Questa pagina contiene i termini del glossario per la valutazione della lingua. Per tutti i termini del glossario, fai clic qui.
A
Attention,
Meccanismo utilizzato in una rete neurale che indica l'importanza di una particolare parola o parte di una parola. L'attenzione si comprime la quantità di informazioni di cui un modello ha bisogno per prevedere il token/la parola successiva. Un tipico meccanismo di attenzione può essere costituito somma ponderata in un insieme di input, in cui la La ponderazione di ogni input viene calcolata da un'altra parte del neurali profonde.
Fai riferimento anche all'auto-attenzione e l'auto-attenzione multi-testa, che sono i componenti di base dei Transformer.
autoencoder
Un sistema che impara a estrarre le informazioni più importanti di testo. I codificatori automatici sono una combinazione di un encoder e decoder. I codificatori automatici si basano sul seguente processo in due passaggi:
- L'encoder mappa l'input a una dimensione (solitamente) con perdita di dati (intermedio).
- Il decoder crea una versione con perdita dell'input originale mappando dal formato inferiore all'originale formato di input.
Gli autoencoder vengono addestrati end-to-end facendo in modo che il decoder provi a ricostruisci l'input originale a partire dal formato intermedio dell'encoder il più vicino possibile. Poiché il formato intermedio è più piccolo (dimensioni inferiori) rispetto al formato originale, l'autoencoder viene forzato per capire quali informazioni nell'input sono essenziali e l'output non perfettamente identica all'input.
Ad esempio:
- Se i dati di input sono grafici, la copia non esatta sarà simile a la grafica originale, ma in qualche modo modificata. Forse la copia non esatta rimuove rumore dall'immagine originale o riempie alcuni pixel mancanti.
- Se i dati di input sono testo, un autoencoder genera un nuovo testo che imitano (ma non sono identiche) al testo originale.
Vedi anche Autoencoder variazionali.
modello autoregressivo
Un modello che deduce una previsione in base al proprio modello precedente per le previsioni. Ad esempio, i modelli linguistici autoregressivi prevedono la risposta token in base ai token previsti in precedenza. Tutte basate su Transformer I modelli linguistici di grandi dimensioni sono autoregressivi.
Al contrario, i modelli di immagine basati su GAN di solito non sono autoregressivi poiché generano un'immagine in un singolo progresso in avanti e non iterativamente passaggi. Tuttavia, alcuni modelli di generazione delle immagini sono autoregressivi in quanto generano un'immagine in passaggi.
B
sacchetto di parole
Una rappresentazione delle parole in una frase o in un passaggio, a prescindere dall'ordine. Ad esempio, il sacchetto di parole rappresenta tre frasi identiche:
- il cane salta
- fa saltare il cane
- cane salta
Ogni parola è mappata a un indice di un vettore sparso, dove il vettore ha un indice per ogni parola del vocabolario. Ad esempio: la frase il cane salta è mappata in un vettore di caratteristiche con valore diverso da zero ai tre indici corrispondenti alle parole the, dog e salti. Il valore diverso da zero può essere:
- Un 1 per indicare la presenza di una parola.
- Un conteggio del numero di volte in cui una parola compare nella borsa. Ad esempio: se la frase fosse il cane granata è un cane con la pelliccia granata, allora entrambi marrone rossiccio e cane sarebbero rappresentati come 2, mentre le altre parole essere rappresentato come 1.
- Un altro valore, come il logaritmo del conteggio del numero di volte in cui compare una parola nella borsa.
BERT (Bidirectional Encoder rappresentazioni dei trasformatori)
Un'architettura modello per la rappresentazione del testo. Un modello Il modello BERT può agire come parte di un modello più grande per la classificazione del testo ad altre attività ML.
BERT ha le seguenti caratteristiche:
- Utilizza l'architettura Transformer, per cui si basa sull'auto-attenzione.
- Utilizza la parte encoder del Transformer. Il compito dell'encoder consiste nel produrre buone rappresentazioni di testo, piuttosto che eseguire una specifica come la classificazione.
- È bidirezionale.
- Utilizza il mascheramento per dell'addestramento non supervisionato.
Le varianti di BERT includono:
di Gemini Advanced.Consulta il documento BERT Open Sourcing: Preaddestramento all'avanguardia per il linguaggio naturale Elaborazione per una panoramica di BERT.
bidirezionale
Termine utilizzato per descrivere un sistema che valuta il testo che precede e segue una sezione di testo target. Al contrario, un solo sistema unidirezionale valuta il testo che precede una sezione di testo di destinazione.
Ad esempio, considera un modello linguistico mascherato che deve determinare le probabilità per la parola o le parole che rappresentano la sottolineatura in la seguente domanda:
Cosa _____ con te?
Un modello linguistico unidirezionale dovrebbe basare solo le sue probabilità sul contesto fornito dalle parole "Che cos'è", "è" e "il". Al contrario, un modello linguistico bidirezionale potrebbe ricavare contesto anche da "con" e "tu", che possono aiutare il modello a generare previsioni migliori.
modello linguistico bidirezionale
Un modello linguistico che determina la probabilità che un un determinato token sia presente in una determinata posizione in un estratto di testo basato su il testo precedente e successivo.
bigram
Un N-gram in cui N=2.
BLEU (Bilingual Evaluation Understudy)
Un punteggio compreso tra 0,0 e 1,0 inclusi, che indica la qualità di una traduzione tra due lingue umane (ad esempio tra inglese e russo). BLEU un punteggio pari a 1,0 indica una traduzione perfetta; un punteggio BLEU pari a 0,0 indica una traduzione terribile.
C
modello linguistico causale
Sinonimo di modello linguistico unidirezionale.
Consulta il modello linguistico bidirezionale per i diversi approcci direzionali nella modellazione linguistica.
Chain-of-Thought Prompting
Una tecnica di prompt engineering che incoraggia un modello linguistico di grandi dimensioni (LLM) per spiegare la sua il ragionamento, passo dopo passo. Ad esempio, considera il seguente prompt: particolare attenzione alla seconda frase:
Quante forze g farebbe un conducente in un'auto che va da 0 a 60 miglia orarie in 7 secondi? Nella risposta, mostra tutti i calcoli pertinenti.
La risposta dell'LLM sarebbe probabilmente:
- Mostra una sequenza di formule di fisica, inserendo i valori 0, 60 e 7 in luoghi appropriati.
- Spiega perché ha scelto queste formule e il significato delle varie variabili.
La Chain-of-Thought Prompting obbliga l'LLM a eseguire tutti i calcoli, il che potrebbe portare a una risposta più corretta. Inoltre, la "catena di pensiero" consente all'utente di esaminare i passaggi dell'LLM per determinare se o meno la risposta abbia senso.
chat
I contenuti di un dialogo continuo con un sistema di ML, in genere modello linguistico di grandi dimensioni (LLM). L'interazione precedente in una chat (il testo digitato e il modo in cui il modello linguistico di grandi dimensioni ha risposto) diventa il contesto per le parti successive della chat.
Un chatbot è un'applicazione di un modello linguistico di grandi dimensioni (LLM).
confabulazione
Sinonimo di allucinazione.
Confabulazione è probabilmente un termine più preciso dal punto di vista tecnico dell'allucinazione. Tuttavia, l'allucinazione è diventata popolare all'inizio.
analisi del collegio elettorale
Dividere una frase in strutture grammaticali più piccole ("costituenti"). Una parte successiva del sistema ML, come comprensione del linguaggio naturale, è in grado di analizzare i costituenti più facilmente rispetto alla frase originale. Ad esempio: considera la seguente frase:
Il mio amico ha adottato due gatti.
Un parser del collegio elettorale può dividere questa frase nella seguente due costituenti:
- Il mio amico è una frase sostantivo.
- adopted two cats è una frase verbale.
Questi costituenti possono essere ulteriormente suddivisi in costituenti più piccoli. Ad esempio, la frase del verbo
due gatti adottati
potrebbero essere ulteriormente suddivisi in:
- adopted è un verbo.
- two cats è un'altra frase sostantivo.
incorporamento linguistico contestualizzato
Un incorporamento che si avvicina alla "comprensione" parole e frasi in modi impensabili dai madrelingua. Linguaggio contestualizzato gli incorporamenti sono in grado di comprendere sintassi, semantica e contesto complessi.
Considera ad esempio le rappresentazioni distribuite della parola inglese cow. Incorporamenti meno recenti ad esempio word2vec può rappresentare l'inglese parole in modo che la distanza nello spazio di incorporamento da mucca a toro è simile alla distanza tra pecora (femmina) a ariete (maschio di pecora) o da femmina a maschio. Linguaggio contestualizzato gli incorporamenti possono fare un passo oltre, riconoscendo che a volte gli anglofoni usare casualmente la parola mucca per indicare mucca o toro.
finestra contestuale
Il numero di token che un modello può elaborare in un determinato prompt. Più grande è la finestra contestuale, maggiori sono le informazioni il modello può utilizzare per fornire risposte coerenti e coerenti al prompt.
fiore in fiore
Una frase o una frase con un significato ambiguo. Le fioriture dei arresti anomali rappresentano un grave problema in naturali la comprensione delle lingue. Ad esempio, il titolo Nastro rosso regge un grattacielo è un perché un modello NLU potrebbe interpretare il titolo letteralmente o in senso figurato.
D
decodificatore
In generale, qualsiasi sistema ML che esegue la conversione da una rappresentazione interna a una rappresentazione più RAW, sparsa o esterna.
I decoder sono spesso un componente di un modello più grande, in cui vengono accoppiato con un encoder.
Nelle attività da sequenza a sequenza, un decoder inizia con lo stato interno generato dall'encoder per prevedere la risposta sequenza.
Fai riferimento a Transformer per la definizione di un decoder all'interno l'architettura Transformer.
riduzione del rumore
Un approccio comune all'apprendimento autonomo in cui:
La riduzione del rumore consente di apprendere da esempi non etichettati. Il set di dati originale funge da target o label e i dati rumorosi come input.
Alcuni modelli linguistici mascherati utilizzano la riduzione del rumore. come segue:
- Il rumore viene aggiunto artificialmente a una frase non etichettata mascherando alcune i token.
- Il modello cerca di prevedere i token originali.
richiesta diretta
Sinonimo di prompt zero-shot.
E
modifica distanza
Una misura della somiglianza tra due stringhe di testo. Nel machine learning, la modifica della distanza è utile perché è semplice ed è un modo efficace per confrontare due stringhe note per essere o per trovare stringhe simili a una determinata stringa.
Esistono diverse definizioni della distanza di modifica, ognuna con stringhe diverse operazioni. Ad esempio, Distanza Levenshtein considera il minor numero di operazioni di eliminazione, inserimento e sostituzione.
Ad esempio, la distanza di Levenshtein tra le parole "cuore" e "dardi" è 3 perché le seguenti 3 modifiche sono il minor numero di cambiamenti da trasformare una parola nell'altro:
- cuore → deart (sostituisci "h" con "d")
- deart → esercito (elimina "e")
- freccette → freccette (insert "s")
strato di incorporamento
Uno speciale strato nascosto che viene addestrato su una caratteristica categorica ad alta dimensionalità per apprenderanno gradualmente un vettore di incorporamento di dimensione inferiore. Un consente a una rete neurale di addestrare molto in modo efficiente rispetto all'addestramento della caratteristica categorica ad alta dimensionalità.
Ad esempio, al momento Earth supporta circa 73.000 specie di alberi. Supponiamo che
specie di albero è una caratteristica nel modello, quindi la classe
strato di input include un vettore one-hot 73.000
elementi.
Ad esempio, baobab potrebbe essere rappresentato in modo simile a questo:

Un array di 73.000 elementi è molto lungo. Se non aggiungi uno strato di incorporamento al modello, l'addestramento richiederà molto tempo a causa moltiplicando 72.999 zeri. Forse scegli lo strato di incorporamento da consistere di 12 dimensioni. Di conseguenza, lo strato di incorporamento apprenderà gradualmente un nuovo vettore di incorporamento per ogni specie di albero.
In alcune situazioni, l'hashing è un'alternativa ragionevole in uno strato di incorporamento.
spazio di incorporamento
Lo spazio vettoriale con dimensione D che parte da una dimensione uno spazio vettoriale. Idealmente, lo spazio di incorporamento contiene un struttura che restituisce risultati matematici significativi; ad esempio nello spazio di incorporamento ideale, addizione e sottrazione di incorporamenti può risolvere attività di analogia con le parole.
Il prodotto del punto di due incorporamenti è una misura della loro somiglianza.
vettore di incorporamento
In generale, un array di numeri in virgola mobile può essere preso da qualsiasi strato nascosto che descrive gli input per lo strato nascosto. Spesso, un vettore di incorporamento è l'array di numeri in virgola mobile addestrati in uno strato di incorporamento. Ad esempio, supponiamo che uno strato di incorporamento debba apprendere un vettore di incorporamento per ciascuna delle 73.000 specie di alberi sulla Terra. Forse seguente è il vettore di incorporamento per un baobab:

Un vettore di incorporamento non è un gruppo di numeri casuali. Uno strato di incorporamento determina questi valori attraverso l'addestramento, in modo simile al modo la rete neurale apprende altri pesi durante l'addestramento. Ogni elemento è una classificazione in base ad alcune caratteristiche di una specie di albero. Quale rappresenta la specie di alberi una caratteristica? È molto difficile per essere individuate dagli esseri umani.
La parte matematicamente notevole di un vettore di incorporamento è simile elementi contengono insiemi simili di numeri in virgola mobile. Ad esempio, simili le specie di alberi hanno un insieme più simile di numeri in virgola mobile specie di alberi diverse. Le sequoie e le sequoie sono specie di alberi correlate quindi avranno un insieme più simile di numeri in virgola mobile sequoie e palme da cocco. I numeri nel vettore di incorporamento cambia ogni volta che il modello viene riaddestrato, anche se il modello con input identico.
codificatore
In generale, qualsiasi sistema di ML che esegue la conversione da un ambiente non elaborato, sparso o in una rappresentazione più elaborata, più densa o interna.
I codificatori sono spesso un componente di un modello più grande, in cui vengono accoppiato con un decoder. Alcuni trasformatori encoder e decoder, sebbene altri Transformer utilizzino solo l'encoder o solo il decoder.
Alcuni sistemi utilizzano l'output dell'encoder come input di una classificazione di regressione lineare e una rete di regressione.
Nelle attività da sequenza a sequenza, un prende una sequenza di input e restituisce uno stato interno (un vettore). Quindi, decoder utilizza questo stato interno per prevedere la sequenza successiva.
Consulta Transformer per la definizione di un encoder in l'architettura Transformer.
F
Prompt few-shot
Un prompt che contiene più di un esempio (un "pochi") a dimostrare come il modello linguistico di grandi dimensioni dovrebbe rispondere. Ad esempio, il seguente prompt lungo contiene due esempi che mostrano come rispondere a una query a un modello linguistico di grandi dimensioni (LLM).
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| Francia: EUR | Un esempio. |
| Regno Unito: GBP | Un altro esempio. |
| India: | La query effettiva. |
Prompt few-shot generalmente produce risultati più desiderabili rispetto prompt zero-shot e prompt one-shot. Tuttavia, i prompt few-shot richiede un prompt più lungo.
Prompt few-shot: è una forma di apprendimento few-shot applicata all'apprendimento basato su prompt.
Violino
Una libreria di configurazione incentrata su Python che imposta le di funzioni e classi senza codice o infrastruttura invasivi. Nel caso di Pax e di altri codebase ML, queste funzioni e rappresentano modelli e addestramento iperparametri.
Violino presuppone che i codebase di machine learning siano generalmente suddivisi in:
- Codice libreria, che definisce livelli e ottimizzatori.
- Set di dati "glue" che chiama le librerie e collega tutti gli elementi tra loro.
Fiddle acquisisce la struttura della chiamata del codice glue in una sessione non valutata e può essere modificato.
messa a punto
Un secondo pass per l'addestramento specifico per un'attività, eseguito su modello preaddestrato per perfezionarne i parametri per un caso d'uso specifico. Ad esempio, l'intera sequenza di addestramento I modelli linguistici di grandi dimensioni sono i seguenti:
- Preaddestramento: addestra un modello linguistico di grandi dimensioni (LLM) su un ampio set di dati generale, ad esempio tutte le pagine in lingua inglese di Wikipedia.
- Ottimizzazione: addestra il modello preaddestrato per eseguire un'attività specifica, ad esempio per rispondere a domande mediche. Il perfezionamento implica tipicamente centinaia o migliaia di esempi incentrati su quell'attività specifica.
Come ulteriore esempio, l'intera sequenza di addestramento per un modello di immagine di grandi dimensioni è il seguente: che segue:
- Preaddestramento: addestra un modello di immagine di grandi dimensioni su un'immagine generale di grandi dimensioni come tutte le immagini in Wikimedia Commons.
- Ottimizzazione: addestra il modello preaddestrato per eseguire un'attività specifica, ad esempio generando immagini di orche.
Il perfezionamento può comportare una qualsiasi combinazione delle seguenti strategie:
- Modificando tutti i valori esistenti del modello preaddestrato parametri: Questa operazione è talvolta chiamata ottimizzazione completa.
- Modifica di solo alcuni dei parametri esistenti del modello preaddestrato (in genere, i livelli più vicini allo strato di output), mantenendo invariati gli altri parametri esistenti (di solito, gli strati più vicino al livello di input). Consulta ottimizzazione efficiente dei parametri.
- Aggiungere altri livelli, in genere sopra quelli esistenti più vicini livello di output.
Il perfezionamento è una forma di transfer learning. Di conseguenza, l'ottimizzazione potrebbe utilizzare una funzione di perdita diversa o un modello diverse da quelle usate per addestrare il modello preaddestrato. Ad esempio, potresti ottimizzare un modello di immagine di grandi dimensioni preaddestrato per produrre un modello di regressione che restituisce il numero di uccelli in un'immagine di input.
Confronta e contrapponi il perfezionamento con i seguenti termini:
Lino
Una piattaforma open source ad alte prestazioni libreria per deep learning basato su JAX. Il lino offre funzioni per l'addestramento delle reti neurali, come metodi per valutarne le prestazioni.
Flaxformer
Un Transformer open source raccolta, basato su Flax, progettato principalmente per l'elaborazione del linguaggio naturale ricerca multimodale.
G
AI generativa
Un campo trasformativo emergente senza definizione formale. Detto questo, la maggior parte degli esperti concorda sul fatto che i modelli di IA generativa creare ("generare") contenuti che rientrano in tutti i seguenti aspetti:
- complesso
- coerente
- originale
Ad esempio, un modello di IA generativa può creare sofisticate saggi o immagini.
Alcune tecnologie precedenti, tra cui gli LSTMs. e gli RNN, possono anche generare origini contenuti coerenti. Alcuni esperti considerano queste tecnologie precedenti come l'IA generativa, mentre altri ritengono che la vera IA generativa richieda più modelli di quello che le tecnologie precedenti erano in grado di produrre.
Confrontare con l'ML predittivo.
GPT (Generative Pre-training Transformer)
Una famiglia di componenti basati su Transformer modelli linguistici di grandi dimensioni (LLM) sviluppati da OpenAI.
Le varianti GPT possono essere applicate a diverse modalità, tra cui:
- Generazione di immagini (ad esempio, ImageGPT)
- la generazione da testo a immagine (ad esempio, DALL-E).
H
allucinazione
La produzione di output plausibili ma di fatto errati da parte di di IA generativa che sostiene di creare asserzione sul mondo reale. Ad esempio, un modello di IA generativa che afferma che Barack Obama sia morto nel 1865 è allucinante.
I
apprendimento contestuale
Sinonimo di prompt few-shot.
L
LaMDA (Language Model for Dialogue Applications)
Un modello basato su Transformer modello linguistico di grandi dimensioni (LLM) sviluppato da Google, addestrato su un ampio set di dati di dialoghi in grado di generare risposte conversazionali realistiche.
LaMDA: la nostra conversazione innovativa tecnologia fornisce una panoramica.
modello linguistico
Un modello che stima la probabilità di un token o sequenza di token che si verificano in una sequenza più lunga di token.
modello linguistico di grandi dimensioni
Un termine informale senza definizione rigorosa che di solito indica una modello linguistico che ha un elevato numero parametri. Alcuni LLM contengono oltre 100 miliardi di parametri.
spazio latente
Sinonimo di spazio di incorporamento.
LLM
Abbreviazione di Large Language Model.
LoRA
Abbreviazione di Low-Rank Adapter.
Adattabilità Low-Rank (LoRA)
Un algoritmo per eseguire ottimizzazione efficiente dei parametri ottimizza solo un sottoinsieme di Parametri del modello linguistico di grandi dimensioni (LLM). LoRA offre i seguenti vantaggi:
- Perfeziona più rapidamente rispetto alle tecniche che richiedono l'ottimizzazione di tutte le fasi parametri.
- Riduce il costo di calcolo dell'inferenza nel perfezionato il modello.
Un modello ottimizzato con LoRA mantiene o migliora la qualità delle sue previsioni.
LoRA consente più versioni specializzate di un modello.
M
modello linguistico mascherato
Un modello linguistico che prevede la probabilità di di token candidati per riempire gli spazi vuoti in sequenza. Ad esempio, un il modello linguistico mascherato può calcolare le probabilità delle parole candidati per sostituire il sottolineato nella seguente frase:
Il ____ con il cappello è tornato.
La letteratura in genere utilizza la stringa "MASK" anziché una sottolineatura. Ad esempio:
La "MASCHERA" col cappello è tornato.
La maggior parte dei moderni modelli linguistici con mascheramento è bidirezionale.
meta-learning
Un sottoinsieme del machine learning che rileva o migliora un algoritmo di apprendimento. Un sistema di meta-apprendimento può anche mirare ad addestrare un modello per apprendere rapidamente in base a una piccola quantità di dati o all'esperienza acquisita nelle attività precedenti. Gli algoritmi di meta-learning generalmente tentano di ottenere i seguenti risultati:
- Migliorare o apprendere funzionalità progettate manualmente (come un inizializzatore o ottimizzatore).
- Aumenta l'efficienza nei dati e nel calcolo.
- Migliorare la generalizzazione.
Il meta-learning è correlato all'apprendimento few-shot.
modalità
Una categoria di dati di alto livello. Ad esempio, numeri, testo, immagini, video e esistono cinque modalità diverse.
parallelismo del modello
Un modo di scalare l'addestramento o l'inferenza che pone parti diverse di una model su dispositivi diversi. Parallelismo del modello consente modelli troppo grandi per essere utilizzati in un solo dispositivo.
Per implementare il parallelismo del modello, un sistema in genere svolge le seguenti operazioni:
- Shard (divide) il modello in parti più piccole.
- Distribuisce l'addestramento delle parti più piccole su più processori. Ogni processore addestra la propria parte del modello.
- Combina i risultati per creare un singolo modello.
Il parallelismo del modello rallenta l'addestramento.
Vedi anche parallelismo dei dati.
auto-attenzione multi-testa
Un'estensione dell'auto-attenzione che applica le meccanismo di auto-attenzione più volte per ogni posizione nella sequenza di input.
I Transformer hanno introdotto l'auto-attenzione multi-head.
modello multimodale
Un modello i cui input e/o output includono più di una modalità Ad esempio, consideriamo un modello che prende in considerazione immagine e una didascalia di testo (due modalità) come features e restituisce un punteggio che indica quanto sia appropriata la didascalia di testo per l'immagine. Pertanto, gli input di questo modello sono multimodali e l'output è unimodale.
N
comprensione del linguaggio naturale
Stabilire le intenzioni di un utente in base a ciò che ha digitato o detto. Ad esempio, un motore di ricerca utilizza la comprensione del linguaggio naturale per determinare cosa sta cercando l'utente in base a ciò che ha digitato o detto.
N-grammi
Una sequenza ordinata di N parole. Ad esempio, davvero folle è un 2 grammi. Poiché l'ordine è pertinente, massimamente sono 2 grammi diverso da davvero folle.
| N | Nomi di questo tipo di n-grammi | Esempi |
|---|---|---|
| 2 | bigram o 2 grammi | andare, andare, pranzare, cena |
| 3 | trigram o 3 grammi | ho mangiato troppo, tre topi ciechi, le campane |
| 4 | 4 grammi | passeggiata nel parco, polvere al vento, il ragazzo mangiava lenticchie |
Molte comprensione del linguaggio naturale i modelli si basano su n-grammi per prevedere la parola successiva che l'utente digiterà o pronunciare. Ad esempio, supponiamo che un utente abbia digitato tre ciechi. Un modello NLU basato su trigrammi probabilmente prevede che l'utente digiterà poi mopi.
Confrontare n-grammi con sacchetto di parole, che sono insiemi di parole non ordinate.
NLU
Abbreviazione di lingua naturale la comprensione.
O
Prompt one-shot
Un prompt contenente un esempio che mostra come Il modello linguistico di grandi dimensioni (LLM) deve rispondere. Ad esempio: Il seguente prompt contiene un esempio che mostra un modello linguistico di grandi dimensioni dovrebbe rispondere a una query.
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| Francia: EUR | Un esempio. |
| India: | La query effettiva. |
Confronta e contrapponi i prompt one-shot con i seguenti termini:
P
ottimizzazione efficiente dei parametri
Un insieme di tecniche per mettere a punto un LLM modello linguistico preaddestrato (PLM) in modo più efficiente rispetto alla completa ottimizzazione. Efficienza dei parametri l'ottimizzazione in genere perfeziona molti meno parametri rispetto alla configurazione completa perfezionato, ma generalmente produce un modello linguistico di grandi dimensioni (LLM) che esegue nonché (o quasi) come un modello linguistico di grandi dimensioni (LLM) basato dei modelli.
Confronta e contrapporre l'ottimizzazione efficiente dei parametri con:
L'ottimizzazione efficiente dei parametri è anche nota come ottimizzazione efficiente dei parametri.
pipeline
Una forma di parallelismo del modello in cui l'input del modello l'elaborazione è divisa in fasi consecutive e ogni fase viene eseguita su un altro dispositivo. Mentre una fase elabora un batch, la precedente possono lavorare sul batch successivo.
Vedi anche addestramento in fasi.
PLM
Abbreviazione di modello linguistico preaddestrato.
codifica posizionale
Una tecnica per aggiungere informazioni sulla posizione di un token in una sequenza per dell'incorporamento del token. I modelli Transformer utilizzano valori posizionali per comprendere meglio la relazione tra le diverse parti sequenza.
Una comune implementazione della codifica posizionale utilizza una funzione sinusoidale. (Nello specifico, la frequenza e l'ampiezza della funzione sinusoidale sono determinato dalla posizione del token nella sequenza). Questa tecnica consente a un modello Transformer di imparare a essere prese in considerazione sequenza in base alla loro posizione.
modello preaddestrato
Modelli o componenti del modello (come vettore di incorporamento) che sono stati già addestrati. A volte, inserirai i vettori di incorporamento preaddestrati in un rete neurale. Altre volte, il modello addestrerà gli stessi vettori di incorporamento, invece di affidarsi agli incorporamenti preaddestrati.
Il termine modello linguistico preaddestrato si riferisce a una Il modello linguistico di grandi dimensioni (LLM) che ha superato preaddestramento.
preaddestramento
Addestramento iniziale di un modello su un set di dati di grandi dimensioni. Alcuni modelli preaddestrati sono goffi giganti e solitamente devono essere perfezionati con un addestramento aggiuntivo. Ad esempio, gli esperti di ML potrebbero preaddestrare un modello linguistico di grandi dimensioni (LLM) su un ampio set di dati di testo, come tutte le pagine in inglese di Wikipedia. Dopo l'addestramento, il modello risultante potrebbe essere ulteriormente perfezionato tramite una delle seguenti tecniche:
- distillazione
- perfezionamento
- ottimizzazione delle istruzioni
- ottimizzazione efficiente dei parametri
- ottimizzazione dei prompt
richiesta
Qualsiasi testo inserito come input in un modello linguistico di grandi dimensioni (LLM) condizionare il modello affinché si comporti in un certo modo. I prompt possono essere brevi a frase o arbitrariamente lunga (ad esempio, l'intero testo di un romanzo). Prompt rientrano in più categorie, incluse quelle indicate nella seguente tabella:
| Categoria prompt | Esempio | Note |
|---|---|---|
| Domanda | A che velocità può volare un piccione? | |
| Istruzione | Scrivi una poesia divertente sull'arbitraggio. | Un prompt che chiede al modello linguistico di grandi dimensioni (LLM) di fare qualcosa. |
| Esempio | Traduci il codice Markdown in HTML. Ad esempio:
Markdown: * voce elenco HTML: <ul> <li>elemento dell'elenco</li> </ul> |
La prima frase di questo prompt di esempio è un'istruzione. Il resto del prompt è l'esempio. |
| Ruolo | Spiegare perché la discesa del gradiente viene utilizzata nell'addestramento del machine learning per un dottorato in fisica. | La prima parte della frase è un'istruzione; la frase "a un dottorato di ricerca in fisica" è la parte relativa al ruolo. |
| Input parziale per il completamento del modello | Il Primo Ministro del Regno Unito vive a | Un prompt di input parziale può terminare bruscamente (come fa questo esempio) o terminare con un trattino basso. |
Un modello di IA generativa può rispondere a un prompt con testo, codice, immagini, incorporamenti, video... praticamente qualsiasi cosa.
apprendimento basato su prompt
Una capacità di determinati modelli che consente loro di adattarsi il loro comportamento in risposta a un input di testo arbitrario (messaggi). In un tipico paradigma di apprendimento basato su prompt, Il modello linguistico di grandi dimensioni (LLM) risponde a un prompt generando testo. Ad esempio, supponiamo che un utente inserisca la seguente richiesta:
Riassumi la terza legge della moto di Newton.
Un modello in grado di apprendere basato su prompt non è addestrato specificamente per rispondere il prompt precedente. Piuttosto, il modello "sa" molte curiosità sulla fisica, molto sulle regole generali del linguaggio e molto su ciò che costituisce risposte utili. Queste informazioni sono sufficienti per offrire (si spera) utili risposta. Feedback umano aggiuntivo ("La risposta era troppo complicata" oppure "Cos'è una reazione?") consente ad alcuni sistemi di apprendimento basato su prompt di migliorare l'utilità delle risposte.
progettazione dei prompt
Sinonimo di prompt engineering.
ingegneria del prompt
L'arte di creare prompt che suscitano le risposte desiderate da un modello linguistico di grandi dimensioni. Gli esseri umani eseguono il prompt con il feature engineering. Scrivere prompt ben strutturati è una parte essenziale per garantire risposte utili da un modello linguistico di grandi dimensioni. La progettazione del prompt dipende molti fattori, tra cui:
- Il set di dati utilizzato per preaddestrare ed eventualmente mettere a punto il modello LLM.
- La temperatura e altri parametri di decodifica che utilizzato dal modello per generare risposte.
Consulta Introduzione alla progettazione dei prompt per ulteriori dettagli su come scrivere prompt utili.
progettazione dei prompt è un sinonimo di prompt engineering.
ottimizzazione dei prompt
Un meccanismo di ottimizzazione efficiente dei parametri che impara un "prefisso" che il sistema antepone al prompt effettiva.
Una variante dell'ottimizzazione dei prompt, a volte chiamata ottimizzazione del prefisso, è anteponi il prefisso a ogni livello. Al contrario, la maggior parte dell'ottimizzazione dei prompt aggiunge un prefisso al livello di input.
R
prompt di ruolo
Una parte facoltativa di un prompt che identifica un pubblico di destinazione per la risposta di un modello di IA generativa. Senza un ruolo , un modello linguistico di grandi dimensioni (LLM) fornisce una risposta che può o non può essere utile per la persona che pone le domande. Con un prompt di ruolo, un modello modello può rispondere in modo più appropriato e utile per un a un pubblico di destinazione specifico. Ad esempio, la parte del prompt del ruolo I prompt sono in grassetto:
- Riassumi questo articolo per un dottorato di ricerca in economia.
- Descrivi come funzionano le maree per un bambino di dieci anni.
- Spiegare la crisi finanziaria del 2008. Parla come a un bambino piccolo, o un golden retriever.
S
auto-attenzione (detto anche livello di auto-attenzione)
Uno strato della rete neurale che trasforma una sequenza di incorporamenti (ad esempio, incorporamenti token) in un'altra sequenza di incorporamenti. Ogni incorporamento nella sequenza di output costruiti integrando le informazioni dagli elementi della sequenza di input attraverso un meccanismo di attenzione.
La parte relativa al sé dell'auto-attenzione si riferisce alla sequenza che segue piuttosto che in un altro contesto. L'auto-attenzione è uno dei i componenti di base per i trasformatori e utilizza la ricerca nel dizionario come "query", "chiave" e "valore".
Uno strato di auto-attenzione inizia con una sequenza di rappresentazioni di input, una per ogni parola. La rappresentazione di input per una parola può essere una semplice incorporamento. Per ogni parola in una sequenza di input, la rete valuta la pertinenza della parola per ogni elemento nell'intera sequenza di parole. I punteggi di pertinenza determinano in che misura la rappresentazione finale della parola incorpora le rappresentazioni di altre parole.
Ad esempio, considera la seguente frase:
L'animale non ha attraversato la strada perché era troppo stanco.
L'illustrazione seguente (da Transformer: una nuova architettura di rete neurale per il linguaggio Comprensione) mostra lo schema di attenzione di uno strato di auto-attenzione per il pronome it, con l'oscurità di ogni riga, che indica quanto ogni parola contribuisca alla rappresentazione:

Il livello di auto-attenzione evidenzia le parole pertinenti. In questo caso, lo strato di attenzione ha imparato a evidenziare le parole che potrebbe facendo riferimento, assegnando il peso più alto ad animal.
Per una sequenza di n token, l'auto-attenzione trasforma una sequenza di incorporamenti n volte separate, una in ciascuna posizione nella sequenza.
Fai riferimento anche alle sezioni Attenzione e auto-attenzione multi-testa.
analisi del sentiment
L'utilizzo di algoritmi statistici o di machine learning per determinare la un atteggiamento generale, positivo o negativo, nei confronti di un servizio, un prodotto, organizzazione o argomento. Ad esempio, utilizzando comprensione del linguaggio naturale, un algoritmo potrebbe eseguire l'analisi del sentiment sul feedback testuale da un corso universitario per determinare il grado di specializzazione degli studenti in generale gli è piaciuto o non mi è piaciuto il corso.
attività da sequenza a sequenza
Un'attività che converte una sequenza di input di token in un output una sequenza di token. Ad esempio, due tipi popolari di sequenza sono:
- Traduttori:
- Sequenza di input di esempio: "Ti amo".
- Esempio di sequenza di output: "Je t'aime".
- Risposta alle domande:
- Sequenza di input di esempio: "Devo avere la mia auto a New York?"
- Esempio di sequenza di output: "No. Per favore, porta l'auto a casa".
skip-gram
Un elemento n-gram che può omettere (o "saltare") parole dall'originale contesto, il che significa che le N parole potrebbero non essere state originariamente adiacenti. Altro precisamente, un "k-skip-n-gram" è un n-grammo per cui possono esistere fino a k parole saltate.
Ad esempio, "volpe volpe marrone" ha i seguenti 2 grammi possibili:
- "l'accelerato"
- "marrone rapido"
- "volpe marrone"
A "1-salto-2 grammi" è costituito da un paio di parole separate da massimo 1 parola. Pertanto, "l'uomo delle volpi" ha i seguenti 1 o 2 grammi:
- "marrone"
- "Fast Volpe"
Inoltre, tutti i 2 grammi sono anche 1 o 2 grammi, in quanto meno può essere saltata più di una parola.
I grammi ignorabili sono utili per comprendere meglio il contesto circostante di una parola. Nell'esempio, "volpe" è stato direttamente associato a "rapido" nel set 1-saltare-2 grammi, ma non nel set di 2 grammi.
Salta grammi per addestrare di incorporamento delle parole.
ottimizzazione dei prompt flessibili
Una tecnica per ottimizzare un modello linguistico di grandi dimensioni (LLM) per un'attività specifica, senza consumare risorse perfezionamenti. Invece di riaddestrare tutti i Ponderazioni nel modello, ottimizzazione dei prompt soft regola automaticamente un prompt per raggiungere lo stesso obiettivo.
Data un prompt testuale, l'ottimizzazione dei prompt soft in genere aggiunge ulteriori incorporamenti di token al prompt e utilizza la retropropagazione dell'errore per ottimizzare l'input.
Un "complesso" contiene token effettivi anziché incorporamenti di token.
caratteristica sparsa
Una caratteristica i cui valori sono prevalentemente zero o vuoti. Ad esempio, una caratteristica contenente un singolo valore 1 e un milione di valori 0 è sparsa. Al contrario, una caratteristica densa ha valori che non sono prevalentemente zero o vuoti.
Nel machine learning, un numero sorprendente di caratteristiche sono caratteristiche sparse. Le caratteristiche categoriche sono di solito caratteristiche sparse. Ad esempio, delle 300 possibili specie di alberi in una foresta, un singolo esempio potrebbe identificare solo un albero di acero. O dei milioni di utenti di possibili video in una raccolta video, un singolo esempio potrebbe identificare semplicemente "Casablanca".
In un modello, di solito rappresenti le caratteristiche sparse con codifica one-hot. Se la codifica one-hot è di grandi dimensioni, puoi inserire uno strato di incorporamento sopra lo codifica one-hot per una maggiore efficienza.
rappresentazione sparsa
Memorizzare solo le posizioni di elementi diversi da zero in una caratteristica sparsa.
Ad esempio, supponiamo che una caratteristica categorica denominata species identifichi il 36
specie di alberi di una determinata foresta. Supponiamo inoltre che ogni
example identifica solo una singola specie.
Potresti utilizzare un vettore one-hot per rappresentare le specie di alberi in ogni esempio.
Un vettore one-hot conterrebbe un singolo 1 (per rappresentare
la particolare specie di alberi nell'esempio) e 35 0 (per rappresentare le
35 specie di alberi che non sono presenti nell'esempio). Quindi, la rappresentazione one-hot
di maple potrebbe avere il seguente aspetto:

In alternativa, la rappresentazione sparsa dovrebbe semplicemente identificare la posizione del
specie particolari. Se maple è in posizione 24, allora la rappresentazione sparsa
di maple sarebbe:
24
Nota che la rappresentazione sparsa è molto più compatta della una rappresentazione visiva.
Fai clic sull'icona per visualizzare un esempio leggermente più complesso.
Supponiamo che ogni esempio nel modello debba rappresentare le parole, ma non l'ordine di queste parole, in una frase in inglese. L'inglese è composto da circa 170.000 parole, quindi l'inglese è una definizione con circa 170.000 elementi. La maggior parte delle frasi inglesi una frazione molto ridotta delle 170.000 parole, quindi l'insieme di parole in un singolo esempio sarà quasi certamente costituito da dati sparsi.
Prendi in esame la seguente frase:
My dog is a great dog
Potresti utilizzare una variante del vettore one-hot per rappresentare le parole in questo una frase. In questa variante, più celle del vettore possono contenere un valore diverso da zero. Inoltre, in questa variante, una cella può contenere un numero intero diverso da uno. Anche se le parole "mio", "è", "a" e "fantastico" vengono visualizzati solo una volta nella frase, la parola "cane" appare due volte. Utilizzando questa variante di vettori one-hot per rappresentare le parole in questa frase produce quanto segue: Vettore con 170.000 elementi:

Una rappresentazione sparsa della stessa frase sarebbe semplicemente:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
addestramento graduale
Una tattica per addestrare un modello in una sequenza di fasi discrete. L'obiettivo può essere per accelerare il processo di addestramento o per ottenere una migliore qualità del modello.
Di seguito è riportata un'illustrazione dell'approccio di impilamento progressivo:
- La fase 1 contiene 3 strati nascosti, la fase 2 contiene 6 strati nascosti e la fase 3 contiene 12 strati nascosti.
- La Fase 2 inizia l'addestramento con i pesi appresi nei 3 strati nascosti. della fase 1. La Fase 3 inizia l'addestramento con i pesi appresi nel 6 gli strati nascosti della Fase 2.
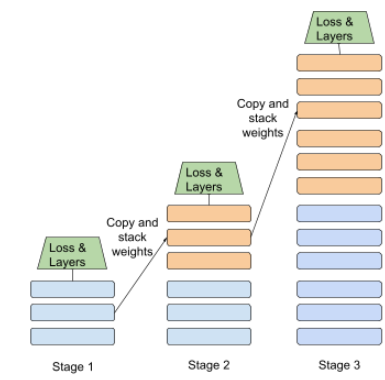
Vedi anche pipelining.
token della sottoparola
Nei modelli linguistici, si tratta di un token sottostringa di una parola, che potrebbe essere l'intera parola.
Ad esempio, una parola come "itemize" potrebbe essere suddiviso in diversi pezzi, "item" (una parola radice) e "ize" (un suffisso), ognuno dei quali è rappresentato da una propria di accesso. Suddividere le parole non comuni in parti simili, denominate sottoparole, consente linguistici di grandi dimensioni per operare sulle parti costitutive più comuni della parola, come prefissi e suffissi.
Al contrario, parole comuni come "andare" potrebbero non essere suddivisi e rappresentati da un singolo token.
T
T5
Un modello di transfer learning da testo a testo introdotto da L'IA di Google nel 2020. T5 è un modello encoder-decoder, basato sul Transformer, addestrata su un modello del set di dati. È efficace in una varietà di attività di elaborazione del linguaggio naturale, ad esempio generando testi, tradurre lingue e rispondere a domande in in modo colloquiale.
T5 prende il nome dalle cinque "T" in "Text-to-Text Transfer Transformer".
T5X
Un framework di machine learning open source progettato per creare e addestrare l'elaborazione del linguaggio naturale su larga scala (NLP). T5 è implementato sul codebase T5X (che basata su JAX e Flax).
temperatura
Un iperparametro che controlla il grado di casualità dell'output di un modello. Le temperature più alte generano un output più casuale, mentre le temperature più basse si traducono in un output meno casuale.
La scelta della temperatura migliore dipende dall'applicazione specifica e le proprietà preferite dell'output del modello. Ad esempio, probabilmente la temperatura si alzerà durante la creazione di un'applicazione genera risultati creativi. Al contrario, probabilmente abbasseresti la temperatura quando si crea un modello che classifica immagini o testo al fine di migliorare l'accuratezza e la coerenza del modello.
La temperatura viene spesso utilizzata con softmax.
intervallo di testo
L'intervallo di indice dell'array associato a una sottosezione specifica di una stringa di testo.
Ad esempio, la parola good nella stringa Python s="Be good now" occupa
l'intervallo di testo è compreso tra 3 e 6.
token
In un modello linguistico, l'unità atomica del modello è l'addestramento e l'elaborazione delle previsioni. Un token è tipicamente uno dei seguenti:
- una parola, ad esempio la frase "i cani come i gatti" è composto da tre parole token: "cani", "mi piace" e "gatti".
- un carattere, ad esempio la frase "pesci bicicletta" è composto da nove di caratteri. Tieni presente che lo spazio vuoto viene conteggiato come uno dei token.
- sottoparole in cui una singola parola può essere un singolo token o più token. Una sottoparola è composta da una parola radice, un prefisso o un suffisso. Ad esempio: un modello linguistico che utilizza sottoparole come token potrebbe visualizzare la parola "cani" come due token (la parola radice "cane" e il suffisso plurale "s"). Uguale un modello linguistico potrebbe visualizzare la singola parola "più alta" come due sottoparole (il parola principale "alto" e il suffisso "er").
In domini esterni ai modelli linguistici, i token possono rappresentare altri tipi di unità atomiche. Ad esempio, nella visione artificiale, un token potrebbe essere un sottoinsieme di un'immagine.
Transformer
Un'architettura di rete neurale sviluppata da Google che fa affidamento su meccanismi di auto-attenzione per trasformare sequenza di incorporamenti di input in una sequenza di output senza fare affidamento su convoluzioni o reti neurali ricorrenti. Un Transformer può essere vista come uno stack di strati di auto-attenzione.
Un Transformer può includere uno qualsiasi dei seguenti elementi:
Un encoder trasforma una sequenza di incorporamenti in una nuova sequenza di della stessa lunghezza. Un encoder include N strati identici, ognuno dei quali contiene due e i sottolivelli. Questi due sottolivelli vengono applicati in ciascuna posizione dell'input sequenza di incorporamento, trasformando ogni elemento della sequenza in un nuovo incorporamento. Il primo livello secondario dell'encoder aggrega informazioni da una sequenza di input. Il secondo sottolivello dell'encoder trasforma i dati aggregati le informazioni in un incorporamento di output.
Un decoder trasforma una sequenza di incorporamenti di input in una sequenza di incorporamenti di output, possibilmente con una lunghezza diversa. Un decoder include anche N strati identici con tre sottostrati, due dei quali sono simili nei sottolivelli dell'encoder. Il terzo sottolivello del decoder prende l'output del dell'encoder e applica il meccanismo di auto-attenzione raccogliere informazioni al suo interno.
Il blog post Transformer: A Novel Neural Network Architecture for Language Comprensione offre un'ottima introduzione ai Transformer.
trigramma
Un N-gram in cui N=3.
U
unidirezionale
Un sistema che valuta solo il testo che precede una sezione di testo target. Al contrario, un sistema bidirezionale valuta sia testo che precede e segue una sezione di testo di destinazione. Per ulteriori dettagli, consulta la sezione bidirezionale.
modello linguistico unidirezionale
Un modello linguistico che basa le sue probabilità solo sulla token visualizzati prima, non dopo dei token di destinazione. Confrontare con il modello linguistico bidirezionale.
V
autoencoder variazionale (VAE)
Un tipo di autoencoder che sfrutta la discrepanza tra input e output per generare versioni modificate degli input. Gli autoencoder variazionali sono utili per l'IA generativa.
Gli VAE si basano sull'inferenza variazionale: una tecnica per stimare il valore parametri di un modello di probabilità.
M
incorporamento di parole
Rappresentare ogni parola in un insieme di parole all'interno di un vettore di incorporamento; cioè rappresentare ogni parola un vettore di valori in virgola mobile compresi tra 0,0 e 1,0. Parole con simili significati hanno rappresentazioni più simili delle parole con significati diversi. Ad esempio, carote, sedano e cetrioli avrebbero avuto un rendimento relativamente rappresentazioni simili, che sarebbero molto diverse dalle rappresentazioni come aereo, occhiali da sole e dentifricio.
Z
Prompt zero-shot
Un prompt che non fornisce un esempio di come vuoi il modello linguistico di grandi dimensioni (LLM). Ad esempio:
| Parti di un prompt | Note |
|---|---|
| Qual è la valuta ufficiale del paese specificato? | La domanda a cui vuoi che l'LLM risponda. |
| India: | La query effettiva. |
Il modello linguistico di grandi dimensioni (LLM) potrebbe rispondere con uno dei seguenti elementi:
- Rupia
- INR
- ₹
- Rupia indiana
- La rupia
- Rupia indiana
Tutte le risposte sono corrette, anche se potresti preferire un formato particolare.
Confronta e contrapponi i prompt zero-shot con i seguenti termini: