این صفحه شامل اصطلاحات واژه نامه ارزیابی زبان است. برای همه اصطلاحات واژه نامه، اینجا را کلیک کنید .
الف
توجه
مکانیزمی که در شبکه عصبی استفاده می شود و اهمیت یک کلمه یا بخشی از یک کلمه را نشان می دهد. توجه، مقدار اطلاعاتی را که یک مدل برای پیشبینی رمز/کلمه بعدی نیاز دارد، فشرده میکند. یک مکانیسم توجه معمولی ممکن است شامل یک جمع وزنی بر روی مجموعهای از ورودیها باشد، جایی که وزن هر ورودی توسط بخش دیگری از شبکه عصبی محاسبه میشود.
رجوع به خود توجهی و خودتوجهی چند سر نیز شود که اجزای سازنده ترانسفورماتورها هستند.
رمزگذار خودکار
سیستمی که یاد می گیرد مهم ترین اطلاعات را از ورودی استخراج کند. رمزگذارهای خودکار ترکیبی از رمزگذار و رمزگشا هستند. رمزگذارهای خودکار بر فرآیند دو مرحله ای زیر متکی هستند:
- رمزگذار ورودی را به یک قالب (معمولا) با ابعاد پایین تر (متوسط) ترسیم می کند.
- رمزگشا با نگاشت قالب با ابعاد پایین تر به فرمت ورودی با ابعاد بالاتر، یک نسخه با اتلاف از ورودی اصلی ایجاد می کند.
رمزگذارهای خودکار با تلاش رمزگشا برای بازسازی ورودی اصلی از فرمت میانی رمزگذار تا حد امکان به صورت سرتاسر آموزش داده می شوند. از آنجایی که فرمت میانی کوچکتر (بُعد پایین) از فرمت اصلی است، رمزگذار خودکار مجبور است اطلاعاتی را که در ورودی ضروری است، بیاموزد و خروجی کاملاً با ورودی یکسان نخواهد بود.
به عنوان مثال:
- اگر داده های ورودی گرافیکی باشد، کپی غیر دقیق شبیه به گرافیک اصلی است، اما تا حدودی تغییر یافته است. شاید کپی غیر دقیق، نویز را از گرافیک اصلی حذف می کند یا برخی از پیکسل های از دست رفته را پر می کند.
- اگر داده ورودی متن باشد، یک رمزگذار خودکار متن جدیدی تولید می کند که متن اصلی را تقلید می کند (اما مشابه نیست).
رمزگذارهای خودکار متغیر را نیز ببینید.
مدل خود رگرسیون
مدلی که پیش بینی را بر اساس پیش بینی های قبلی خود استنباط می کند. برای مثال، مدلهای زبان رگرسیون خودکار، نشانههای بعدی را بر اساس نشانههای پیشبینیشده قبلی پیشبینی میکنند. همه مدلهای زبان بزرگ مبتنی بر Transformer دارای رگرسیون خودکار هستند.
در مقابل، مدلهای تصویر مبتنی بر GAN معمولاً رگرسیون خودکار نیستند، زیرا آنها یک تصویر را در یک گذر به جلو و نه به صورت تکراری در مراحل تولید میکنند. با این حال، برخی از مدلهای تولید تصویر دارای رگرسیون خودکار هستند ، زیرا آنها یک تصویر را در مراحل تولید میکنند.
ب
کیسه کلمات
نمایشی از کلمات در یک عبارت یا متن، صرف نظر از ترتیب. به عنوان مثال، کیسه کلمات سه عبارت زیر را به طور یکسان نشان می دهد:
- سگ می پرد
- سگ را می پرد
- سگ می پرد
هر کلمه به یک شاخص در یک بردار پراکنده نگاشت می شود، که در آن بردار برای هر کلمه در واژگان یک شاخص دارد. به عنوان مثال، عبارت dog jumps در یک بردار ویژگی با مقادیر غیر صفر در سه شاخص مربوط به کلمات the , dog و jumps نگاشت می شود. مقدار غیر صفر می تواند یکی از موارد زیر باشد:
- A 1 برای نشان دادن وجود یک کلمه.
- تعداد دفعاتی که یک کلمه در کیسه ظاهر می شود. به عنوان مثال، اگر عبارت were the maroon dog یک سگ با خز قهوه ای است ، هر دو قهوه ای و سگ به صورت 2 نشان داده می شوند، در حالی که کلمات دیگر به عنوان 1 نمایش داده می شوند.
- مقدار دیگری مانند لگاریتم تعداد دفعاتی که یک کلمه در کیسه ظاهر می شود.
BERT (نمایش رمزگذار دوطرفه از ترانسفورماتورها)
معماری مدلی برای نمایش متن یک مدل BERT آموزش دیده می تواند به عنوان بخشی از یک مدل بزرگتر برای طبقه بندی متن یا سایر وظایف ML عمل کند.
BERT دارای ویژگی های زیر است:
- از معماری ترانسفورماتور استفاده می کند و بنابراین به خود توجهی متکی است.
- از بخش رمزگذار ترانسفورماتور استفاده می کند. وظیفه رمزگذار به جای انجام یک کار خاص مانند طبقه بندی، تولید بازنمایی متن خوب است.
- دو جهته است.
- از ماسک برای تمرینات بدون نظارت استفاده می کند.
انواع BERT عبارتند از:
برای مروری بر BERT به منبع باز BERT: پیشآموزش پیشرفته برای پردازش زبان طبیعی مراجعه کنید.
دو طرفه
اصطلاحی که برای توصیف سیستمی استفاده میشود که متنی را که هم قبل و هم بعد از یک بخش هدف از متن است، ارزیابی میکند. در مقابل، یک سیستم یک طرفه فقط متنی را که قبل از بخش هدفی از متن قرار دارد ارزیابی می کند.
به عنوان مثال، یک مدل زبان پوشانده شده را در نظر بگیرید که باید احتمالات کلمه یا کلماتی را که نشان دهنده خط زیر در سؤال زیر هستند تعیین کند:
_____ با شما چیست؟
یک مدل زبانی یک طرفه باید احتمالات خود را فقط بر اساس زمینه ارائه شده توسط کلمات "What"، "is" و "the" استوار کند. در مقابل، یک مدل زبان دوطرفه همچنین میتواند زمینه را از «با» و «شما» به دست آورد، که ممکن است به مدل کمک کند پیشبینیهای بهتری ایجاد کند.
مدل زبان دو طرفه
یک مدل زبان که احتمال وجود یک نشانه داده شده در یک مکان معین در گزیده ای از متن را بر اساس متن قبلی و بعدی تعیین می کند.
بیگرام
یک N گرم که در آن N=2 است.
BLEU (دو زبانه ارزیابی ارزشیابی)
امتیازی بین 0.0 تا 1.0، شامل کیفیت ترجمه بین دو زبان انسانی (مثلاً بین انگلیسی و روسی) است. نمره BLEU 1.0 نشان دهنده ترجمه کامل است. نمره BLEU 0.0 نشان دهنده یک ترجمه وحشتناک است.
سی
مدل زبان علی
مترادف مدل زبان تک جهتی .
برای تضاد رویکردهای مختلف جهتگیری در مدلسازی زبان ، مدل زبان دوطرفه را ببینید.
تحریک زنجیره ای از فکر
یک تکنیک مهندسی سریع که یک مدل زبان بزرگ (LLM) را تشویق می کند تا استدلال خود را گام به گام توضیح دهد. به عنوان مثال، با توجه خاص به جمله دوم، دستور زیر را در نظر بگیرید:
یک راننده چند گرم نیرو را در اتومبیلی که از 0 تا 60 مایل در ساعت در 7 ثانیه طی می کند تجربه می کند؟ در پاسخ، تمام محاسبات مربوطه را نشان دهید.
پاسخ LLM به احتمال زیاد:
- دنباله ای از فرمول های فیزیک را نشان دهید و مقادیر 0، 60 و 7 را در مکان های مناسب وصل کنید.
- توضیح دهید که چرا آن فرمول ها را انتخاب کرده است و معنی متغیرهای مختلف چیست.
تحریک زنجیرهای از فکر، LLM را مجبور میکند همه محاسبات را انجام دهد، که ممکن است به پاسخ صحیحتری منجر شود. علاوه بر این، تحریک زنجیرهای از فکر، کاربر را قادر میسازد تا مراحل LLM را برای تعیین اینکه آیا پاسخ منطقی است یا نه، بررسی کند.
چت کردن
محتویات یک گفتگوی رفت و برگشت با یک سیستم ML، معمولاً یک مدل زبان بزرگ . تعامل قبلی در یک چت (آنچه تایپ کردید و مدل زبان بزرگ چگونه پاسخ داد) زمینه ای برای بخش های بعدی گپ می شود.
چت بات یک برنامه کاربردی از یک مدل زبان بزرگ است.
confabulation
مترادف توهم .
Confabulation احتمالاً از نظر فنی دقیق تر از توهم است. با این حال، توهم ابتدا رایج شد.
تجزیه حوزه انتخابیه
تقسیم یک جمله به ساختارهای گرامری کوچکتر ("مواد تشکیل دهنده"). بخش بعدی سیستم ML، مانند یک مدل درک زبان طبیعی ، می تواند اجزای تشکیل دهنده را راحت تر از جمله اصلی تجزیه کند. برای مثال جمله زیر را در نظر بگیرید:
دوستم دو گربه را به فرزندی پذیرفت.
تجزیه کننده حوزه انتخابیه می تواند این جمله را به دو جزء زیر تقسیم کند:
- دوست من یک عبارت اسمی است.
- adopted two cats یک عبارت فعل است.
این اجزاء را می توان بیشتر به اجزای کوچکتر تقسیم کرد. مثلاً عبارت فعل
دو گربه را به فرزندی پذیرفت
را می توان بیشتر به زیر تقسیم کرد:
- اتخاذ یک فعل است.
- دو گربه یک عبارت اسمی دیگر است.
جاسازی زبان متنی
تعبیهای که به «درک» واژهها و عبارات به شیوههایی نزدیک میشود که گویشوران بومی انسان میتوانند. تعبیههای زبان متنی میتوانند نحو، معناشناسی و زمینه پیچیده را درک کنند.
برای مثال، تعبیههای کلمه انگلیسی cow را در نظر بگیرید. جاسازیهای قدیمیتر مانند word2vec میتوانند کلمات انگلیسی را نشان دهند به طوری که فاصله در فضای جاسازی از گاو تا گاو مشابه فاصله میش (گوسفند ماده) تا قوچ (گوسفند نر) یا از ماده تا نر است. تعبیههای زبانی متنی میتواند با درک این موضوع که انگلیسی زبانان گاهی اوقات به طور تصادفی از کلمه cow به معنای گاو یا گاو نر استفاده میکنند، قدمی فراتر بگذارند.
پنجره زمینه
تعداد نشانه هایی که یک مدل می تواند در یک دستور داده شده پردازش کند. هرچه پنجره زمینه بزرگتر باشد، مدل می تواند از اطلاعات بیشتری برای ارائه پاسخ های منسجم و منسجم به درخواست استفاده کند.
شکوفه تصادف
جمله یا عبارتی با معنای مبهم. شکوفه های تصادفی مشکل مهمی در درک زبان طبیعی ایجاد می کنند. به عنوان مثال، عنوان Red Tape Holds Up Skyscraper یک شکوفه سقوط است زیرا یک مدل NLU می تواند عنوان را به معنای واقعی کلمه یا مجازی تفسیر کند.
دی
رمزگشا
به طور کلی، هر سیستم ML که از یک نمایش پردازش شده، متراکم یا داخلی به یک نمایش خام تر، پراکنده تر یا خارجی تبدیل می شود.
رمزگشاها اغلب جزء یک مدل بزرگتر هستند، جایی که اغلب با یک رمزگذار جفت می شوند.
در کارهای ترتیب به دنباله ، رمزگشا با حالت داخلی تولید شده توسط رمزگذار شروع میشود تا دنباله بعدی را پیشبینی کند.
برای تعریف رمزگشا در معماری ترانسفورماتور به Transformer مراجعه کنید.
حذف نویز
یک رویکرد رایج برای یادگیری خود نظارتی که در آن:
حذف نویز امکان یادگیری از نمونه های بدون برچسب را فراهم می کند. مجموعه داده اصلی به عنوان هدف یا برچسب و داده های پر سر و صدا به عنوان ورودی عمل می کند.
برخی از مدلهای زبان پوشانده از حذف نویز به صورت زیر استفاده میکنند:
- نویز به طور مصنوعی با پوشاندن برخی از نشانه ها به یک جمله بدون برچسب اضافه می شود.
- مدل سعی می کند توکن های اصلی را پیش بینی کند.
تحریک مستقیم
مترادف عبارت zero-shot prompting .
E
فاصله را ویرایش کنید
اندازه گیری شباهت دو رشته متنی به یکدیگر. در یادگیری ماشینی، ویرایش فاصله مفید است، زیرا محاسبه آن ساده است، و روشی موثر برای مقایسه دو رشتهای که شناخته شدهاند مشابه هستند یا یافتن رشتههایی که شبیه به یک رشته معین هستند.
تعاریف متعددی از فاصله ویرایش وجود دارد که هر کدام از عملیات رشته های متفاوتی استفاده می کنند. به عنوان مثال، فاصله Levenshtein کمترین عملیات حذف، درج و جایگزینی را در نظر می گیرد.
به عنوان مثال، فاصله Levenshtein بین کلمات "قلب" و "دارت" 3 است زیرا 3 ویرایش زیر کمترین تغییر برای تبدیل یک کلمه به کلمه دیگر است:
- قلب ← عزیز (h را با "d" جایگزین کنید)
- deart → dart (حذف "e")
- دارت → دارت (درج "s")
لایه جاسازی
یک لایه مخفی ویژه که بر روی یک ویژگی طبقه بندی با ابعاد بالا آموزش می دهد تا به تدریج بردار تعبیه ابعاد پایین تر را یاد بگیرد. یک لایه جاسازی شبکه عصبی را قادر میسازد تا بسیار کارآمدتر از آموزش فقط بر روی ویژگی طبقهبندی با ابعاد بالا آموزش ببیند.
برای مثال، زمین در حال حاضر از حدود 73000 گونه درختی پشتیبانی می کند. فرض کنید گونه درختی یک ویژگی در مدل شما باشد، بنابراین لایه ورودی مدل شما شامل یک بردار یک داغ به طول 73000 عنصر است. برای مثال، شاید baobab چیزی شبیه به این نشان داده شود:

یک آرایه 73000 عنصری بسیار طولانی است. اگر یک لایه جاسازی به مدل اضافه نکنید، به دلیل ضرب 72999 صفر، آموزش بسیار وقت گیر خواهد بود. شاید لایه جاسازی را از 12 بعد انتخاب کنید. در نتیجه، لایه جاسازی به تدریج یک بردار تعبیه جدید برای هر گونه درختی را یاد می گیرد.
در شرایط خاص، هش جایگزین معقولی برای لایه جاسازی است.
فضای تعبیه شده
فضای برداری d بعدی که از یک فضای برداری با ابعاد بالاتر مشخص می شود به آن نگاشت می شود. در حالت ایده آل، فضای جاسازی شامل ساختاری است که نتایج ریاضی معناداری را به همراه دارد. به عنوان مثال، در یک فضای جاسازی ایده آل، جمع و تفریق جاسازی ها می تواند وظایف قیاس کلمه را حل کند.
حاصل ضرب نقطه ای دو جاسازی معیاری برای تشابه آنهاست.
وکتور تعبیه شده
به طور کلی، آرایه ای از اعداد ممیز شناور گرفته شده از هر لایه پنهان که ورودی های آن لایه پنهان را توصیف می کند. اغلب، یک بردار جاسازی آرایه ای از اعداد ممیز شناور است که در یک لایه جاسازی آموزش داده شده است. برای مثال، فرض کنید یک لایه جاسازی باید یک بردار جاسازی برای هر یک از ۷۳۰۰۰ گونه درختی روی زمین بیاموزد. شاید آرایه زیر بردار جاسازی یک درخت بائوباب باشد:

بردار تعبیه شده مجموعه ای از اعداد تصادفی نیست. یک لایه جاسازی این مقادیر را از طریق آموزش تعیین می کند، مشابه روشی که یک شبکه عصبی وزن های دیگر را در طول تمرین یاد می گیرد. هر عنصر از آرایه رتبه بندی در امتداد برخی از ویژگی های یک گونه درختی است. کدام عنصر مشخصه کدام گونه درخت است؟ تشخیص آن برای انسان ها بسیار سخت است.
بخش قابل توجه ریاضی یک بردار تعبیه شده این است که موارد مشابه دارای مجموعه های مشابهی از اعداد ممیز شناور هستند. به عنوان مثال، گونه های درختی مشابه دارای مجموعه اعداد ممیز شناور مشابهی نسبت به گونه های درختی غیر مشابه هستند. سرخوودها و سکویاها گونههای درختی مرتبط هستند، بنابراین مجموعهای از اعداد شناور شبیهتری نسبت به درختهای قرمز و نخل نارگیل خواهند داشت. اعداد در بردار جاسازی با هر بار آموزش مجدد مدل تغییر خواهند کرد، حتی اگر مدل را با ورودی یکسان دوباره آموزش دهید.
رمزگذار
به طور کلی، هر سیستم ML که از یک نمایش خام، پراکنده یا خارجی به یک نمایش پردازش شده تر، متراکم تر یا داخلی تر تبدیل می شود.
رمزگذارها اغلب جزء یک مدل بزرگتر هستند، جایی که اغلب با یک رمزگشا جفت می شوند. برخی از ترانسفورماتورها انکودرها را با رمزگشاها جفت می کنند، اگرچه سایر ترانسفورماتورها فقط از رمزگذار یا فقط رمزگشا استفاده می کنند.
برخی از سیستم ها از خروجی رمزگذار به عنوان ورودی یک شبکه طبقه بندی یا رگرسیون استفاده می کنند.
در وظایف ترتیب به دنباله ، یک رمزگذار یک دنباله ورودی را می گیرد و یک حالت داخلی (بردار) را برمی گرداند. سپس رمزگشا از آن حالت داخلی برای پیش بینی دنباله بعدی استفاده می کند.
برای تعریف رمزگذار در معماری ترانسفورماتور به Transformer مراجعه کنید.
اف
چند شات تحریک
درخواستی که حاوی بیش از یک («چند») مثال است که نشان میدهد مدل زبان بزرگ چگونه باید پاسخ دهد. برای مثال، دستور طولانی زیر حاوی دو مثال است که یک مدل زبان بزرگ را نشان می دهد که چگونه به یک پرس و جو پاسخ دهد.
| بخش هایی از یک فرمان | یادداشت ها |
|---|---|
| واحد پول رسمی کشور مشخص شده چیست؟ | سوالی که می خواهید LLM به آن پاسخ دهد. |
| فرانسه: یورو | یک مثال. |
| بریتانیا: GBP | مثال دیگر. |
| هند: | پرس و جو واقعی |
درخواستهای چند شات معمولاً نتایج مطلوبتری نسبت به درخواستهای صفر و یک شات ایجاد میکنند. با این حال، درخواست چند شات به یک اعلان طولانیتر نیاز دارد.
درخواست چند شات شکلی از یادگیری چند شات است که برای یادگیری مبتنی بر سریع اعمال می شود.
کمانچه
یک کتابخانه پیکربندی Python-first که مقادیر توابع و کلاسها را بدون کد یا زیرساخت مهاجم تنظیم میکند. در مورد Pax - و سایر پایگاههای کد ML - این توابع و کلاسها مدلها و فراپارامترهای آموزشی را نشان میدهند.
Fiddle فرض میکند که پایگاههای کد یادگیری ماشین معمولاً به دو دسته تقسیم میشوند:
- کد کتابخانه، که لایه ها و بهینه سازها را تعریف می کند.
- کد "چسب" مجموعه داده، که کتابخانه ها را فراخوانی می کند و همه چیز را به هم متصل می کند.
Fiddle ساختار فراخوانی کد چسب را به شکلی ارزیابی نشده و قابل تغییر به تصویر می کشد.
تنظیم دقیق
دومین پاس آموزشی ویژه کار بر روی یک مدل از پیش آموزش دیده انجام شد تا پارامترهای آن را برای یک مورد استفاده خاص اصلاح کند. به عنوان مثال، دنباله آموزش کامل برای برخی از مدل های زبان بزرگ به شرح زیر است:
- قبل از آموزش: یک مدل زبان بزرگ را بر روی یک مجموعه داده کلی گسترده، مانند تمام صفحات ویکی پدیا به زبان انگلیسی، آموزش دهید.
- تنظیم دقیق: مدل از پیش آموزش دیده را برای انجام یک کار خاص ، مانند پاسخ به سؤالات پزشکی، آموزش دهید. تنظیم دقیق معمولاً شامل صدها یا هزاران مثال متمرکز بر یک کار خاص است.
به عنوان مثال دیگر، دنباله آموزش کامل برای یک مدل تصویر بزرگ به شرح زیر است:
- قبل از آموزش: یک مدل تصویر بزرگ را بر روی یک مجموعه داده کلی تصویری گسترده، مانند تمام تصاویر موجود در Wikimedia Commons آموزش دهید.
- تنظیم دقیق: مدل از پیش آموزش دیده را برای انجام یک کار خاص ، مانند تولید تصاویر اورکا، آموزش دهید.
تنظیم دقیق می تواند شامل هر ترکیبی از استراتژی های زیر باشد:
- اصلاح تمام پارامترهای موجود مدل از پیش آموزش دیده. گاهی اوقات به آن تنظیم دقیق کامل می گویند.
- اصلاح تنها برخی از پارامترهای موجود مدل از قبل آموزش دیده (معمولاً، نزدیکترین لایه ها به لایه خروجی )، در حالی که سایر پارامترهای موجود را بدون تغییر نگه می دارد (معمولاً، لایه های نزدیک به لایه ورودی ). تنظیم کارآمد پارامتر را ببینید.
- افزودن لایههای بیشتر، معمولاً در بالای لایههای موجود که نزدیکترین لایه به لایه خروجی است.
تنظیم دقیق شکلی از یادگیری انتقالی است. به این ترتیب، تنظیم دقیق ممکن است از یک تابع تلفات متفاوت یا نوع مدل متفاوتی نسبت به مواردی که برای آموزش مدل از پیش آموزش دیده استفاده میشود، استفاده کند. به عنوان مثال، میتوانید یک مدل تصویر بزرگ از قبل آموزشدیده را برای تولید یک مدل رگرسیونی تنظیم کنید که تعداد پرندگان در یک تصویر ورودی را برمیگرداند.
تنظیم دقیق را با عبارات زیر مقایسه و مقایسه کنید:
کتان
یک کتابخانه منبع باز با کارایی بالا برای یادگیری عمیق که بر روی JAX ساخته شده است. Flax عملکردهایی را برای آموزش شبکه های عصبی و همچنین روش هایی برای ارزیابی عملکرد آنها ارائه می دهد.
کتان ساز
یک کتابخانه Transformer منبع باز، ساخته شده بر روی Flax ، که عمدتا برای پردازش زبان طبیعی و تحقیقات چندوجهی طراحی شده است.
جی
هوش مصنوعی مولد
یک میدان تحولآفرین در حال ظهور بدون تعریف رسمی. گفته میشود، اکثر کارشناسان موافق هستند که مدلهای هوش مصنوعی تولیدی میتوانند محتوایی را ایجاد کنند ("تولید") که همه موارد زیر باشد:
- مجتمع
- منسجم
- اصلی
به عنوان مثال، یک مدل هوش مصنوعی مولد می تواند مقالات یا تصاویر پیچیده ای ایجاد کند.
برخی از فناوریهای قبلی، از جمله LSTM و RNN ، میتوانند محتوای اصلی و منسجم تولید کنند. برخی از کارشناسان این فناوری های قبلی را به عنوان هوش مصنوعی مولد می دانند، در حالی که برخی دیگر احساس می کنند که هوش مصنوعی مولد واقعی به خروجی پیچیده تری نسبت به فناوری های قبلی نیاز دارد.
در مقابل ML پیش بینی .
GPT (ترانسفورماتور از پیش آموزش دیده ژنراتور)
خانواده ای از مدل های زبان بزرگ مبتنی بر Transformer که توسط OpenAI توسعه یافته است.
انواع GPT می توانند برای چندین روش اعمال شوند، از جمله:
- تولید تصویر (مثلا ImageGPT)
- تولید متن به تصویر (به عنوان مثال، DALL-E ).
اچ
توهم
تولید خروجی به ظاهر قابل قبول اما از نظر واقعی نادرست توسط یک مدل هوش مصنوعی مولد که ادعا می کند در مورد دنیای واقعی ادعا می کند. به عنوان مثال، یک مدل هوش مصنوعی مولد که ادعا می کند باراک اوباما در سال 1865 درگذشت توهم آور است.
من
یادگیری درون متنی
مترادف اعلان چند شات .
L
LaMDA (مدل زبانی برای برنامههای گفتگو)
یک مدل زبان بزرگ مبتنی بر ترانسفورماتور که توسط Google ایجاد شده است که بر روی یک مجموعه داده گفتگوی بزرگ آموزش داده شده است که می تواند پاسخ های مکالمه واقعی ایجاد کند.
LaMDA: فناوری مکالمه پیشرفت ما یک نمای کلی ارائه می دهد.
مدل زبان
مدلی که احتمال وقوع یک توکن یا دنباله ای از توکن ها را در یک دنباله طولانی تر از توکن ها تخمین می زند.
مدل زبان بزرگ
یک اصطلاح غیررسمی بدون تعریف دقیق که معمولاً به معنای مدل زبانی است که تعداد پارامترهای بالایی دارد. برخی از مدل های زبان بزرگ حاوی بیش از 100 میلیارد پارامتر هستند.
فضای نهفته
مترادف برای جاسازی فضا .
LLM
مخفف مدل زبان بزرگ .
LoRA
مخفف عبارت Low-Rank Adaptability .
سازگاری با رتبه پایین (LoRA)
الگوریتمی برای انجام تنظیم کارآمد پارامتر که تنها زیرمجموعهای از پارامترهای یک مدل زبان بزرگ را تنظیم میکند . LoRA مزایای زیر را ارائه می دهد:
- تنظیم دقیقتر از تکنیکهایی که نیاز به تنظیم دقیق همه پارامترهای مدل دارند.
- هزینه محاسباتی استنتاج در مدل دقیق تنظیم شده را کاهش می دهد.
مدل تنظیم شده با LoRA کیفیت پیش بینی های خود را حفظ یا بهبود می بخشد.
LoRA چندین نسخه تخصصی یک مدل را فعال می کند.
م
مدل زبان نقاب دار
یک مدل زبان که احتمال توکنهای کاندید را برای پر کردن جاهای خالی در یک دنباله پیشبینی میکند. به عنوان مثال، یک مدل زبان ماسکدار میتواند احتمالات کلمه(های) نامزد را برای جایگزینی خط زیر در جمله زیر محاسبه کند:
____ در کلاه برگشت.
ادبیات معمولاً از رشته "MASK" به جای زیر خط استفاده می کند. به عنوان مثال:
"ماسک" در کلاه برگشت.
بیشتر مدلهای زبان نقابدار مدرن دو جهته هستند.
فرا یادگیری
زیر مجموعه ای از یادگیری ماشینی که الگوریتم یادگیری را کشف یا بهبود می بخشد. هدف یک سیستم فرا یادگیری میتواند آموزش مدلی برای یادگیری سریع یک کار جدید از روی مقدار کمی داده یا تجربیات به دست آمده در کارهای قبلی باشد. الگوریتم های فرا یادگیری به طور کلی سعی در دستیابی به موارد زیر دارند:
- بهبود یا یادگیری ویژگی های مهندسی شده با دست (مانند یک اولیه یا یک بهینه ساز).
- از نظر داده کارآمدتر و از نظر محاسباتی کارآمدتر باشید.
- بهبود تعمیم.
فرایادگیری با یادگیری چند شات مرتبط است.
روش
یک دسته داده سطح بالا. به عنوان مثال، اعداد، متن، تصاویر، ویدئو و صدا پنج حالت مختلف هستند.
موازی سازی مدل
روشی برای مقیاس بندی آموزش یا استنباط که بخش های مختلف یک مدل را در دستگاه های مختلف قرار می دهد. موازی سازی مدل ها، مدل هایی را قادر می سازد که بیش از حد بزرگ هستند که روی یک دستگاه قرار بگیرند.
برای پیاده سازی موازی سازی مدل، یک سیستم معمولاً موارد زیر را انجام می دهد:
- مدل را به قطعات کوچکتر تقسیم می کند.
- آموزش آن قطعات کوچکتر را بین چندین پردازنده توزیع می کند. هر پردازنده بخشی از مدل خود را آموزش می دهد.
- نتایج را برای ایجاد یک مدل واحد ترکیب می کند.
موازی سازی مدل آموزش را کند می کند.
همچنین به موازی سازی داده ها مراجعه کنید.
خود توجهی چند سر
گسترش توجه به خود که مکانیسم توجه به خود را چندین بار برای هر موقعیت در دنباله ورودی اعمال می کند.
ترانسفورماتورها خود توجهی چند سر را معرفی کردند.
مدل چندوجهی
مدلی که ورودی و/یا خروجی آن شامل بیش از یک مدالیته است. به عنوان مثال، مدلی را در نظر بگیرید که هم یک تصویر و هم یک عنوان متن (دو حالت) را به عنوان ویژگی می گیرد، و یک امتیاز به دست می دهد که نشان می دهد عنوان متن برای تصویر چقدر مناسب است. بنابراین ورودی های این مدل چند وجهی و خروجی تک وجهی است.
ن
درک زبان طبیعی
تعیین مقاصد کاربر بر اساس آنچه کاربر تایپ کرده یا گفته است. به عنوان مثال، یک موتور جستجو از درک زبان طبیعی استفاده می کند تا مشخص کند کاربر چه چیزی را بر اساس آنچه کاربر تایپ کرده یا گفته است، جستجو می کند.
N-گرم
دنباله ای منظم از N کلمه. به عنوان مثال، واقعا دیوانه وار یک 2 گرم است. از آنجا که نظم مرتبط است، madly true یک 2 گرم متفاوت از واقعا دیوانه است.
| ن | نام(های) این نوع N-gram | نمونه ها |
|---|---|---|
| 2 | بیگرم یا 2 گرم | رفتن، رفتن، ناهار خوردن، شام خوردن |
| 3 | سه گرم یا 3 گرم | زیاد خورد، سه موش کور، زنگ به صدا درآمد |
| 4 | 4 گرم | قدم زدن در پارک، گرد و غبار در باد، پسر عدس خورد |
بسیاری از مدلهای درک زبان طبیعی برای پیشبینی کلمه بعدی که کاربر تایپ میکند یا میگوید، بر N-gram تکیه میکنند. برای مثال، فرض کنید کاربری سه blind را تایپ کرده است. یک مدل NLU بر اساس سهگرامها احتمالاً پیشبینی میکند که کاربر بعدی موشها را تایپ خواهد کرد.
N-gram ها را با کیسه کلمات ، که مجموعه های نامرتب از کلمات هستند، مقایسه کنید.
NLU
مخفف درک زبان طبیعی .
O
درخواست تک شات
درخواستی که حاوی یک مثال است که نشان می دهد مدل زبان بزرگ چگونه باید پاسخ دهد. برای مثال، دستور زیر حاوی یک مثال است که یک مدل زبان بزرگ را نشان می دهد که چگونه باید به یک پرس و جو پاسخ دهد.
| بخش هایی از یک فرمان | یادداشت ها |
|---|---|
| واحد پول رسمی کشور مشخص شده چیست؟ | سوالی که می خواهید LLM به آن پاسخ دهد. |
| فرانسه: یورو | یک مثال. |
| هند: | پرس و جو واقعی |
اعلان یک شات را با عبارات زیر مقایسه و مقایسه کنید:
پ
تنظیم کارآمد از نظر پارامتر
مجموعهای از تکنیکها برای تنظیم دقیق یک مدل زبان بزرگ از پیش آموزشدیده (PLM) با کارآمدی بیشتر از تنظیم دقیق کامل. تنظیم کارآمد پارامتر معمولاً پارامترهای بسیار کمتری را نسبت به تنظیم دقیق کامل تنظیم میکند، اما به طور کلی یک مدل زبان بزرگ تولید میکند که به خوبی (یا تقریباً به همان اندازه) یک مدل زبان بزرگ ساخته شده از تنظیم دقیق کامل عمل میکند.
مقایسه و کنتراست تنظیم کارآمد پارامتر با:
تنظیم کارآمد پارامتر نیز به عنوان تنظیم دقیق پارامتر کارآمد شناخته می شود.
خط لوله
شکلی از موازی سازی مدل که در آن پردازش مدل به مراحل متوالی تقسیم می شود و هر مرحله بر روی دستگاه متفاوتی اجرا می شود. در حالی که یک مرحله در حال پردازش یک دسته است، مرحله قبل می تواند روی دسته بعدی کار کند.
آموزش مرحلهای را نیز ببینید.
PLM
مخفف مدل زبان از پیش آموزش دیده .
رمزگذاری موقعیتی
تکنیکی برای افزودن اطلاعات در مورد موقعیت یک توکن در یک دنباله به جاسازی توکن. مدلهای ترانسفورماتور از رمزگذاری موقعیتی برای درک بهتر رابطه بین بخشهای مختلف دنباله استفاده میکنند.
اجرای رایج رمزگذاری موقعیتی از یک تابع سینوسی استفاده می کند. (به طور خاص، فرکانس و دامنه تابع سینوسی با موقعیت توکن در دنباله تعیین می شود.) این تکنیک یک مدل ترانسفورماتور را قادر می سازد تا یاد بگیرد که به قسمت های مختلف دنباله بر اساس موقعیت آنها توجه کند.
مدل از پیش آموزش دیده
مدلها یا اجزای مدل (مانند بردار تعبیهشده ) که قبلاً آموزش داده شدهاند. گاهی اوقات، بردارهای تعبیه شده از قبل آموزش دیده را به یک شبکه عصبی وارد می کنید. مواقع دیگر، مدل شما به جای اینکه به جاسازی های از پیش آموزش داده شده تکیه کند، خود بردارهای جاسازی را آموزش می دهد.
اصطلاح مدل زبانی از پیش آموزش دیده به یک مدل زبان بزرگ اطلاق می شود که دوره های پیش آموزشی را پشت سر گذاشته است.
قبل از آموزش
آموزش اولیه یک مدل بر روی یک مجموعه داده بزرگ. برخی از مدل های از پیش آموزش دیده غول های دست و پا چلفتی هستند و معمولاً باید از طریق آموزش های اضافی اصلاح شوند. به عنوان مثال، کارشناسان ML ممکن است یک مدل زبان بزرگ را در یک مجموعه داده متنی گسترده، مانند تمام صفحات انگلیسی در ویکیپدیا، از قبل آموزش دهند. پس از پیش آموزش، مدل به دست آمده ممکن است از طریق هر یک از تکنیک های زیر اصلاح شود:
سریع
هر متنی که به عنوان ورودی به یک مدل زبان بزرگ وارد می شود تا مدل به روشی خاص رفتار کند. درخواستها میتوانند به کوتاهی یک عبارت یا دلخواه طولانی باشند (مثلاً کل متن یک رمان). درخواستها به چند دسته تقسیم میشوند، از جمله مواردی که در جدول زیر نشان داده شدهاند:
| دسته بندی سریع | مثال | یادداشت ها |
|---|---|---|
| سوال | یک کبوتر با چه سرعتی می تواند پرواز کند؟ | |
| دستورالعمل | یک شعر خنده دار در مورد آربیتراژ بنویسید. | اعلانی که از مدل زبان بزرگ می خواهد کاری انجام دهد . |
| مثال | کد Markdown را به HTML ترجمه کنید. به عنوان مثال: علامت گذاری: * آیتم لیست HTML: <ul> <li>مورد فهرست</li> </ul> | اولین جمله در این اعلان مثال یک دستورالعمل است. باقیمانده اعلان مثال است. |
| نقش | توضیح دهید که چرا از شیب نزول در آموزش یادگیری ماشین تا مقطع دکتری فیزیک استفاده می شود. | قسمت اول جمله یک دستور است; عبارت "به یک دکترا در فیزیک" بخش نقش است. |
| ورودی جزئی برای تکمیل مدل | نخست وزیر بریتانیا در | یک اعلان ورودی جزئی می تواند یا به طور ناگهانی پایان یابد (همانطور که در این مثال انجام می شود) یا با یک خط زیر به پایان برسد. |
یک مدل هوش مصنوعی مولد میتواند به یک درخواست با متن، کد، تصاویر، جاسازیها ، ویدیوها و… تقریباً هر چیزی پاسخ دهد.
یادگیری مبتنی بر سریع
قابلیتی از مدلهای خاص که آنها را قادر میسازد رفتار خود را در پاسخ به ورودی متن دلخواه ( اعلانها ) تطبیق دهند. در یک الگوی یادگیری معمولی مبتنی بر سریع، یک مدل زبان بزرگ با تولید متن به یک درخواست پاسخ می دهد. به عنوان مثال، فرض کنید یک کاربر دستور زیر را وارد می کند:
قانون سوم حرکت نیوتن را خلاصه کنید.
مدلی که قادر به یادگیری مبتنی بر سریع باشد به طور خاص برای پاسخ دادن به درخواست قبلی آموزش داده نشده است. در عوض، مدل حقایق زیادی در مورد فیزیک، چیزهای زیادی در مورد قواعد عمومی زبان، و چیزهای زیادی در مورد آنچه پاسخهای به طور کلی مفید است، میداند. این دانش برای ارائه یک پاسخ مفید (امیدوارم) کافی است. بازخورد اضافی انسانی ("آن پاسخ خیلی پیچیده بود." یا "واکنش چیست؟") برخی از سیستم های یادگیری مبتنی بر فوری را قادر می سازد تا به تدریج سودمندی پاسخ های خود را بهبود بخشند.
طراحی سریع
مترادف کلمه مهندسی سریع .
مهندسی سریع
هنر ایجاد اعلانهایی که پاسخهای مورد نظر را از یک مدل زبان بزرگ استخراج میکنند. انسان ها مهندسی سریع انجام می دهند. نوشتن اعلانهای با ساختار مناسب، بخش مهمی از حصول اطمینان از پاسخهای مفید از یک مدل زبان بزرگ است. مهندسی سریع به عوامل زیادی بستگی دارد، از جمله:
- مجموعه داده برای پیشآموزش و احتمالاً تنظیم دقیق مدل زبان بزرگ استفاده میشود.
- دما و سایر پارامترهای رمزگشایی که مدل برای تولید پاسخ استفاده می کند.
برای جزئیات بیشتر در مورد نوشتن اعلان های مفید به مقدمه طراحی اعلان مراجعه کنید.
طراحی سریع مترادف مهندسی سریع است.
تنظیم سریع
یک مکانیسم تنظیم کارآمد پارامتری که یک "پیشوند" را می آموزد که سیستم آن را به اعلان واقعی نشان می دهد.
یک تغییر تنظیم سریع - بعضی اوقات به نام تنظیم پیشوند - برای پیش بینی پیشوند در هر لایه است . در مقابل ، بیشتر تنظیم سریع فقط پیشوند به لایه ورودی اضافه می کند.
آر
نقش
بخش اختیاری از سریع که مخاطب هدف را برای پاسخ یک مدل AI تولیدی مشخص می کند. بدون فوریت نقش ، یک مدل زبان بزرگ پاسخی را ارائه می دهد که ممکن است برای شخصی که سوالات را پرسیده یا ممکن است مفید نباشد. با یک فوریت نقش ، یک مدل بزرگ زبان می تواند به روشی پاسخ دهد که مناسب تر و مفیدتر برای مخاطب هدف خاص باشد. به عنوان مثال ، بخش سریع نقش از مطالب زیر در BOLDFACE است:
- این مقاله را برای دکترای اقتصاد خلاصه کنید.
- توضیح دهید که چگونه جزر و مد برای یک کودک ده ساله کار می کند.
- بحران مالی سال 2008 را توضیح دهید. همانطور که ممکن است با یک کودک خردسال یا یک بازپرداخت طلایی صحبت کنید.
اس
خودآگاهی (که به آن لایه خود توجه نیز گفته می شود)
یک لایه شبکه عصبی که دنباله ای از تعبیه ها (به عنوان مثال ، تعبیه شده) را به دنباله دیگری از تعبیه ها تبدیل می کند. هر تعبیه در دنباله خروجی با ادغام اطلاعات از عناصر دنباله ورودی از طریق مکانیسم توجه ساخته می شود.
بخشی از خود توجه به دنباله ای که در آن حضور دارد و نه به برخی از زمینه های دیگر اشاره دارد. خودآگاهی یکی از اصلی ترین بلوک های ساختمانی برای ترانسفورماتورها است و از اصطلاحات جستجوی فرهنگ لغت مانند "پرس و جو" ، "کلید" و "ارزش" استفاده می کند.
یک لایه خودآگاهی با دنباله ای از بازنمایی های ورودی ، یکی برای هر کلمه شروع می شود. بازنمایی ورودی برای یک کلمه می تواند یک تعبیه ساده باشد. برای هر کلمه در یک دنباله ورودی ، شبکه ارتباط این کلمه را با هر عنصر در کل دنباله کلمات نشان می دهد. نمرات ارتباطی تعیین می کند که نمای نهایی کلمه چقدر بازنمایی کلمات دیگر را در بر می گیرد.
به عنوان مثال ، جمله زیر را در نظر بگیرید:
حیوان از خیابان عبور نکرد زیرا خیلی خسته بود.
تصویر زیر (از Transformer: یک معماری شبکه عصبی جدید برای درک زبان ) الگوی توجه یک لایه خود را برای ضمیر آن نشان می دهد ، با تاریکی هر خط نشان می دهد که هر کلمه چقدر به بازنمایی کمک می کند:

لایه خودآگاهی کلماتی را که مربوط به "آن" است ، برجسته می کند. در این حالت ، لایه توجه آموخته است که کلماتی را که ممکن است به آن اشاره کنند ، برجسته کند و بالاترین وزن را به حیوان اختصاص دهد.
برای دنباله ای از نشانه های N ، خود توجه ، دنباله ای از تعبیه N زمان جداگانه را تغییر می دهد ، یک بار در هر موقعیت در دنباله.
همچنین به توجه و توجه خود چند سر مراجعه کنید.
تحلیل احساسات
استفاده از الگوریتم های آماری یا یادگیری ماشین برای تعیین نگرش کلی یک گروه - مثبت یا منفی - یک سرویس ، محصول ، سازمان یا موضوع را نشان می دهد. به عنوان مثال ، با استفاده از درک زبان طبیعی ، یک الگوریتم می تواند تجزیه و تحلیل احساساتی را در بازخورد متنی از یک دوره دانشگاه انجام دهد تا میزان دانش آموزان را به طور کلی دوست داشته باشد یا از این دوره استفاده کند.
کار توالی به توالی
وظیفه ای که یک توالی ورودی از نشانه ها را به یک توالی خروجی از نشانه ها تبدیل می کند. به عنوان مثال ، دو نوع محبوب از وظایف دنباله به دنباله عبارتند از:
- مترجمان:
- دنباله ورودی نمونه: "من تو را دوست دارم."
- دنباله خروجی نمونه: "je t'aime."
- پاسخ سوال:
- دنباله ورودی نمونه: "آیا من به ماشین خود در شهر نیویورک احتیاج دارم؟"
- دنباله خروجی نمونه: "نه. لطفاً ماشین خود را در خانه نگه دارید."
پرش
N-Gram که ممکن است کلمات (یا "پرش") را از متن اصلی حذف کند ، به این معنی که ممکن است کلمات N در ابتدا مجاور نبوده باشد. به طور دقیق تر ، "k-skip-n-gram" یک n-gram است که ممکن است کلمات k از بین برود.
به عنوان مثال ، "روباه قهوه ای سریع" دارای 2 گرم ممکن است:
- "سریع"
- "قهوه ای سریع"
- "روباه قهوه ای"
"1-Skip-2-Gram" یک جفت کلمه است که حداکثر 1 کلمه بین آنها وجود دارد. بنابراین ، "روباه قهوه ای سریع" دارای 2-گرم 2-SKIP زیر است:
- "قهوه ای"
- "روباه سریع"
علاوه بر این ، تمام 2 گرم نیز 1-Skip-2-Grams هستند ، زیرا ممکن است کمتر از یک کلمه پرش شود.
Skip-Grams برای درک بیشتر در مورد یک کلمه اطراف مفید است. در مثال ، "روباه" مستقیماً در مجموعه 1-skip-2 گرم با "سریع" همراه بود ، اما در مجموعه 2 گرم نیست.
Skip-Grams به آموزش مدل های تعبیه کننده کلمه کمک می کند.
تنظیم سریع نرم
تکنیکی برای تنظیم یک مدل زبان بزرگ برای یک کار خاص ، بدون تنظیم دقیق منابع. به جای بازآفرینی تمام وزنهای موجود در مدل ، تنظیم سریع نرم به طور خودکار یک سریع را تنظیم می کند تا به همان هدف برسد.
با توجه به یک متن متنی ، تنظیم سریع نرم به طور معمول تعبیه های اضافی را به سریع اضافه می کند و از backpropagation برای بهینه سازی ورودی استفاده می کند.
سریع "سخت" حاوی نشانه های واقعی به جای تعبیه های نشانه است.
ویژگی پراکنده
ویژگی ای که مقادیر آن عمدتا صفر یا خالی است. به عنوان مثال ، یک ویژگی حاوی یک مقدار 1 و یک میلیون مقدار 0 مقدار پراکنده است. در مقابل ، یک ویژگی متراکم دارای مقادیری است که عمدتا صفر یا خالی نیستند.
در یادگیری ماشین ، تعداد غافلگیرکننده ای از ویژگی ها از ویژگی های پراکنده هستند. ویژگی های طبقه بندی شده معمولاً ویژگی های پراکنده است. به عنوان مثال ، از 300 گونه درخت ممکن در یک جنگل ، یک مثال واحد ممکن است فقط یک درخت افرا را شناسایی کند. یا از میلیون ها فیلم ممکن در یک کتابخانه ویدیویی ، یک مثال واحد ممکن است فقط "Casablanca" را مشخص کند.
در یک مدل ، شما به طور معمول ویژگی های پراکنده را با رمزگذاری یک داغ نشان می دهید. اگر رمزگذاری یک داغ بزرگ باشد ، ممکن است یک لایه تعبیه شده را در بالای رمزگذاری یک داغ برای راندمان بیشتر قرار دهید.
نمایش پراکنده
ذخیره فقط موقعیت (های) عناصر nonzero در یک ویژگی پراکنده.
به عنوان مثال ، فرض کنید یک ویژگی طبقه بندی شده به نام species 36 گونه درخت را در یک جنگل خاص مشخص می کند. بیشتر فرض کنید که هر مثال فقط یک گونه واحد را مشخص می کند.
در هر مثال می توانید از یک بردار یک داغ استفاده کنید تا گونه های درخت را نشان دهد. یک بردار یک داغ حاوی 1 (برای نشان دادن گونه های خاص درخت در آن مثال) و 35 0 ثانیه (برای نشان دادن 35 گونه درختی که در آن مثال نیست ). بنابراین ، نمایش یک داغ maple ممکن است چیزی شبیه به موارد زیر باشد:

از طرف دیگر ، نمایندگی پراکنده به سادگی موقعیت گونه های خاص را مشخص می کند. اگر maple در موقعیت 24 قرار داشته باشد ، نمایش پراکنده maple به سادگی خواهد بود:
24
توجه کنید که نمایندگی پراکنده بسیار فشرده تر از نمایندگی یک داغ است.
برای مثال کمی پیچیده تر روی نماد کلیک کنید.
فرض کنید هر نمونه در مدل شما باید کلمات را نشان دهد - اما نه ترتیب آن کلمات - در یک جمله انگلیسی. انگلیسی از حدود 170،000 کلمه تشکیل شده است ، بنابراین انگلیسی یک ویژگی طبقه بندی شده با حدود 170،000 عنصر است. بیشتر جملات انگلیسی از بخش بسیار کوچکی از 170،000 کلمه استفاده می کنند ، بنابراین مجموعه ای از کلمات در یک مثال واحد تقریباً مطمئناً داده های پراکنده خواهد بود.
جمله زیر را در نظر بگیرید:
My dog is a great dog
برای نشان دادن کلمات در این جمله می توانید از یک نوع وکتور یک داغ استفاده کنید. در این نوع ، سلول های متعدد در وکتور می توانند حاوی مقدار غیرزرو باشند. علاوه بر این ، در این نوع ، یک سلول می تواند دارای یک عدد صحیح غیر از یک باشد. اگرچه کلمات "من" ، "،" A "و" عالی "فقط یک بار در جمله ظاهر می شوند ، کلمه" سگ "دو بار ظاهر می شود. با استفاده از این نوع بردارهای یک داغ برای نشان دادن کلمات در این جمله ، بردار 170،000 عنصر زیر را به همراه می آورد:

بازنمایی پراکنده از همان جمله به سادگی خواهد بود:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
آموزش صحنه
تاکتیک آموزش یک مدل در دنباله ای از مراحل گسسته. هدف می تواند سرعت بخشیدن به روند آموزش یا دستیابی به کیفیت مدل بهتر باشد.
تصویری از رویکرد انباشت پیشرو در زیر نشان داده شده است:
- مرحله 1 شامل 3 لایه پنهان ، مرحله 2 شامل 6 لایه پنهان است و مرحله 3 حاوی 12 لایه پنهان است.
- مرحله 2 با وزنهای آموخته شده در 3 لایه پنهان مرحله 1 ، تمرین را آغاز می کند. مرحله 3 با وزنهای آموخته شده در 6 لایه پنهان مرحله 2 تمرین را شروع می کند.
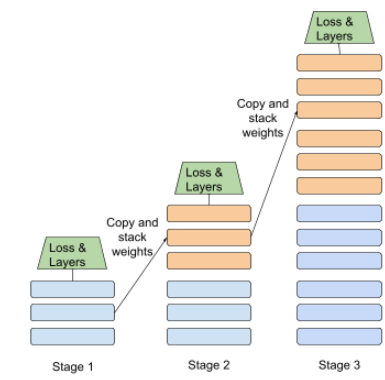
همچنین به لوله کشی مراجعه کنید.
زیر کلمه
در مدل های زبان ، نشانه ای که زیرزمینی از یک کلمه است ، که ممکن است کل کلمه باشد.
به عنوان مثال ، کلمه ای مانند "actionize" ممکن است در قطعات "مورد" (یک کلمه ریشه) و "ize" (پسوند) شکسته شود ، که هر یک از آنها توسط نشانه خاص خود نشان داده شده است. تقسیم کلمات غیر معمول در چنین قطعاتی ، به نام های زیر کلمات ، به مدل های زبان اجازه می دهد تا روی قسمت های تشکیل دهنده متداول تر این کلمه مانند پیشوندها و پسوندها کار کنند.
در مقابل ، کلمات متداول مانند "رفتن" ممکن است شکسته نشود و ممکن است توسط یک نشانه واحد نشان داده شود.
تی
T5
یک مدل یادگیری انتقال متن به متن که توسط Google AI در سال 2020 معرفی شده است. T5 یک مدل رمزگذار - رمزگشایی است که بر اساس معماری ترانسفورماتور ، که بر روی یک مجموعه داده بسیار بزرگ آموزش دیده است. در انواع مختلفی از کارهای پردازش زبان طبیعی مانند تولید متن ، ترجمه زبان و پاسخ دادن به سؤالات به صورت مکالمه مؤثر است.
T5 نام خود را از پنج T در "ترانسفورماتور انتقال متن به متن" دریافت می کند.
T5x
یک چارچوب یادگیری با منبع باز ، برای ساخت و آموزش مدلهای پردازش زبان طبیعی در مقیاس بزرگ (NLP) طراحی شده است. T5 بر روی کد T5X (که بر روی JAX و کتان ساخته شده است) پیاده سازی می شود.
دما
هیپرپارامتر که میزان تصادفی بودن خروجی یک مدل را کنترل می کند. درجه حرارت بالاتر منجر به خروجی تصادفی تر می شود ، در حالی که دمای پایین تر منجر به خروجی تصادفی کمتری می شود.
انتخاب بهترین دما به کاربرد خاص و خصوصیات ارجح خروجی مدل بستگی دارد. به عنوان مثال ، شما احتمالاً هنگام ایجاد برنامه ای که تولید خلاق را ایجاد می کند ، دما را بالا می برید. برعکس ، شما احتمالاً هنگام ساختن مدلی که تصاویر یا متن را طبقه بندی می کند ، دما را پایین می آورید تا دقت و قوام مدل را بهبود بخشید.
درجه حرارت اغلب با SoftMax استفاده می شود.
طول متن
دهانه شاخص آرایه مرتبط با یک بخش خاص از یک رشته متن. به عنوان مثال ، کلمه good در رشته Python s="Be good now" دهانه متن را از 3 تا 6 اشغال می کند.
نشانه
در یک مدل زبان ، واحد اتمی که مدل در حال آموزش است و پیش بینی می کند. یک نشانه به طور معمول یکی از موارد زیر است:
- یک کلمه - برای مثال ، عبارت "سگ ها مانند گربه ها" از سه نشانه کلمه تشکیل شده است: "سگ" ، "مانند" و "گربه".
- یک شخصیت - به عنوان مثال ، عبارت "ماهی دوچرخه" از نه نشانه شخصیت تشکیل شده است. (توجه داشته باشید که فضای خالی یکی از نشانه ها است.)
- زیرزمین ها - که در آن یک کلمه واحد می تواند یک نشانه واحد یا چند نشانه باشد. یک زیرزمین از یک کلمه ریشه ، پیشوند یا پسوند تشکیل شده است. به عنوان مثال ، یک مدل زبانی که از کلمات زیرزمینی به عنوان نشانه ها استفاده می کند ، ممکن است کلمه "سگ" را به عنوان دو نشانه مشاهده کند (کلمه ریشه "سگ" و پسوند جمع "S"). همین مدل زبان ممکن است کلمه تک "بلندتر" را به عنوان دو زیر کلمه (کلمه ریشه "بلند" و پسوند "er") مشاهده کند.
در حوزه های خارج از مدل های زبان ، نشانه ها می توانند انواع دیگر واحدهای اتمی را نشان دهند. به عنوان مثال ، در Vision Computer ، یک نشانه ممکن است زیر مجموعه یک تصویر باشد.
ترانسفورماتور
یک معماری شبکه عصبی که در گوگل ایجاد شده است و به مکانیسم های خودآگاهی متکی است تا دنباله ای از تعبیه های ورودی را به دنباله ای از تعبیه های خروجی تبدیل کند بدون اینکه به پیچیدگی ها یا شبکه های عصبی مکرر تکیه کند. ترانسفورماتور را می توان به عنوان پشته ای از لایه های خودآزمایی مشاهده کرد.
یک ترانسفورماتور می تواند شامل هر یک از موارد زیر باشد:
یک رمزگذار دنباله ای از تعبیه ها را به یک دنباله جدید با همان طول تبدیل می کند. یک رمزگذار شامل لایه های یکسان N است که هر یک از آنها شامل دو لایه فرعی است. این دو لایه زیر در هر موقعیت از توالی تعبیه شده ورودی اعمال می شود و هر عنصر از دنباله را به یک تعبیه جدید تبدیل می کند. اولین زیر لایه رمزگذار اطلاعات را از طریق دنباله ورودی جمع می کند. زیر لایه رمزگذار دوم اطلاعات جمع شده را به یک تعبیه خروجی تبدیل می کند.
یک رمزگشایی دنباله ای از تعبیه های ورودی را به دنباله ای از تعبیه های خروجی تبدیل می کند ، احتمالاً با طول متفاوت. یک رمزگشایی همچنین شامل لایه های یکسان N با سه لایه زیر است که دو مورد از آنها شبیه به زیر لایه های رمزگذار است. لایه سوم رمزگشایی سوم خروجی رمزگذار را می گیرد و از مکانیسم خودآگاهی برای جمع آوری اطلاعات از آن استفاده می کند.
Transformer پست وبلاگ: یک معماری جدید شبکه عصبی برای درک زبان ، مقدمه خوبی برای ترانسفورماتورها فراهم می کند.
سه گرام
N-Gram که در آن n = 3.
U
یک طرفه
سیستمی که فقط متنی را که پیش از یک بخش هدف از متن است ارزیابی می کند. در مقابل ، یک سیستم دو طرفه متنی را که پیش از آن است ارزیابی می کند و از بخش هدف متن پیروی می کند . برای اطلاعات بیشتر به دو طرفه مراجعه کنید.
مدل زبان یک طرفه
یک الگوی زبانی که احتمالات خود را فقط بر روی نشانه هایی که قبلاً ظاهر می شوند ، نه بعد از آن ، نشانه (های) هدف قرار می دهد. تضاد با مدل زبان دو طرفه .
V
AutoEncoder متغیر (VAE)
نوعی از AutoEncoder که از اختلاف بین ورودی ها و خروجی ها استفاده می کند تا نسخه های اصلاح شده ورودی ها را تولید کند. خودروهای متغیر برای AI تولیدی مفید هستند.
VAE ها بر اساس استنباط متنوع است: تکنیکی برای برآورد پارامترهای یک مدل احتمال.
دبلیو
کلمه جاسازی
نشان دادن هر کلمه در یک کلمه که در یک بردار تعبیه شده قرار دارد. یعنی نشان دادن هر کلمه به عنوان یک بردار از مقادیر نقطه شناور بین 0.0 تا 1.0. کلمات با معانی مشابه نسبت به کلمات با معانی مختلف ، بازنمایی های شبیه تر دارند. به عنوان مثال ، هویج ، کرفس و خیار همه نمایش های نسبتاً مشابهی دارند که این امر با بازنمایی هواپیما ، عینک آفتابی و خمیردندان بسیار متفاوت است.
ز
صفر شات
سریع که نمونه ای از نحوه پاسخگویی به مدل زبان بزرگ را ارائه نمی دهد. به عنوان مثال:
| بخش هایی از یک سریع | یادداشت ها |
|---|---|
| ارز رسمی کشور مشخص شده چیست؟ | سوالی که می خواهید LLM به آن پاسخ دهد. |
| هند: | پرس و جو واقعی |
مدل زبان بزرگ ممکن است با هر یک از موارد زیر پاسخ دهد:
- روپیه
- INR
- ₹
- روپیه هند
- روپیه
- روپیه هندی
همه پاسخ ها صحیح هستند ، اگرچه ممکن است یک قالب خاص را ترجیح دهید.
با اصطلاحات زیر مقایسه و کنتراست را با شرایط زیر مقایسه و کنتراست کنید: