপ, নিম্নলিখিত চিত্রটি দুটি লুকানো স্তরযুক্ত একটি গভীর নিউরাল নেটওয়ার্ক দেখায়।
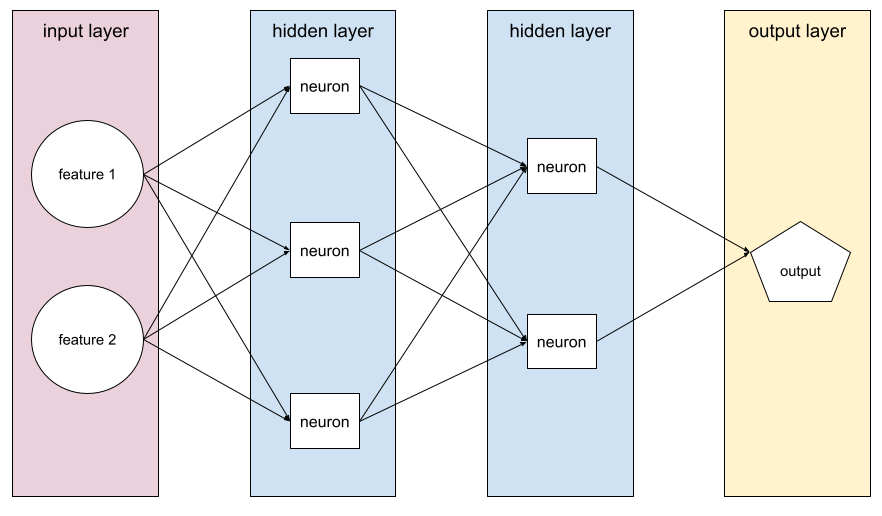
একটি নিউরাল নেটওয়ার্কের প্রতিটি নিউরন পরবর্তী স্তরের সমস্ত নোডের সাথে সংযোগ স্থাপন করে। উদাহরণস্বরূপ, পূর্ববর্তী ডায়াগ্রামে, লক্ষ্য করুন যে প্রথম লুকানো স্তরের তিনটি নিউরনের প্রত্যেকটি পৃথকভাবে দ্বিতীয় লুকানো স্তরটির দুটি নিউরনের সাথে সংযুক্ত করে।
কম্পিউটারগুলিতে প্রয়োগ করা নিউরাল নেটওয়ার্কগুলিকে কখনও কখনও মস্তিষ্ক এবং অন্যান্য স্নায়ুতন্ত্রের মধ্যে পাওয়া নিউরাল নেটওয়ার্কগুলি থেকে আলাদা করার জন্য কৃত্রিম নিউরাল নেটওয়ার্ক বলা হয়।
কিছু নিউরাল নেটওয়ার্ক বিভিন্ন বৈশিষ্ট্য এবং লেবেলের মধ্যে অত্যন্ত জটিল ননলাইনার সম্পর্কের নকল করতে পারে।
কনভোলিউশনাল নিউরাল নেটওয়ার্ক এবং পুনরাবৃত্ত নিউরাল নেটওয়ার্কও দেখুন।
নিউরন
মেশিন লার্নিংয়ে, একটি নিউরাল নেটওয়ার্কের একটি লুকানো স্তরের মধ্যে একটি স্বতন্ত্র ইউনিট। প্রতিটি নিউরন নিম্নলিখিত দ্বি-পদক্ষেপের ক্রিয়া সম্পাদন করে:
- তাদের সংশ্লিষ্ট ওজন দ্বারা গুণিত ইনপুট মানগুলির ওজনযুক্ত যোগফল গণনা করে।
- একটি অ্যাক্টিভেশন ফাংশনে ইনপুট হিসাবে ওজনযুক্ত যোগফল পাস করে।
প্রথম লুকানো স্তরের একটি নিউরন ইনপুট স্তরটির বৈশিষ্ট্য মানগুলি থেকে ইনপুট গ্রহণ করে। প্রথমটির বাইরে যে কোনও লুকানো স্তরের নিউরন পূর্ববর্তী লুকানো স্তরটিতে নিউরনগুলি থেকে ইনপুটগুলি গ্রহণ করে। উদাহরণস্বরূপ, দ্বিতীয় লুকানো স্তরটির একটি নিউরন প্রথম লুকানো স্তরটিতে নিউরনগুলি থেকে ইনপুট গ্রহণ করে।
নিম্নলিখিত চিত্রটি দুটি নিউরন এবং তাদের ইনপুটগুলি হাইলাইট করে।
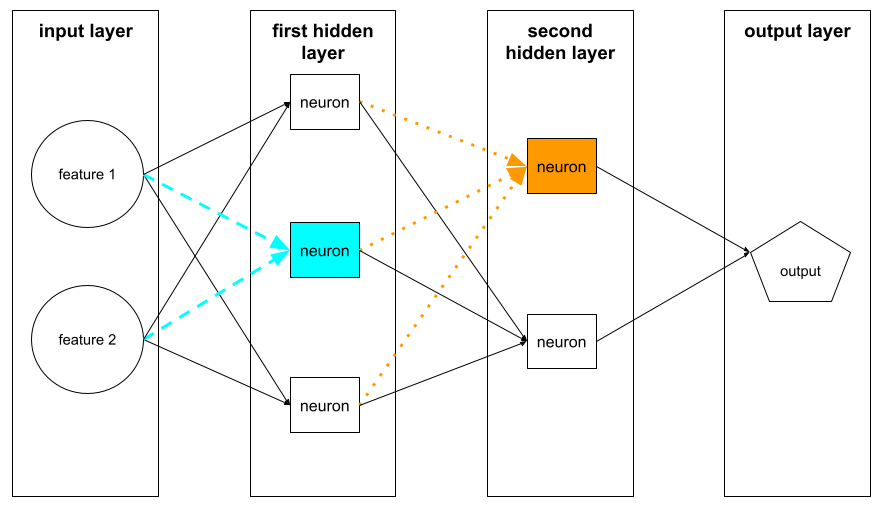
একটি নিউরাল নেটওয়ার্কের একটি নিউরন মস্তিষ্ক এবং স্নায়ুতন্ত্রের অন্যান্য অংশে নিউরনের আচরণের নকল করে।
নোড (নিউরাল নেটওয়ার্ক)
একটি লুকানো স্তরে একটি নিউরন ।
অরৈখিক
দুটি বা ততোধিক ভেরিয়েবলের মধ্যে একটি সম্পর্ক যা কেবলমাত্র সংযোজন এবং গুণের মাধ্যমে প্রতিনিধিত্ব করা যায় না। একটি লিনিয়ার সম্পর্ক একটি লাইন হিসাবে প্রতিনিধিত্ব করা যেতে পারে; একটি অরৈখিক সম্পর্ক একটি লাইন হিসাবে প্রতিনিধিত্ব করা যায় না। উদাহরণস্বরূপ, দুটি মডেল বিবেচনা করুন যা প্রতিটি একক বৈশিষ্ট্যকে একটি একক লেবেলের সাথে সম্পর্কিত করে। বাম দিকের মডেলটি লিনিয়ার এবং ডানদিকে মডেলটি অরৈখিক:

অবিচ্ছিন্নতা
এমন একটি বৈশিষ্ট্য যার মানগুলি এক বা একাধিক মাত্রা জুড়ে পরিবর্তিত হয়, সাধারণত সময়। উদাহরণস্বরূপ, ননস্টেশনারিটির নিম্নলিখিত উদাহরণগুলি বিবেচনা করুন:
- একটি নির্দিষ্ট স্টোরে বিক্রি হওয়া সাঁতারের পোশাকের সংখ্যা মরসুমের সাথে পরিবর্তিত হয়।
- একটি নির্দিষ্ট অঞ্চলে কাটা একটি নির্দিষ্ট ফলের পরিমাণ বছরের বেশিরভাগ সময় শূন্য তবে সংক্ষিপ্ত সময়ের জন্য বড়।
- জলবায়ু পরিবর্তনের কারণে, বার্ষিক গড় তাপমাত্রা স্থানান্তরিত হয়।
স্টেশনারিটির সাথে বৈপরীত্য।
স্বাভাবিকীকরণ
বিস্তৃতভাবে বলতে গেলে, একটি ভেরিয়েবলের প্রকৃত পরিসীমা মানগুলির মানগুলির একটি স্ট্যান্ডার্ড পরিসরে রূপান্তর করার প্রক্রিয়া যেমন:
- -1 থেকে +1
- 0 থেকে 1
- সাধারণ বিতরণ
উদাহরণস্বরূপ, ধরুন একটি নির্দিষ্ট বৈশিষ্ট্যের মানগুলির প্রকৃত পরিসীমা 800 থেকে 2,400। বৈশিষ্ট্য ইঞ্জিনিয়ারিংয়ের অংশ হিসাবে, আপনি প্রকৃত মানগুলি একটি স্ট্যান্ডার্ড পরিসরে যেমন -1 থেকে +1 এর নিচে স্বাভাবিক করতে পারেন।
বৈশিষ্ট্য ইঞ্জিনিয়ারিংয়ের ক্ষেত্রে স্বাভাবিককরণ একটি সাধারণ কাজ। মডেলগুলি সাধারণত দ্রুত প্রশিক্ষণ দেয় (এবং আরও ভাল ভবিষ্যদ্বাণী তৈরি করে) যখন বৈশিষ্ট্য ভেক্টরের প্রতিটি সংখ্যার বৈশিষ্ট্যটিতে মোটামুটি একই পরিসীমা থাকে।
সংখ্যাসূচক তথ্য
বৈশিষ্ট্যগুলি পূর্ণসংখ্যা বা বাস্তব-মূল্যবান সংখ্যা হিসাবে প্রতিনিধিত্ব করে। উদাহরণস্বরূপ, একটি বাড়ির মূল্যায়ন মডেল সম্ভবত কোনও বাড়ির আকার (বর্গফুট বা বর্গমিটারে) সংখ্যার ডেটা হিসাবে উপস্থাপন করবে। সংখ্যার ডেটা হিসাবে কোনও বৈশিষ্ট্য উপস্থাপন করা ইঙ্গিত দেয় যে বৈশিষ্ট্যটির মানগুলির লেবেলের সাথে গাণিতিক সম্পর্ক রয়েছে। এটি হ'ল, কোনও বাড়িতে বর্গমিটারের সংখ্যা সম্ভবত বাড়ির মূল্যের সাথে কিছু গাণিতিক সম্পর্ক রয়েছে।
সমস্ত পূর্ণসংখ্যার ডেটা সংখ্যার ডেটা হিসাবে প্রতিনিধিত্ব করা উচিত নয়। উদাহরণস্বরূপ, বিশ্বের কিছু অংশে ডাক কোডগুলি পূর্ণসংখ্যা; তবে, পূর্ণসংখ্যা ডাক কোডগুলি মডেলগুলিতে সংখ্যাসূচক ডেটা হিসাবে প্রতিনিধিত্ব করা উচিত নয়। কারণ 20000 এর একটি ডাক কোডটি 10000 এর ডাক কোড হিসাবে দু'বার (বা অর্ধেক) শক্তিশালী নয় Furly তদ্ব্যতীত, যদিও বিভিন্ন ডাক কোডগুলি বিভিন্ন রিয়েল এস্টেট মানগুলির সাথে সম্পর্কিত , আমরা ধরে নিতে পারি না যে ডাক কোড 20000 এ রিয়েল এস্টেটের মানগুলি ডাক কোড 10000 এ রিয়েল এস্টেটের মানগুলির মতো দ্বিগুণ মূল্যবান Post ডাক কোডগুলি পরিবর্তে শ্রেণিবদ্ধ ডেটা হিসাবে উপস্থাপন করা উচিত।
সংখ্যার বৈশিষ্ট্যগুলি কখনও কখনও অবিচ্ছিন্ন বৈশিষ্ট্য বলা হয়।
ও
অফলাইন
স্ট্যাটিক জন্য প্রতিশব্দ।
অফলাইন অনুমান
একটি মডেল ভবিষ্যদ্বাণীগুলির একটি ব্যাচ উত্পন্ন করে এবং তারপরে সেই ভবিষ্যদ্বাণীগুলি ক্যাশে (সংরক্ষণ)। অ্যাপ্লিকেশনগুলি তখন মডেলটিকে পুনরায় সাজানোর পরিবর্তে ক্যাশে থেকে অনুমিত পূর্বাভাস অ্যাক্সেস করতে পারে।
উদাহরণস্বরূপ, এমন একটি মডেল বিবেচনা করুন যা স্থানীয় আবহাওয়ার পূর্বাভাস (ভবিষ্যদ্বাণীগুলি) প্রতি চার ঘন্টা একবার উত্পন্ন করে। প্রতিটি মডেল চালানোর পরে, সিস্টেমটি সমস্ত স্থানীয় আবহাওয়ার পূর্বাভাস ক্যাশে করে। আবহাওয়া অ্যাপ্লিকেশনগুলি ক্যাশে থেকে পূর্বাভাস পুনরুদ্ধার করে।
অফলাইন অনুমানকে স্ট্যাটিক অনুমানও বলা হয়।
অনলাইন অনুমানের সাথে বৈপরীত্য।
এক-গরম এনকোডিং
ভেক্টর হিসাবে শ্রেণীবদ্ধ ডেটা উপস্থাপন করে:
- একটি উপাদান 1 এ সেট করা আছে।
- অন্যান্য সমস্ত উপাদান 0 এ সেট করা আছে।
ওয়ান-হট এনকোডিং সাধারণত স্ট্রিং বা শনাক্তকারীদের প্রতিনিধিত্ব করতে ব্যবহৃত হয় যার সম্ভাব্য মানগুলির একটি সীমাবদ্ধ সেট রয়েছে। উদাহরণস্বরূপ, ধরুন Scandinavia নামের একটি নির্দিষ্ট শ্রেণিবদ্ধ বৈশিষ্ট্যের পাঁচটি সম্ভাব্য মান রয়েছে:
- "ডেনমার্ক"
- "সুইডেন"
- "নরওয়ে"
- "ফিনল্যান্ড"
- "আইসল্যান্ড"
এক-হট এনকোডিং নিম্নলিখিত পাঁচটি মানের প্রত্যেককে উপস্থাপন করতে পারে:
| দেশ | ভেক্টর | ||||
|---|---|---|---|---|---|
| "ডেনমার্ক" | 1 | 0 | 0 | 0 | 0 |
| "সুইডেন" | 0 | 1 | 0 | 0 | 0 |
| "নরওয়ে" | 0 | 0 | 1 | 0 | 0 |
| "ফিনল্যান্ড" | 0 | 0 | 0 | 1 | 0 |
| "আইসল্যান্ড" | 0 | 0 | 0 | 0 | 1 |
ওয়ান-হট এনকোডিংয়ের জন্য ধন্যবাদ, একটি মডেল পাঁচটি দেশের প্রত্যেকটির উপর ভিত্তি করে বিভিন্ন সংযোগ শিখতে পারে।
সংখ্যার ডেটা হিসাবে কোনও বৈশিষ্ট্য উপস্থাপন করা এক-হট এনকোডিংয়ের বিকল্প। দুর্ভাগ্যক্রমে, স্ক্যান্ডিনেভিয়ার দেশগুলিকে সংখ্যায় উপস্থাপন করা ভাল পছন্দ নয়। উদাহরণস্বরূপ, নিম্নলিখিত সংখ্যার প্রতিনিধিত্ব বিবেচনা করুন:
- "ডেনমার্ক" 0
- "সুইডেন" 1
- "নরওয়ে" 2
- "ফিনল্যান্ড" 3
- "আইসল্যান্ড" 4
সংখ্যার এনকোডিং সহ, একটি মডেল কাঁচা সংখ্যাগুলি গাণিতিকভাবে ব্যাখ্যা করবে এবং এই সংখ্যাগুলিতে প্রশিক্ষণের চেষ্টা করবে। যাইহোক, আইসল্যান্ড আসলে নরওয়ের মতো কোনও কিছুর দ্বিগুণ (বা অর্ধেক) নয়, তাই মডেলটি কিছু অদ্ভুত সিদ্ধান্তে আসবে।
এক-ভিএস-সমস্ত
এন ক্লাসগুলির সাথে একটি শ্রেণিবিন্যাসের সমস্যা দেওয়া, প্রতিটি সম্ভাব্য ফলাফলের জন্য এন পৃথক বাইনারি শ্রেণিবদ্ধ - এক বাইনারি শ্রেণিবদ্ধ সমন্বিত একটি সমাধান। উদাহরণস্বরূপ, এমন একটি মডেল দেওয়া যা উদাহরণগুলিকে প্রাণী, উদ্ভিজ্জ বা খনিজ হিসাবে শ্রেণিবদ্ধ করে, একটি এক-বনাম-সমস্ত সমাধান নিম্নলিখিত তিনটি পৃথক বাইনারি শ্রেণিবদ্ধ সরবরাহ করবে:
- প্রাণী বনাম প্রাণী নয়
- উদ্ভিজ্জ বনাম উদ্ভিজ্জ নয়
- খনিজ বনাম খনিজ নয়
অনলাইন
গতিশীলের প্রতিশব্দ।
অনলাইন অনুমান
চাহিদা উপর ভবিষ্যদ্বাণী উত্পন্ন করা। উদাহরণস্বরূপ, ধরুন কোনও অ্যাপ্লিকেশন কোনও মডেলের ইনপুট পাস করে এবং একটি পূর্বাভাসের জন্য একটি অনুরোধ জারি করে। অনলাইন ইনফারেন্স ব্যবহার করে একটি সিস্টেম মডেলটি চালিয়ে অনুরোধের প্রতিক্রিয়া জানায় (এবং অ্যাপ্লিকেশনটিতে ভবিষ্যদ্বাণীটি ফিরিয়ে দেয়)।
অফলাইন অনুমানের সাথে বিপরীতে।
আউটপুট স্তর
একটি নিউরাল নেটওয়ার্কের "চূড়ান্ত" স্তর। আউটপুট স্তরটিতে পূর্বাভাস রয়েছে।
নিম্নলিখিত চিত্রটি একটি ইনপুট স্তর, দুটি লুকানো স্তর এবং একটি আউটপুট স্তর সহ একটি ছোট গভীর নিউরাল নেটওয়ার্ক দেখায়:
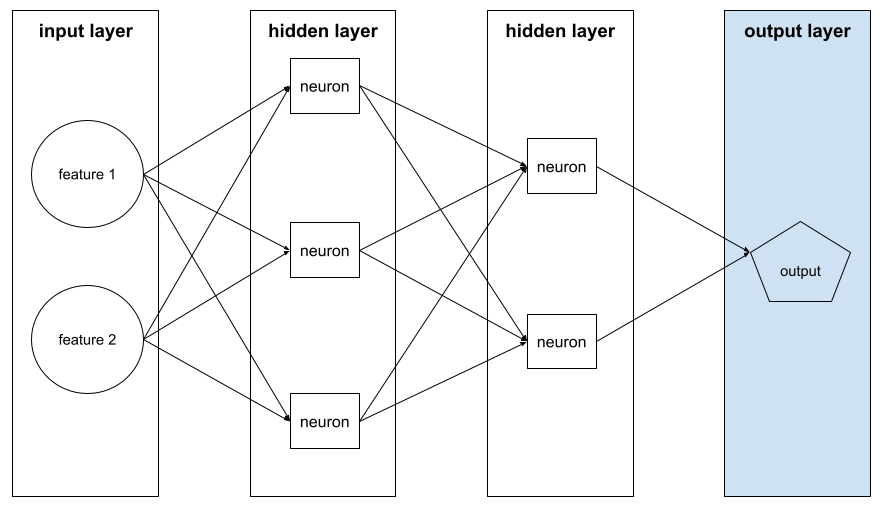
ওভারফিটিং
এমন একটি মডেল তৈরি করা যা প্রশিক্ষণের ডেটা এত ঘনিষ্ঠভাবে মেলে যে মডেলটি নতুন ডেটাতে সঠিক ভবিষ্যদ্বাণী করতে ব্যর্থ হয়।
নিয়মিতকরণ ওভারফিটিং হ্রাস করতে পারে। একটি বৃহত এবং বৈচিত্র্যময় প্রশিক্ষণ সেট উপর প্রশিক্ষণ ওভারফিটিং হ্রাস করতে পারে।
পৃ
পান্ডা
একটি কলাম-ভিত্তিক ডেটা বিশ্লেষণ এপিআই নম্বির শীর্ষে নির্মিত। টেনসরফ্লো সহ অনেকগুলি মেশিন লার্নিং ফ্রেমওয়ার্কগুলি ইনপুট হিসাবে পান্ডাস ডেটা স্ট্রাকচারকে সমর্থন করে। বিশদ জন্য পান্ডাস ডকুমেন্টেশন দেখুন।
প্যারামিটার
প্রশিক্ষণের সময় কোনও মডেল যে ওজন এবং পক্ষপাতিত্বগুলি শিখেন। উদাহরণস্বরূপ, একটি লিনিয়ার রিগ্রেশন মডেলটিতে, প্যারামিটারগুলি নিম্নলিখিত সূত্রে পক্ষপাত ( বি ) এবং সমস্ত ওজন ( ডাব্লু 1 , ডাব্লু 2 , এবং আরও) নিয়ে গঠিত:
বিপরীতে, হাইপারপ্যারামিটার হ'ল মানগুলি যা আপনি (বা হাইপারপ্যারামিটার টার্নিং সার্ভিস) মডেলটিতে সরবরাহ করেন। উদাহরণস্বরূপ, শেখার হার একটি হাইপারপ্যারামিটার।
ইতিবাচক শ্রেণি
আপনি যে ক্লাসটির জন্য পরীক্ষা করছেন।
উদাহরণস্বরূপ, ক্যান্সার মডেলের ইতিবাচক শ্রেণি হতে পারে "টিউমার"। একটি ইমেল শ্রেণিবদ্ধের ইতিবাচক শ্রেণি হতে পারে "স্প্যাম"।
নেতিবাচক শ্রেণীর সাথে বৈপরীত্য।
পোস্ট-প্রসেসিং
মডেলটি চালানোর পরে কোনও মডেলের আউটপুট সামঞ্জস্য করা। পোস্ট-প্রসেসিং তাদের মডেলগুলি সংশোধন না করে ন্যায্যতার সীমাবদ্ধতাগুলি প্রয়োগ করতে ব্যবহার করা যেতে পারে।
উদাহরণস্বরূপ, কেউ বাইনারি শ্রেণিবদ্ধের জন্য পোস্ট-প্রসেসিং প্রয়োগ করতে পারে এমন একটি শ্রেণিবিন্যাসের প্রান্তিক সেট করে যাতে সুযোগের সমতা কিছু বৈশিষ্ট্যের জন্য রক্ষণাবেক্ষণ করা হয় যা পরীক্ষা করে যে সত্যিকারের ইতিবাচক হার সেই বৈশিষ্ট্যের সমস্ত মানের জন্য একই।
ভবিষ্যদ্বাণী
একটি মডেলের আউটপুট। যেমন:
- বাইনারি শ্রেণিবদ্ধকরণ মডেলের পূর্বাভাস হয় হয় ইতিবাচক শ্রেণি বা নেতিবাচক শ্রেণি।
- মাল্টি-ক্লাসের শ্রেণিবদ্ধকরণ মডেলের পূর্বাভাস এক শ্রেণি।
- লিনিয়ার রিগ্রেশন মডেলের পূর্বাভাস একটি সংখ্যা।
প্রক্সি লেবেল
কোনও ডেটাসেটে সরাসরি উপলভ্য নয় এমন আনুমানিক লেবেলগুলিতে ব্যবহৃত ডেটা।
For example, suppose you must train a model to predict employee stress level. Your dataset contains a lot of predictive features but doesn't contain a label named stress level. Undaunted, you pick "workplace accidents" as a proxy label for stress level. After all, employees under high stress get into more accidents than calm employees. নাকি তারা করে? Maybe workplace accidents actually rise and fall for multiple reasons.
As a second example, suppose you want is it raining? to be a Boolean label for your dataset, but your dataset doesn't contain rain data. If photographs are available, you might establish pictures of people carrying umbrellas as a proxy label for is it raining? Is that a good proxy label? Possibly, but people in some cultures may be more likely to carry umbrellas to protect against sun than the rain.
Proxy labels are often imperfect. When possible, choose actual labels over proxy labels. That said, when an actual label is absent, pick the proxy label very carefully, choosing the least horrible proxy label candidate.
আর
RAG
Abbreviation for retrieval-augmented generation .
রেটার
A human who provides labels for examples . "Annotator" is another name for rater.
সংশোধনকৃত লিনিয়ার ইউনিট (ReLU)
An activation function with the following behavior:
- If input is negative or zero, then the output is 0.
- If input is positive, then the output is equal to the input.
যেমন:
- If the input is -3, then the output is 0.
- If the input is +3, then the output is 3.0.
Here is a plot of ReLU:
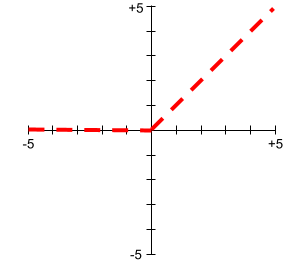
ReLU is a very popular activation function. Despite its simple behavior, ReLU still enables a neural network to learn nonlinear relationships between features and the label .
রিগ্রেশন মডেল
Informally, a model that generates a numerical prediction. (In contrast, a classification model generates a class prediction.) For example, the following are all regression models:
- A model that predicts a certain house's value, such as 423,000 Euros.
- A model that predicts a certain tree's life expectancy, such as 23.2 years.
- A model that predicts the amount of rain that will fall in a certain city over the next six hours, such as 0.18 inches.
Two common types of regression models are:
- Linear regression , which finds the line that best fits label values to features.
- Logistic regression , which generates a probability between 0.0 and 1.0 that a system typically then maps to a class prediction.
Not every model that outputs numerical predictions is a regression model. In some cases, a numeric prediction is really just a classification model that happens to have numeric class names. For example, a model that predicts a numeric postal code is a classification model, not a regression model.
নিয়মিতকরণ
Any mechanism that reduces overfitting . Popular types of regularization include:
- এল 1 নিয়মিতকরণ
- এল 2 নিয়মিতকরণ
- ড্রপআউট নিয়মিতকরণ
- early stopping (this is not a formal regularization method, but can effectively limit overfitting)
Regularization can also be defined as the penalty on a model's complexity.
নিয়মিতকরণ হার
A number that specifies the relative importance of regularization during training. Raising the regularization rate reduces overfitting but may reduce the model's predictive power. Conversely, reducing or omitting the regularization rate increases overfitting.
ReLU
Abbreviation for Rectified Linear Unit .
retrieval-augmented generation (RAG)
A technique for improving the quality of large language model (LLM) output by grounding it with sources of knowledge retrieved after the model was trained. RAG improves the accuracy of LLM responses by providing the trained LLM with access to information retrieved from trusted knowledge bases or documents.
Common motivations to use retrieval-augmented generation include:
- Increasing the factual accuracy of a model's generated responses.
- Giving the model access to knowledge it was not trained on.
- Changing the knowledge that the model uses.
- Enabling the model to cite sources.
For example, suppose that a chemistry app uses the PaLM API to generate summaries related to user queries. When the app's backend receives a query, the backend:
- Searches for ("retrieves") data that's relevant to the user's query.
- Appends ("augments") the relevant chemistry data to the user's query.
- Instructs the LLM to create a summary based on the appended data.
ROC (receiver operating characteristic) Curve
A graph of true positive rate versus false positive rate for different classification thresholds in binary classification.
The shape of an ROC curve suggests a binary classification model's ability to separate positive classes from negative classes. Suppose, for example, that a binary classification model perfectly separates all the negative classes from all the positive classes:
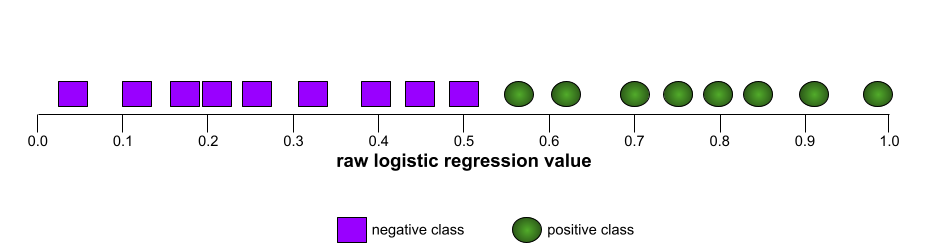
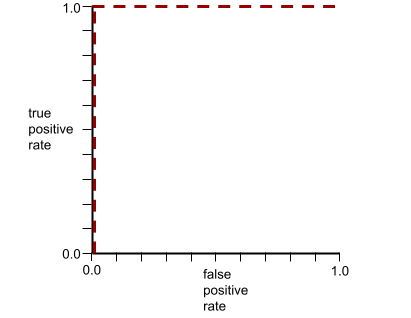
The ROC curve for the preceding model looks as follows:
In contrast, the following illustration graphs the raw logistic regression values for a terrible model that can't separate negative classes from positive classes at all:
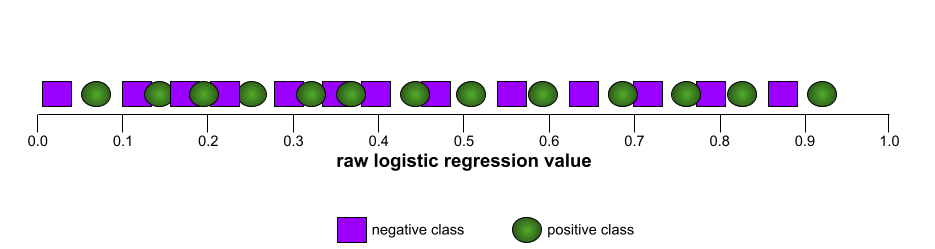
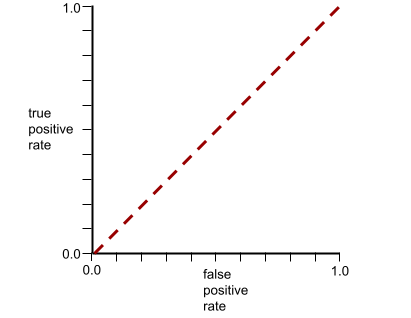
The ROC curve for this model looks as follows:
Meanwhile, back in the real world, most binary classification models separate positive and negative classes to some degree, but usually not perfectly. So, a typical ROC curve falls somewhere between the two extremes:
The point on an ROC curve closest to (0.0,1.0) theoretically identifies the ideal classification threshold. However, several other real-world issues influence the selection of the ideal classification threshold. For example, perhaps false negatives cause far more pain than false positives.
A numerical metric called AUC summarizes the ROC curve into a single floating-point value.
রুট গড় বর্গাকার ত্রুটি (RMSE)
The square root of the Mean Squared Error .
এস
সিগমায়েড ফাংশন
A mathematical function that "squishes" an input value into a constrained range, typically 0 to 1 or -1 to +1. That is, you can pass any number (two, a million, negative billion, whatever) to a sigmoid and the output will still be in the constrained range. A plot of the sigmoid activation function looks as follows:
The sigmoid function has several uses in machine learning, including:
- Converting the raw output of a logistic regression or multinomial regression model to a probability.
- Acting as an activation function in some neural networks.
softmax
A function that determines probabilities for each possible class in a multi-class classification model . The probabilities add up to exactly 1.0. For example, the following table shows how softmax distributes various probabilities:
| Image is a... | সম্ভাবনা |
|---|---|
| কুকুর | .85 |
| বিড়াল | .13 |
| ঘোড়া | .02 |
Softmax is also called full softmax .
Contrast with candidate sampling .
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree . Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding . If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36 tree species in a particular forest. Further assume that each example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example. A one-hot vector would contain a single 1 (to represent the particular tree species in that example) and 35 0 s (to represent the 35 tree species not in that example). So, the one-hot representation of maple might look something like the following:

Alternatively, sparse representation would simply identify the position of the particular species. If maple is at position 24, then the sparse representation of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
নিম্নলিখিত বাক্য বিবেচনা করুন:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:

A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
sparse vector
A vector whose values are mostly zeroes. See also sparse feature and sparsity .
squared loss
Synonym for L 2 loss .
স্থির
Something done once rather than continuously. The terms static and offline are synonyms. The following are common uses of static and offline in machine learning:
- static model (or offline model ) is a model trained once and then used for a while.
- static training (or offline training ) is the process of training a static model.
- static inference (or offline inference ) is a process in which a model generates a batch of predictions at a time.
Contrast with dynamic .
static inference
Synonym for offline inference .
স্থিরতা
A feature whose values don't change across one or more dimensions, usually time. For example, a feature whose values look about the same in 2021 and 2023 exhibits stationarity.
In the real world, very few features exhibit stationarity. Even features synonymous with stability (like sea level) change over time.
Contrast with nonstationarity .
স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট (SGD)
A gradient descent algorithm in which the batch size is one. In other words, SGD trains on a single example chosen uniformly at random from a training set .
তত্ত্বাবধানে মেশিন লার্নিং
Training a model from features and their corresponding labels . Supervised machine learning is analogous to learning a subject by studying a set of questions and their corresponding answers. After mastering the mapping between questions and answers, a student can then provide answers to new (never-before-seen) questions on the same topic.
Compare with unsupervised machine learning .
synthetic feature
A feature not present among the input features, but assembled from one or more of them. Methods for creating synthetic features include the following:
- Bucketing a continuous feature into range bins.
- Creating a feature cross .
- Multiplying (or dividing) one feature value by other feature value(s) or by itself. For example, if
aandbare input features, then the following are examples of synthetic features:- ab
- একটি 2
- Applying a transcendental function to a feature value. For example, if
cis an input feature, then the following are examples of synthetic features:- sin(c)
- ln(c)
Features created by normalizing or scaling alone are not considered synthetic features.
টি
test loss
A metric representing a model's loss against the test set . When building a model , you typically try to minimize test loss. That's because a low test loss is a stronger quality signal than a low training loss or low validation loss .
A large gap between test loss and training loss or validation loss sometimes suggests that you need to increase the regularization rate .
প্রশিক্ষণ
The process of determining the ideal parameters (weights and biases) comprising a model . During training, a system reads in examples and gradually adjusts parameters. Training uses each example anywhere from a few times to billions of times.
training loss
A metric representing a model's loss during a particular training iteration. For example, suppose the loss function is Mean Squared Error . Perhaps the training loss (the Mean Squared Error) for the 10th iteration is 2.2, and the training loss for the 100th iteration is 1.9.
A loss curve plots training loss versus the number of iterations. A loss curve provides the following hints about training:
- A downward slope implies that the model is improving.
- An upward slope implies that the model is getting worse.
- A flat slope implies that the model has reached convergence .
For example, the following somewhat idealized loss curve shows:
- A steep downward slope during the initial iterations, which implies rapid model improvement.
- A gradually flattening (but still downward) slope until close to the end of training, which implies continued model improvement at a somewhat slower pace then during the initial iterations.
- A flat slope towards the end of training, which suggests convergence.
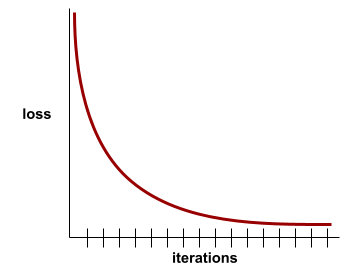
Although training loss is important, see also generalization .
training-serving skew
The difference between a model's performance during training and that same model's performance during serving .
training set
The subset of the dataset used to train a model .
Traditionally, examples in the dataset are divided into the following three distinct subsets:
- একটি প্রশিক্ষণ সেট
- a validation set
- a test set
Ideally, each example in the dataset should belong to only one of the preceding subsets. For example, a single example shouldn't belong to both the training set and the validation set.
সত্য নেতিবাচক (TN)
An example in which the model correctly predicts the negative class . For example, the model infers that a particular email message is not spam , and that email message really is not spam .
সত্য ইতিবাচক (TP)
An example in which the model correctly predicts the positive class . For example, the model infers that a particular email message is spam, and that email message really is spam.
true positive rate (TPR)
Synonym for recall . অর্থাৎ:
True positive rate is the y-axis in an ROC curve .
উ
আন্ডারফিটিং
Producing a model with poor predictive ability because the model hasn't fully captured the complexity of the training data. Many problems can cause underfitting, including:
- Training on the wrong set of features .
- Training for too few epochs or at too low a learning rate .
- Training with too high a regularization rate .
- Providing too few hidden layers in a deep neural network.
unlabeled example
An example that contains features but no label . For example, the following table shows three unlabeled examples from a house valuation model, each with three features but no house value:
| বেডরুমের সংখ্যা | বাথরুমের সংখ্যা | House age |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
In supervised machine learning , models train on labeled examples and make predictions on unlabeled examples .
In semi-supervised and unsupervised learning, unlabeled examples are used during training.
Contrast unlabeled example with labeled example .
তত্ত্বাবধানহীন মেশিন লার্নিং
Training a model to find patterns in a dataset, typically an unlabeled dataset.
The most common use of unsupervised machine learning is to cluster data into groups of similar examples. For example, an unsupervised machine learning algorithm can cluster songs based on various properties of the music. The resulting clusters can become an input to other machine learning algorithms (for example, to a music recommendation service). Clustering can help when useful labels are scarce or absent. For example, in domains such as anti-abuse and fraud, clusters can help humans better understand the data.
Contrast with supervised machine learning .
ভি
বৈধতা
The initial evaluation of a model's quality. Validation checks the quality of a model's predictions against the validation set .
Because the validation set differs from the training set , validation helps guard against overfitting .
You might think of evaluating the model against the validation set as the first round of testing and evaluating the model against the test set as the second round of testing.
validation loss
A metric representing a model's loss on the validation set during a particular iteration of training.
See also generalization curve .
বৈধতা সেট
The subset of the dataset that performs initial evaluation against a trained model . Typically, you evaluate the trained model against the validation set several times before evaluating the model against the test set .
Traditionally, you divide the examples in the dataset into the following three distinct subsets:
- একটি প্রশিক্ষণ সেট
- a validation set
- a test set
Ideally, each example in the dataset should belong to only one of the preceding subsets. For example, a single example shouldn't belong to both the training set and the validation set.
ডব্লিউ
ওজন
A value that a model multiplies by another value. Training is the process of determining a model's ideal weights; inference is the process of using those learned weights to make predictions.
ওজনযুক্ত সমষ্টি
The sum of all the relevant input values multiplied by their corresponding weights. For example, suppose the relevant inputs consist of the following:
| ইনপুট মান | ইনপুট ওজন |
| 2 | -1.3 |
| -1 | 0.6 |
| 3 | 0.4 |
The weighted sum is therefore:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
A weighted sum is the input argument to an activation function .
জেড
জেড-স্কোর স্বাভাবিককরণ
A scaling technique that replaces a raw feature value with a floating-point value representing the number of standard deviations from that feature's mean. For example, consider a feature whose mean is 800 and whose standard deviation is 100. The following table shows how Z-score normalization would map the raw value to its Z-score:
| কাঁচা মান | জেড-স্কোর |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
The machine learning model then trains on the Z-scores for that feature instead of on the raw values.